
你是用什么方法来持久保存数据的?这是在几乎每一次关于 iOS 技术的交流或讨论都会被提到的问题,而且大家对这个问题的热情持续高涨。本文主要从概念上把“数据存储”这个问题进行剖析,并且结合各自特点和适用场景给大家提供一个选择的思路,并不详细介绍某一种方式的技术细节。
谈到数据储存,首先要明确区分两个概念,数据结构和储存方式。所谓数据结构就是数据存在的形式。除了基本的 NSDictionary、NSArray 和 NSSet 这些对象,还有更复杂的如:关系模型、对象图和属性列表多种结构。而存储方式则简单的分为两种:内存与闪存。内存存储是临时的,运行时有效的,但效率高,而闪存则是一种持久化存储,但产生 I/O 消耗,效率相对低。把内存数据转移到闪存中进行持久化的操作称成为归档。
二者结合起来才是完整的数据存储方案,我们最常谈起的那些:SQLite、CoreData、NSUserDefaults 等都是数据存储方案。当然在这些框架提供的方案之外,我们自己也可以按照个性化需求订制方案。这些存储方案侧重不同,支持的形式和方式也各不相同,在不同的使用场景下表现也是各有优劣。但万变不离其宗,无论什么方案都可以用下图来解释。
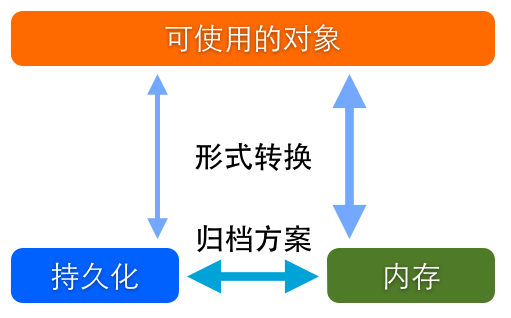
图 1,存储方案示意图
以下将对四种存储方式进行详细的介绍:
- NSUserDefaults,用于存储配置信息
- SQLite,用于存储查询需求较多的数据
- CoreData,用于规划应用中的对象
- 使用基本对象类型定制的个性化缓存方案
用NSUserDefaults存储配置信息
NSUserDefaults 被设计用来存储设备和应用的配置信息,它通过一个工厂方法返回默认的、也是最常用到的实例对象。这个对象中储存了系统中用户的配置信息,开发者可以通过这个实例对象对这些已有的信息进行修改,也可以按照自己的需求创建新的配置项。
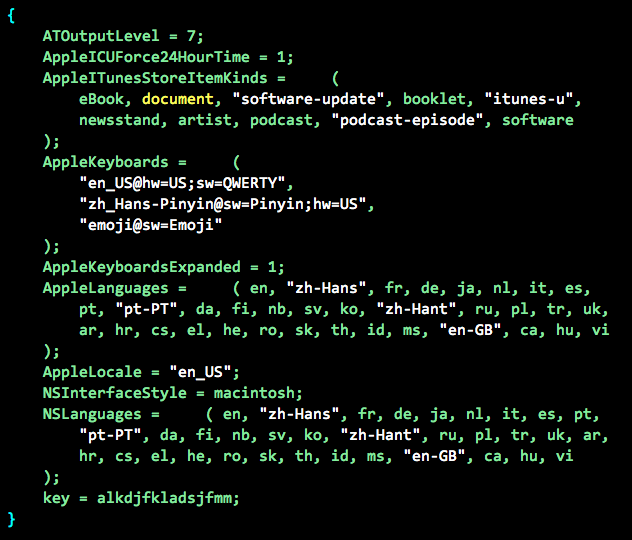
图 2,笔者手机中 [NSUserDefaults standardUserDefaults] 内容
NSUserDefaults 把配置信息以字典的形式组织起来,支持字典的项包括:字符串或者是数组,除此之外还支持数字等基本格式。一句话概括就是:基础类型的小数据的字典。操作方法几乎与 NSDictionary 的操作方法无异,另外还可以通过指定返回类型的方法获取到指定类型的返回值。
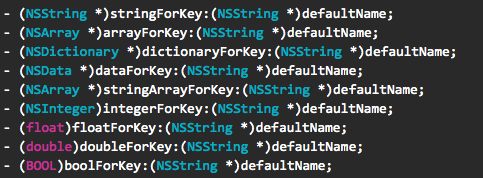
图 3,NSUserDefaults 提供的指定返回类型的方法列表
NSUserDefaults 的所有数据都放在内存里,因此操作速度很快,并还提供一个归档方法:+ (void)synchronize。开发者自定义的配置项(如图 2 中的最后一项 key:alkdjfkladsjfmm)会以 plist 格式的文件归档在相应应用目录的 /Library/Preferences/[App_Bundle_Identifier].plist 文件。再次初始化获得实例对象后,框架会把用户自定义的这个配置和系统配置合并得到完整数据。
用SQLite存储查询需求较多的数据
iOS 的 SDK 里预置了 SQLite 的库,开发者可以自建 SQLite 数据库。SQLite 每次写入数据都会产生 IO 消耗,把数据归档到相应的文件。
SQLite 擅长处理的数据类型其实与 NSUserDefaults 差不多,也是基础类型的小数据,只是从组织形式上不同。开发者可以以关系型数据库的方式组织数据,使用 SQL DML 来管理数据。 一般来说应用中的格式化的文本类数据可以存放在数据库中,尤其是类似聊天记录、Timeline 等这些具有条件查询和排序需求的数据。
每一个数据库的句柄都会在内存中都会被分配一段缓存,用于提高查询效率。另一个方面,由于查询缓存,当产生大量句柄或数据量较大时,会出现缓存过大,造成内存浪费。
SQLite 的使用起来要比 NSUserDefaults 复杂的多,因此建议开发者使用 SQLite 要搭配一个操作控件使用,可以简化操作。笔者开发的 SQLight 是一款对 SQLite 操作的封装,把相对复杂的 SQLite 命令封装成对象和方法,可以供大家参考。大家可以在 Github 上获取这个工程的代码进一步了解。
用CoreData规划应用中对象
官方给出的定义是,一个支持持久化的,对象图和生命周期的自动化管理方案。严格意义上说 CoreData 是一个管理方案,他的持久化可以通过 SQLite、XML 或二进制文件储存。如官方定义所说,CoreData 的作用远远不止储存数据这么简单,它可以把整个应用中的对象建模并进行自动化的管理。
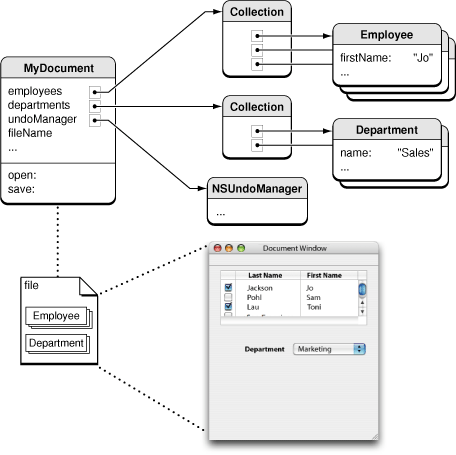
图 4,官方文档中解释 CoreData 给出的对象图示例
正如上图所示,MyDocument 是一个对象实例,有两个 Collection:Employee 和 Department,存放各自的对象列表。MyDocument、Employee 和 Department 三个对象以及他们之间的关系都通过 CoreData 建模,并可以通过 save 方法进行持久化。
从归档文件还原模型时 CoreData 并不是一次性把整个模型中的所有数据都载入内存,而是根据运行时状态,把被调用到的对象实例载入内存。框架会自动控制这个过程,从而达到控制内存消耗,避免浪费。
无论从设计原理还是使用方法上看,CoreData 都比较复杂。因此,如果仅仅是考虑缓存数据这个需求,CoreData 绝对不是一个优选方案。CoreData 的使用场景在于:整个应用使用 CoreData 规划,把应用内的数据通过 CoreData 建模,完全基于 CoreData 架构应用。
苹果官方给出的一个示例代码,结构相对简单,可以帮助大家入门CoreData。
使用基本对象类型定制的个性化缓存方案
之前提到的NSUserDefaults 和SQLite 适合存储基础类型的小数据,而CoreData 则不适合存储单一的数据,那么对于类似图片这种较大的数据要用什么方式储存呢?我给出的建议就是:自己实现一套存储方案。说到订制存储方案大家非常容易质疑,这是不是又在重新发明轮子。我可以非常明确的告诉大家,这绝不是在重新发明轮子。首先要明确,这个所谓的定制方案适用于互联网应用中对远程数据的缓存,几个限制条件缺一不可。
从需求出发分析缓存数据有哪些要求:按Key 查找,快速读取,写入不影响正常操作,不浪费内存,支持归档。这些都是基本需求,那么再进一步或许还需要固定缓存项数量,支持队列缓存,缓存过期等。从这些需求入手设计一个缓存方案并不十分复杂,Kache 是笔者根据开发应用的需求开发的一套缓存组件,通过分析Kache 希望可以给大家一个思路。
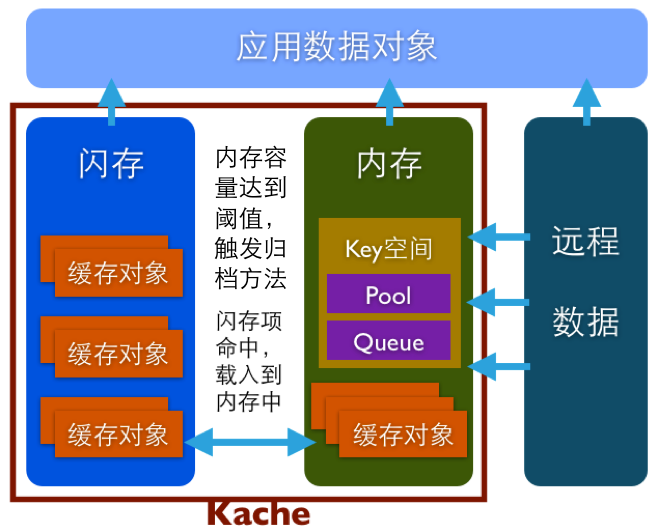
图5,Kache 架构图
如上图所示,Kache 扮演的是一个典型缓存角色。应用加载远程数据生成应用数据对象的同时,通过Kache 把数据缓存起来,再次请求则直接通过Kache 获取数据。
缓存对象可以是NSDictionary、NSArray、NSSet 或NSData 这些可直接归档的类型,每个缓存对象对应一个Key。缓存对象包括数据和过期时间,内存中存放在一个单例字典中,闪存中每个对象存为一个文件。Key 空间按照各种顺序存放缓存对象的Key 集合,Pool 为固定大小的数组,当数量达到上限,最早过期的一个Key 将被删除,对应的缓存对象也被清除。Queue 也是固定大小的数组,以先进先出的规则管理Key 的增删。 每一次有新的缓存对象存入,自动检测Key 空间中过期的集合并清除。
此外,控件提供save 和load 方法支持持久化和重新载入。
Kache 最初设计为存放图片缓存,之后也曾用于缓存文本数据,由于使用了过期和归档相结合的逻辑,可以保证大部分命中的缓存对象都在内存中,从而获取了较高的效率。读者可以从Github 上获取Kache 源码了解更多。
以上介绍了几种iOS 开发中经常会遇到的储存数据方法,从其存储原理、使用方式和适用场景几方面进行进了简单的对比。事实上每一款应用都很难采用一种单一的方案完成整个应用的数据储存任务,需要根据不同的数据类型,选择最合适的方案,以便整个应用获得良好的运行时性能。
作者简介:
高嘉峻(微博: @gaosboy ),SegmentFault.com 联合创始人,杭州 iOS 开发者沙龙发起人,资深 iOS 开发者。
感谢李永伦对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论