数据拆分机制
一、 背景
支付宝从 2009 年开始进行 1111 大促开始,从 2009 年大促 600w 的交易量到 2013 年大促那天 2 亿的交易量;在这四年中,支付宝系统的容量经历了每年指数级的提升;如果需要支持这么大的容量的话,初步估算,一个支付系统至少得支持每天 30 亿次的数据库事务,150 亿次的 dao 访问,30T 的数据包传输;如果不进行数据库拆分,这么大的开销单靠一台物理 db 完全是支撑不了的,所以必须对单点的物理 db 进行拆分。
二、 数据拆分的方案
Sharding 的基本思想就要把一个数据库切分成多个部分放到不同的数据库 (server) 上,从而缓解单一数据库的性能问题;不太严格的讲,对于海量数据的数据库,如果是因为表多而数据多,这时候适合使用垂直拆分,即把关系紧密(比如同一业务模块)的表切分出来放在一个物理 db 上;如果表并不多,但每张表的数据非常多,这时候适合水平拆分,即把表的数据按某种规则(比如按 ID 散列)拆分到多个物理 db 上;当然,现实中更多是这两种情况混杂在一起,这时候需要根据实际情况做出选择,也可能会综合使用垂直与水平拆分,从而将原有数据库切分成类似矩阵一样可以无限扩充的数据库 (server) 阵列。
垂直拆分的最大特点就是规则简单,实施也更为方便,尤其适合各业务之间的耦合度非常低,相互影响很小,业务逻辑非常清晰的系统,也可以对故障进行有效的隔离;在这种系统中,可以很容易做到将不同业务模块所使用的表分拆到不同的数据库中;根据不同的表来进行拆分,对应用程序的影响也更小,拆分规则也会比较简单清晰。
水平拆分更多的是解决 db 带来的整体容量和性能问题,对于表中的数据按照某一种规则拆分到不同的物理表或者物理 db 中,从而把应用对数据库的访问压力分散到不同的 db;其实本质还是进行分布式的部署架构思路;但是这种规则拆分后的数据必须尽量达到平均,否则就失去的拆分的意义。
三、 数据拆分的实例介绍
在支付宝的架构演进过程中也进行了很多数据拆分这一方面的改造。
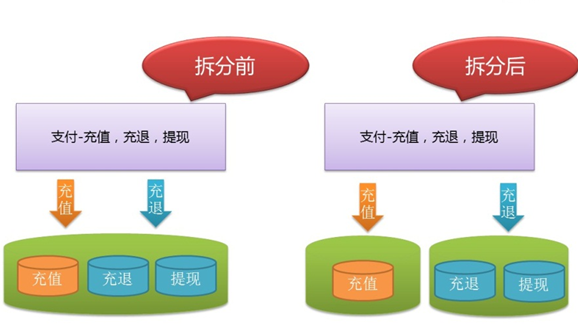
垂直拆分的案例:支付宝系统,该系统上面运行了三大块的业务:充值 / 充退 / 提现;充值业务非常重要,业务的流量也非常大,是个非常关键的业务;充退和提现的业务重要性相对低一点,但是这类业务会进行一些大数据量的操作,对于 db 的影响非常大;所以为了确保充值业务的稳定性,db 层面进行了垂直拆分的改造,把充值和充退提现数据分两个物理 db 进行存储和访问,具体如下图所示:
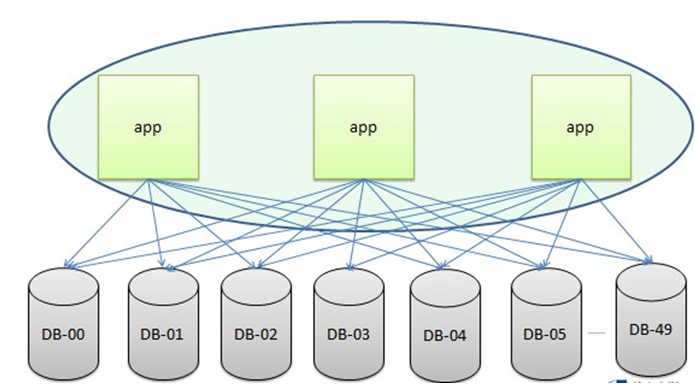
水平拆分的案例:支付宝系统,支付关键的业务都在该系统上,而且每天的业务量都非常大;根据业务量增长的趋势,在不久的将来,单个 db 已经支撑不了这么庞大的业务吞吐量,所以我们对支付的数据按照用户 id 的维度进行了水平的拆分,具体如下图所示:
四、 水平拆分应用测试分析
本次我们会对水平拆分的方案做详细的测试关注点分析。
功能性需求测试分析
1. 分库分表功能逻辑的覆盖
考虑到拆分前的数据是落地到一个物理库一个物理表,拆分后其实是落地到多个物理库的多个物理表中,所以对于不同拆分维度的数据落地到正确的数据库和数据表是水平拆分类改造最重要也是最关键的测试覆盖点;但是有些同学可能会产生疑问,如果需要覆盖 100 个甚至更多的数据库表该怎么覆盖;其实这个可以用自动化脚本直接从数据访问层对每个 sql 进行全量覆盖,这个点也主要是对路由规则和数据源配置的覆盖校验。
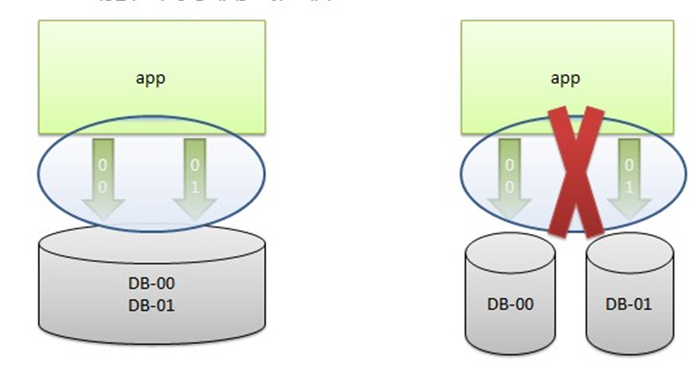
2. 跨库的事务无法支持
事务是完整性的单位,一个事务的执行是把数据库从一个一致的状态转换成另一个一致的状态,但是如果在一个事务模板中出现了多次数据库的操作,并且这些操作对应的数据源针对的是不同的物理存储,那么这个事务一致性肯定不能被保证的;在应用分库之后,原先在一个事务中的多次数据库的操作有可能被指向不同的物理存储,所以针对这样的逻辑是肯定需要改造的,测试分析的时候一定要重点分析这样的场景。
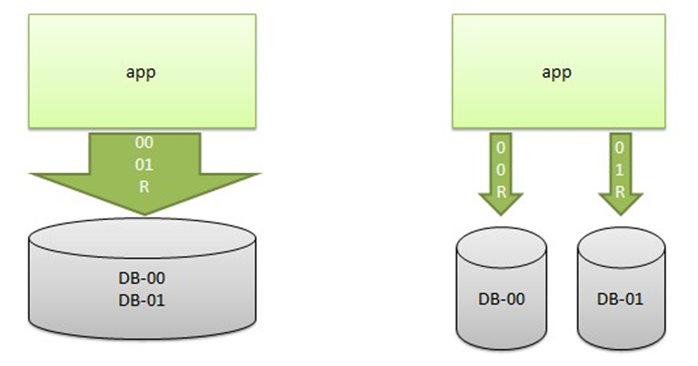
3. 业务数据 merge 需要覆盖所有分库
拆分前,一份表中所有的数据都是存放在一个物理表中;而数据库表拆分后,原来在一个表中的数据有可能会分布在不同的物理数据库和物理数据表中,所以在进行一些大数据的查询操作时,从原先的一条 sql 执行就能获取全量数据,拆分后就可能需要通过针对不同表的多个 sql 获取并在应用逻辑中进行合并,所以测试的时候一定需要关注到这部分的改造是否到位,是否有分析遗漏的地方。
非功能性需求测试分析
一般数据库拆分的项目实施过程中,在应用发布后,其实数据层面还是没有真正的做到物理上的切分,需要逻辑分库的这么一个过程主要是考虑到发布过程中的一些数据和业务兼容性,还有一些可能是由于物理机器采购和调试的进度和项目发布的时间点不匹配等客观因素,所以在真正做物理拆分前会有一个逻辑分库运行的阶段。
1. 逻辑拆分过程中数据一致性
逻辑拆分阶段,从应用系统的视角来看对应的数据源都是独立的,应用的业务逻辑也都是按照真正分库分表的逻辑去实现的,但是这些独立数据源底层还是同一套物理数据源,物理 db 的部署也都是按照拆分前的方式,虽然应用看到的是多个库多份表,但是 db 层面还是单库单表;对于发布过程中新的代码访问的数据库表和老代码访问的数据库表都是同一份,虽然应用上看到的是不同的,所以通过这种方式就可以避免发布过程中新老代码对于数据访问兼容性的问题,测试对于逻辑拆分的验证主要还是通过对新老代码业务的验证,确保访问的数据是同一份的。
2. 物理拆分过程中数据一致性
物理拆分是数据库拆分项目的最终目标,一般在物理拆分之前,会进行历史数据的迁移工作,确保新的数据库保存和原先物理库一致的数据,但是对于增量的数据处理还需要其他配套的方案支持;一般进行物理拆分的方案有两种:第一种是比较暴力的方式,直接通过数据源连接的 dns 切换到新机器,不过这种方式有个缺点,需要进行新老库增量数据的同步和对比,这个过程可能比较长,所以对业务造成损失的时间会比较长;还有一种方式就是需要应用进行 failover 的改造来配合数据的拆分,对所需要迁移的数据库先进行 failover 的切换,然后再进行 dns 的切换,这样业务只会在 failover 切换和回切瞬间产生影响。
3:新老库 seq 同步性问题
在做物理拆分的时候,由于会涉及到老数据的迁移和同步,所以对于在新库产生的数据要避免和老库迁移过来的数据产生冲突,这个冲突主要是唯一性主键相关的冲突,在 oracle 中我们一般会通过数据库提供的 seq 和其他的特定位来组成这个主键,对于这个 seq 在新老库又是两套,所以我们在确定新库的 seq 时一定要和原先老库的 seq 进行隔离,而这个梳理和明确的过程需要测试的同学和 dba 一起明确。
性能需求测试分析
说到性能提升,其实这是我们做分库分表改造的初衷,在未进行分库分表的情况下,随着时间和业务的发展,库中的表会越来越多,表中的数据量也会越来越大,相应地,数据操作,增删改查的开销也会越来越大;另外,由于无法进行分布式式部署,而一台服务器的资源(CPU、磁盘、内存、IO 等)是有限的,最终数据库所能承载的数据量、数据处理能力都将遭遇瓶颈,所以分库分表就是为了解决单个 db 性能的瓶颈。
1. 关注 tps,内存,连接数等性能指标
在针对分库分表的项目做性能压测的时候,我们主要关注的还是应用整体的 tps,响应时间,内存情况,还有数据源连接数等;而对于分库之后物理数据源的连接数大小的设定,我们也得出了一个基本的公式,如果物理数据源的连接数调的太大可能会增加应用的内存的开销,如果物理数据源的连接数调的太小,则会影响应用整体的 tps 和响应时间,所以对于连接数的设置必须要通过多轮压测得到一个理想的值。

2. 连接数,ps-cache,fetch_size 设置合理性
ps-cache:PreparedStatement(开源框架的类)是 JDBC 里面提供的对象,而 JBOSS 里面引入了一个 PreparedStatementCache,PreparedStatementCache 即用于保存与数据库交互的 prepareStatement 对象;PreparedStatementCache 使用了一个本地缓存的 LRU 链表来减少 SQL 的预编译,减少 SQL 的预编译,意味着可以减少一次网络的交互和数据库的解析(有可能在 session cursor cache hits 中命中,也可能是 share pool 中命中),这对应用的 DAO 响应延时是很大的提升,另外,PreparedStatementCache 也不是设置越大越好,毕竟,PreparedStatementCache 是会占用 JVM 内存的;之前出现过一个核心系统因为在增加了连接数(拆分数据源)后,这个参数设置没有修改,导致 JVM 内存被撑爆的情况;(JVM 内存占用情况 = 连接总数 *PreparedStatementCache 设置大小 * 每个 PreparedStatement 占用的平均内存)。
fetch_size:当我们执行一个 SQL 查询语句的时候,需要在客户端和服务器端都打开一个游标,并且分别申请一块内存空间,作为存放查询的数据的一个缓冲区;这块内存区,存放多少条数据就由 fetchsize 来决定,同时每次网络包会传送 fetchsize 条记录到客户端;应该很容易理解,如果 fetchsize 设置为 20,当我们从服务器端查询数据往客户端传送时,每次可以传送 20 条数据,但是两端分别需要 20 条数据的内存空闲来保存这些数据;fetchsize 决定了每批次可以传输的记录条数,但同时,也决定了内存的大小;这块内存,在 oracle 服务器端是动态分配的,而在客户端,PS 对象会存在一个缓冲中(LRU 链表);
fetchsize 的设置,跟具体业务系统有关系,没有一个最好的值可以供各个应用都可以使用,一般的系统,fetchsize 使用 jdbc 的默认值就可以了。在某个特定的条件下测试的 fetchsize,得出一个值,然后所有人都用这个值来设置自己的应用系统,一般情况下,这仅仅只是一些资源的浪费,但是在数据源拆分改造中,当 fetchsize 设置的太大,有可能会导致性能的急剧下降,甚至会导致应用上可怕的 JVM 内存溢出,在不少公司发生过这种惨痛的教训,建议在设置这个值之前,先做一个 JVM 内存的 DUMP,以便能够对内存的占用情况有一个清晰的了解。
五、 总结
功能性:
1. 分库分表功能逻辑的覆盖
2. 跨库的事务无法支持
3. 业务数据 merge 需要覆盖所有分库
非功能:
1. 逻辑拆分过程中数据一致性
2. 物理拆分过程中数据一致性
3. 新老库 seq 同步性问题
性能:
1. 关注 tps,内存,连接数等性能指标
2. 连接数,ps-cache,fetch_size 设置合理性
感谢侯伯薇对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




