加载
如何利用索引和主存储,是一种两难的选择。
- 选择不使用索引,只使用主存储:除非查询的字段就是主存储的排序字段,否则就需要顺序扫描整个主存储。
- 选择使用索引,然后用找到的 row id 去主存储加载数据:这样会导致很多碎片化的随机读操作。
没有所谓完美的解决方案。MySQL 支持索引,一般索引检索出来的行数也就是在 1~100 条之间。如果索引检索出来很多行,很有可能 MySQL 会选择不使用索引而直接扫描主存储,这就是因为用 row id 去主存储里读取行的内容是碎片化的随机读操作,这在普通磁盘上很慢。
Opentsdb 是另外一个极端,它完全没有索引,只有主存储。使用 Opentsdb 可以按照主存储的排序顺序快速地扫描很多条记录。但是访问的不是按主存储的排序顺序仍然要面对随机读的问题。
Elasticsearch/Lucene 的解决办法是让主存储的随机读操作变得很快,从而可以充分利用索引,而不用惧怕从主存储里随机读加载几百万行带来的代价。
Opentsdb 的弱点
Opentsdb 没有索引,主存储是 Hbase。所有的数据点按照时间顺序排列存储在 Hbase 中。Hbase 是一种支持排序的存储引擎,其排序的方式是根据每个 row 的 rowkey(就是关系数据库里的主键的概念)。MySQL 存储时间序列的最佳实践是利用 MySQL 的 Innodb 的 clustered index 特性,使用它去模仿类似 Hbase 按 rowkey 排序的效果。所以 Opentsdb 的弱点也基本适用于 MySQL。Opentsdb 的 rowkey 的设计大致如下:
[metric_name][timestamp][tags]
举例而言:
Proc.load_avg.1m 12:05:00 ip=10.0.0.1
Proc.load_avg.1m 12:05:00 ip=10.0.0.2
Proc.load_avg.1m 12:05:01 ip=10.0.0.1
Proc.load_avg.1m 12:05:01 ip=10.0.0.2
Proc.load_avg.5m 12:05:00 ip=10.0.0.1
Proc.load_avg:5m 12:05:00 ip=10.0.0.2
也就是行是先按照 metric_name 排序,再按照 timestamp 排序,再按照 tags 来排序。
对于这样的 rowkey 设计,获取一个 metric 在一个时间范围内的所有数据是很快的,比如 Proc.load_avg.1m 在 12:05 到 12:10 之间的所有数据。先找到 Proc.load_avg.1m 12:05:00 的行号,然后按顺序扫描就可以了。
但是以下两种情况就麻烦了。
- 获取 12:05 到 12:10 所有 Proc.load_avg.* 的数据,如果预先知道所有的 metric name 包括 Proc.load_avg.1m,Proc.load_avg.5m,Proc.load_avg.15m。这样会导致很多的随机读。如果不预先知道所有的 metric name,就无法知道 Proc.load_avg.* 代表了什么。
- 获取指定 ip 的数据。因为 ip 是做为 tags 保存的。即便是访问一个 ip 的数据,也要把所有其他的 ip 数据读取出来再过滤掉。如果 ip 总数有十多万个,那么查询的效率也会非常低。为了让这样的查询变得更快,需要把 ip 编码到 metric_name 里去。比如 ip.10.0.0.1.Proc.load_avg.1m 这样。
所以结论是,不用索引是不行的。如果希望支持任意条件的组合查询,只有主存储的排序是无法对所有查询条件进行优化的。但是如果查询条件是固定的一种,那么可以像 Opentsdb 这样只有一个主存储,做针对性的优化。
DocValues 为什么快?
DocValues 是一种按列组织的存储格式,这种存储方式降低了随机读的成本。传统的按行存储是这样的:

1 和 2 代表的是 docid。颜色代表的是不同的字段。
改成按列存储是这样的:

按列存储的话会把一个文件分成多个文件,每个列一个。对于每个文件,都是按照 docid 排序的。这样一来,只要知道 docid,就可以计算出这个 docid 在这个文件里的偏移量。也就是对于每个 docid 需要一次随机读操作。
那么这种排列是如何让随机读更快的呢?秘密在于 Lucene 底层读取文件的方式是基于 memory mapped byte buffer 的,也就是 mmap。这种文件访问的方式是由操作系统去缓存这个文件到内存里。这样在内存足够的情况下,访问文件就相当于访问内存。那么随机读操作也就不再是磁盘操作了,而是对内存的随机读。
那么为什么按行存储不能用 mmap 的方式呢?因为按行存储的方式一个文件里包含了很多列的数据,这个文件尺寸往往很大,超过了操作系统的文件缓存的大小。而按列存储的方式把不同列分成了很多文件,可以只缓存用到的那些列,而不让很少使用的列数据浪费内存。
按列存储之后,一个列的数据和前面的 posting list 就差不多了。很多应用在 posting list 上的压缩技术也可以应用到 DocValues 上。这不但减少了文件尺寸,而且提高数据加载的速度。因为我们知道从磁盘到内存的带宽是很小的,普通磁盘也就每秒 100MB 的读速度。利用压缩,我们可以把数据以压缩的方式读取出来,然后在内存里再进行解压,从而获得比读取原始数据更高的效率。
如果内存不够是不是会使得随机读的速度变慢?肯定会的。但是 mmap 是操作系统实现的 API,其内部有预读取机制。如果读取 offset 为 100 的文件位置,默认会把后面 16k 的文件内容都预读取出来都缓存在内存里。因为 DocValues 是只读,而且顺序排序存储的。相比 b-tree 等存储结构,在磁盘上没有空洞和碎片。而随机读的时候也是按照 DocId 排序的。所以如果读取的 DocId 是紧密相连的,实际上也相当于把随机读变成了顺序读了。Random_read(100), Random_read(101), Random_read(102) 就相当于 Scan(100~102) 了。
分布式计算
分布式聚合如何做得快
Elasticsearch/Lucene 从最底层就支持数据分片,查询的时候可以自动把不同分片的查询结果合并起来。Elasticsearch 的 document 都有一个 uid,默认策略是按照 uid 的 hash 把文档进行分片。
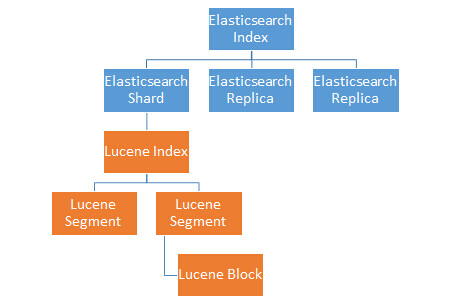
一个 Elasticsearch Index 相当于一个 MySQL 里的表,不同 Index 的数据是物理上隔离开来的。Elasticsearch 的 Index 会分成多个 Shard 存储,一部分 Shard 是 Replica 备份。一个 Shard 是一份本地的存储(一个本地磁盘上的目录),也就是一个 Lucene 的 Index。不同的 Shard 可能会被分配到不同的主机节点上。一个 Lucene Index 会存储很多的 doc,为了好管理,Lucene 把 Index 再拆成了 Segment 存储(子目录)。Segment 内的 doc 数量上限是 1 的 31 次方,这样 doc id 就只需要一个 int 就可以存储。Segment 对应了一些列文件存储索引(倒排表等)和主存储(DocValues 等),这些文件内部又分为小的 Block 进行压缩。
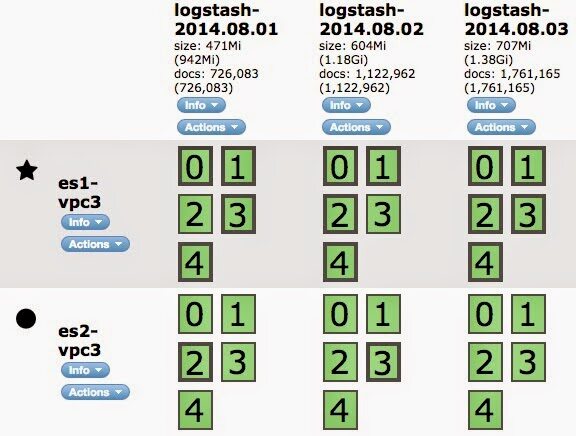
时间序列数据一般按照日期分成多个 Elasticsearch Index 来存储,比如 logstash-2014.08.02。查询的时候可以指定多个 Elasticsearch Index 作为查找的范围,也可以用 logstash-* 做模糊匹配。
美妙之处在于,虽然数据被拆得七零八落的,在查询聚合的时候甚至需要分为两个阶段完成。但是对于最终用户来说,使用起来就好像是一个数据库表一样。所有的合并查询的细节都是隐藏起来的。
对于聚合查询,其处理是分两阶段完成的:
- Shard 本地的 Lucene Index 并行计算出局部的聚合结果;
- 收到所有的 Shard 的局部聚合结果,聚合出最终的聚合结果。
这种两阶段聚合的架构使得每个 shard 不用把原数据返回,而只用返回数据量小得多的聚合结果。相比 Opentsdb 这样的数据库设计更合理。Opentsdb 其聚合只在最终节点处完成,所有的分片数据要汇聚到一个地方进行计算,这样带来大量的网络带宽消耗。所以 Influxdb 等更新的时间序列数据库选择把分布式计算模块和存储引擎进行同机部署,以减少网络带宽的影响。
除此之外 Elasticsearch 还有另外一个减少聚合过程中网络传输量的优化,那就是 Hyperloglog 算法。在计算 unique visitor(uv)这样的场景下,经常需要按用户 id 去重之后统计人数。最简单的实现是用一个 hashset 保存这些用户 id。但是用 set 保存所有的用户 id 做去重需要消耗大量的内存,同时分布式聚合的时候也要消耗大量的网络带宽。Hyperloglog 算法以一定的误差做为代价,可以用很小的数据量保存这个 set,从而减少网络传输消耗。
为什么时间序列需要更复杂的聚合?
关系型数据库支持一些很复杂的聚合查询逻辑,比如:
- Join 两张表;
- Group by 之后用 Having 再对聚合结果进行过滤;
- 用子查询对聚合结果进行二次聚合。
在使用时间序列数据库的时候,我们经常会怀念这些 SQL 的查询能力。在时间序列里有一个特别常见的需求就是降频和降维。举例如下:
12:05:05 湖南 81
12:05:07 江西 30
12:05:11 湖南 80
12:05:12 江西 32
12:05:16 湖南 80
12:05:16 江西 30
按 1 分钟频率进行 max 的降频操作得出的结果是:
12:05 湖南 81
12:05 江西 32
这种按 max 进行降频的最常见的场景是采样点的归一化。不同的采集器采样的时间点是不同的,为了避免漏点也会加大采样率。这样就可能导致一分钟内采样多次,而且采样点的时间都不对齐。在查询的时候按 max 进行降频可以得出一个统一时间点的数据。
按 sum 进行降维的结果是:
12:05 113
经常我们需要舍弃掉某些维度进行一个加和的统计。这个统计需要在时间点对齐之后再进行计算。这就导致一个查询需要做两次,上面的例子里:
- 先按 1 分钟,用 max 做降频;
- 再去掉省份维度,用 sum 做降维。
如果仅仅能做一次聚合,要么用 sum 做聚合,要么用 max 做聚合。无法满足业务逻辑的需求。为了避免在一个查询里做两次聚合,大部分的时间序列数据库都要求数据在入库的时候已经是整点整分的。这就要求数据不能直接从采集点直接入库,而要经过一个实时计算管道进行处理。如果能够在查询的时候同时完成降频和降维,那就可以带来一些使用上的便利。
这个功能看似简单,其实非常难以实现。很多所谓的支持大数据的数据库都只支持简单的一次聚合操作。Elasticsearch 将要发布的 2.0 版本的最重量级的新特性是 Pipeline Aggregation,它支持数据在聚合之后再做聚合。类似 SQL 的子查询和 Having 等功能都将被支持。
总结
时间序列随着 Internet of Things 等潮流的兴起正变得越来越常见。希望本文可以帮助你了解到那些号称自己非常海量,查询非常快的时间序列数据库背后的秘密。没有完美的数据库,Elasticsearch 也不例外。如果你的用例根本不包括聚合的需求,也许 Opentsdb 甚至 MySQL 就是你最好的选择。但是如果你需要聚合海量的时间序列数据,一定要尝试一下 Elasticsearch!
作者简介
陶文,曾就职于腾讯 IEG 的蓝鲸产品中心,负责过告警平台的架构设计与实现。2006 年从 ThoughtWorks 开始职业生涯,在大型遗留系统的重构,持续交付能力建设,高可用分布式系统构建方面积累了丰富的经验。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 )。
)。




