
作为国内第一个公有云计算平台,SAE 从 2009 年已经走过了 6 个年头,积累了近百万开发者,而一直以来 SAE 一直以自有技术提供超轻量级的租户隔离,这种隔离技术实际是从用户态和内核态 hook 核心函数来实现 HTTP 层的进程内用户隔离:
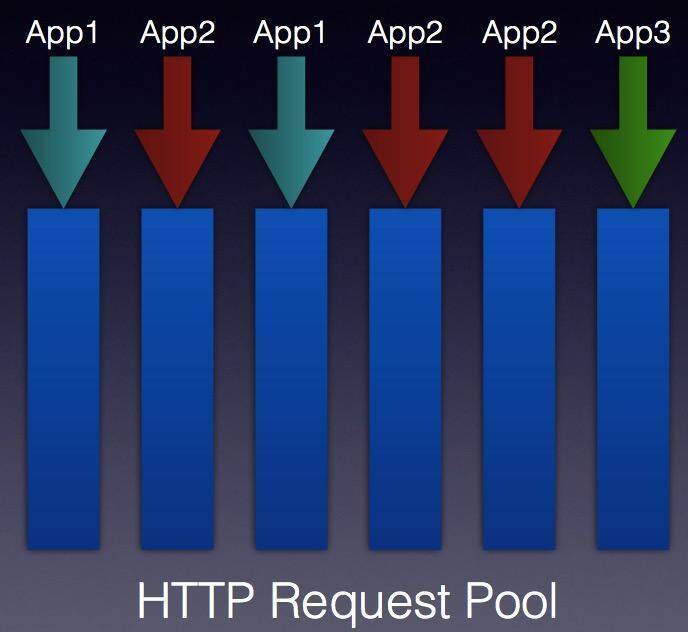
如图所示,这种方式的好处是:
- 精准的实现租户间 CPU、IO、Memory 隔离
- 可以实现进程多租户复用,从而达到超低成本
- 完全对等部署,管理方便
另外,这种模式的最大好处可以实现完全的无缝扩容,SAE 自动根据 HTTP 等待队列长度进行跨集群调度,用户从 1000PV 到 10 亿 PV 业务暴增,可以不做任何变更,早在 2013 年,SAE 就利用这种机制成功的帮助抢票软件完成 12306 无法完成的任务, 12306 抢票插件拖垮美国代码托管站 GitHub 。
但是这种模式也有很大的弊端,最主要的弊端就是:
- namespace 独立性不足
- 本地读写支持度不好
- 容易产生用户 lock-in
针对于此,SAE 决定基于 Kubernetes 技术推出以 Docker 容器为运行环境的容器云,下面我们就以下三个方面展开讨论:
- Kubernetes 的好处是什么
- Kubernetes 的不足有哪些
- 针对不足,怎么改进它
一、Kubernetes 的好处
选择一个技术,对于大型业务平台来讲,最重要的就是它的易维护性,Kubernetes 由 Go 语言编写,各个逻辑模块功能比较清晰,可以很快定位到功能点进行修改,另外,Kubernetes 可以非常方便的部署在 CentOS 上,这点对我们来讲也非常重要。
Kubernetes 提出一个 Pod 的概念,Pod 可以说是逻辑上的容器组,它包含运行在同一个节点上的多个容器,这些容器一般是业务相关的,他们可以共享存储和快速网络通信。这种在容器层上的逻辑分组非常适合实际的业务管理,这样用户可以按照业务模块组成不同的 Pod,比如,以一个电商业务为例:可以把 PC 端网站作为一个 Pod,移动端 API 作为另一个 Pod,H5 端网站再作为一个 Pod,这样每个业务都可以根据访问量使用适当数量的 Pod,并且可以根据自己的需求进行扩容和容灾。
相同的 Pod 可以由 Replication Controller 来控制,这样的设计方便 Pod 的扩容、缩容,特别当有 Pod 处于不健康的状态时,可以快速切换至新的 Pod,保证总 Pod 数不变,而不影响服务。这种模式保证了实际业务的稳定性。
二、Kubernetes 的不足
对于目前的 Kubernetes 来讲,无缝扩容是一个比较致命的问题,不过好在社区有大量的人力已经投入力量在开发了,截止到我写稿的时间,基于 CPU 的扩容代码已经出来,也就是用户可以设定一个平均 CPU 利用率,一旦数值高于某个阈值,就触发扩容。但当我们仔细思考这个模式时,就会发现不合理的地方:CPU 利用率并不能真正反映业务的繁忙程度,也不能反映是否需要扩容。比如某些业务需要大量跟 API 或者后端数据库交互,这种情况下,即使 CPU 利用率不高,但此时用户的请求已经变得很慢,从而需要扩容。
再有,良好的监控一直是一个系统稳定运行的前提,但 Kubernetes 显然目前做的不够,先不说 Kubernetes 自身的监控,就是对于 Pod 的监控,默认也只是简单的 TCP Connect,显然这对于业务层是远远不够的,举个最简单的例子,假如某个业务因为短时间大并发访问导致 504,而此时 TCP 协议层的链接是可以建立的,但显然业务需要扩容。
还有一些其他的功能,不能算是不足,但在某些方面并不适用于 SAE,比如 Kube-Proxy,主要是通过 VIP 做三层 NAT 打通 Kubernetes 内部所有网络通信,以此来实现容器漂 IP,这个理念很先进,但有一些问题,首先是 NAT 性能问题,其次是所有网络走 VIP NAT,但是 Kubernetes 是需要和外部环境通信的,SAE 容器云需要和 SAE 原有 PaaS 服务打通网络,举个例子,用户利用容器云起了一组 Redis 的 Pod,然后他在 SAE 上的应用需要访问这个 Pod,那么如果访问 Pod 只能通过 VIP 的话,将会和原有 SAE 的网络访问产生冲突,这块需要额外的技巧才能解决。所以我们觉得 Kube-Proxy 不太适合。
三、如何改进 Kubernetes
针对 Kubernetes 的不足,我们需要进行改进,首先需要改造的就是日志系统,我们希望容器产生的日志可以直接推送进 SAE 原有日志系统。
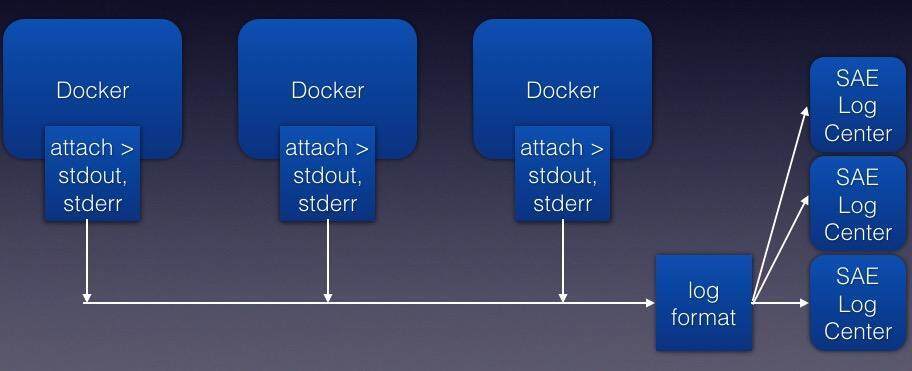
如上图所示,我们将容器的 stdout、stderr 通过 log format 模块重定向分发到 SAE 的日志中心,由日志中心汇总后进行分析、统计、计费,并最终展现在用户面板,用户可以清晰的看到自己业务的访问日志、debug 日志、容器启动日志以及容器的操作日志。
(点击放大图像)

其次,既然我们不使用Kube-Proxy 的VIP 模式,那么我们需要将Pod 对接到SAE 的L7 负载均衡服务下面,以实现动态扩容和容灾。
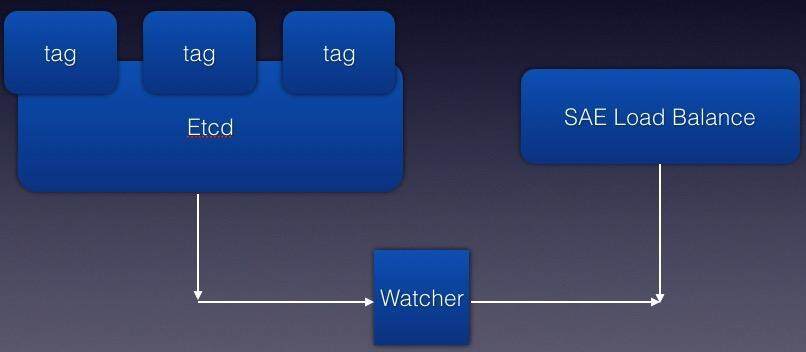
etcd watcher 监控 etcd 里 pod 路径下的文件变更事件,得到事件取配置文件处理,判断配置文件里状态更新,将容器对应关系的变化同步到 SAE Load Balance,Load Balance 会在共享内存中 cache 这些关系,并且根据实际的用户请求的 HTTP Header 将请求 forward 到相应的 Pod 的对外端口上。当用户手工增加 Pod 时,Watcher 会在 100 毫秒内将新增的 Pod 的映射关系同步到 Load Balance,这样请求就会分配到新增的 Pod 上了。
当然,对于云计算平台来讲,最重要的还是网络和存储,但很不幸,Kubernetes 在这两方面都表现的不够好。
网络
首先,我们来看对于网络这块 PaaS 和 IaaS 的需求,无论是 IaaS 还是 PaaS,租户间隔离都是最基本的需求,两个租户间的网络不能互通,对于 PaaS 来讲,一般做到 L3 基本就可以了,因为用户无法生成 L2 的代码,这个可以利用 CAP_NET_RAW 来控制;而对于 IaaS 来讲,就要做到 L2 隔离,否则用户可以看到别人的 mac 地址,然后很容易就可以构造二层数据帧来攻击别人。对于 PaaS 来讲,还需要做 L4 和 L7 的隔离处理,比如 PaaS 的网络入口和出口一般都是共享的,比如对于出口而言,IaaS 服务商遇到问题,可以简单粗暴的将用户出口 IP 引入黑洞即可,但对于 PaaS 而言,这样势必会影响其他用户,所以 PaaS 需要针对不同的应用层协议做配额控制,比如不能让某些用户的抓取电商行为导致所有用户不能访问电商网站。
目前主流的 Docker 平台的网络方案主要由两种,Bridge 和 NAT,Bridge 实际将容器置于物理网络中,容器拿到的是实际的物理内网 IP,直接的通信和传统的 IDC 间通信没有什么区别。而 NAT 实际是将容器内的网络 IP:Port 映射为物理实际网络上的 IP:Port,优点是节约内网 IP,缺点是因为做 NAT 映射,速度比较慢。
基于 SAE 的特点,我们采用优化后的 NAT 方案。
根据我们的需求,第一步就说要将内外网流量分开,进行统计和控制。
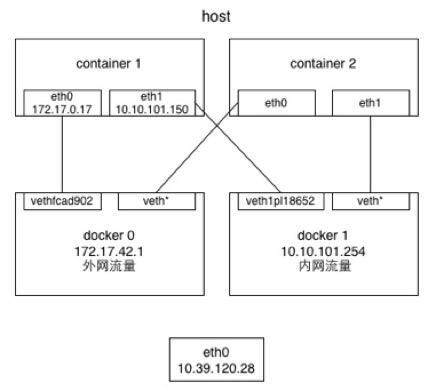
如图所示,在容器中通过 eth0 和 eth1 分布 pipe 宿主机的 docker0 外网和 docker1 内网 bridge,将容器的内外网流量分开,这样我们才能对内外网区分对待,内网流量免费,而外网流量需要计费统计,同时内外网流量都需要 QoS。
第二步就是要实现多租户网络隔离,我们借鉴 IaaS 在 vxlan&gre 的做法,通过对用户的数据包打 tag,从而标识用户,然后在网路传输中,只允许相同在同一租户之间网络包传输。
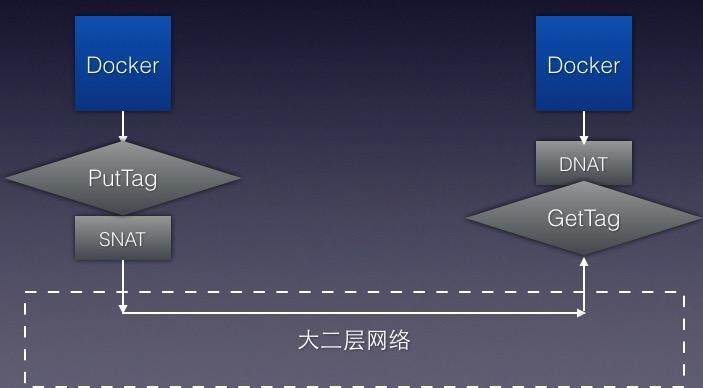
当网络包从容器出来后,先经过我们自己写的 TagQueue 进程,TagQueue 负责将网络包加上租户 ID,然后网络包会被 Docker 默认的 iptables 规则进行 SNAT,之后这个网络包就变成了一个可以在物理网络中传输的真实网络包,目标地址为目标宿主机 IP,然后当到达目标时,宿主机网络协议栈会先将该网络包交给运行在宿主机上的 TagQueue 进程,TagQueue 负责把网络包解出租户 ID,然后进行判断,是否合法,如果不合法直接丢弃,否则继续进行 Docker 默认的 DNAT,之后进入容器目标地址。
除去 Pod 间的多租户网络,对外网络部分,SAE 容器云直接对接 SAE 标准的流量控制系统、DDOS 防攻击系统、应用防火墙系统和流量加速系统,保证业务的对外流量正常
存储
对于业务来讲,对存储的敏感度甚至超过了网络,因为几乎所有业务都希望在容器之上有一套安全可靠高速的存储方案,对于用户的不同需求,容器云对接了 SAE 原有 PaaS 服务的 Memcache、MySQL、Storage、KVDB 服务,以满足缓存、关系型数据库、对象存储、键值存储的需求。
为了保证 Node.js 等应用在容器云上的完美运行,容器云还势必引入一个类似 EBS 的弹性共享存储,以保证用户在多容器间的文件共享。针对这种需求,Kubernetes 并没有提供解决方案,于是 SAE 基于 GlusterFS 改进了一套分布式共享文件存储 SharedStorage 来满足用户。
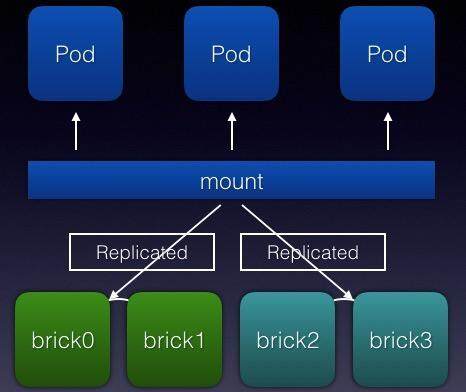
如图所示,以 4 个节点(brick)为例,两两一组组成 distributed-replicated volume 提供服务,用户可以根据需求创建不同大小的 SharedStorage,并选择挂载在用户指定的文件目录,mount 之后,就可以像本地文件系统一样使用。我们针对 GlusterFS 的改进主要针对三个方面:1,增加了统计,通过编写自己的 translator 模块加入了文件读写的实时统计;2,增加了针对整个集群的监控,能够实时查看各个 brick、volume 的状态;3,通过改写 syscall table 来 hook IO 操作,并执行容器端的 IO Quota,这样防止某个容器内的应用程序恶意执行 IO 操作而导致其他用户受影响。
通过 SharedStorage 服务,用户可以非常方便的就实现容器热迁移,当物理机宕机后,保留在 SharedStorage 数据不会丢失,Kubernetes 的 replication controller 可以快速在另外一个物理节点上将容器重新运行起来,而这个业务不受影响。
总结
Kubernetes 是一个非常优秀的 Docker 运行框架,相信随着社区的发展,Kubernetes 会越来越完善。当然,因为 SAE 之前有比较完备的技术储备,所以我们有能力针对 Kubernetes 目前的不足做大量的改进,同时,也欢迎大家来 SAE 体验运容器平台, http://www.sinacloud.com/sc2.html 。
感谢郭蕾对本文的策划和审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。
活动推荐:
2023年9月3-5日,「QCon全球软件开发大会·北京站」 将在北京•富力万丽酒店举办。此次大会以「启航·AIGC软件工程变革」为主题,策划了大前端融合提效、大模型应用落地、面向 AI 的存储、AIGC 浪潮下的研发效能提升、LLMOps、异构算力、微服务架构治理、业务安全技术、构建未来软件的编程语言、FinOps 等近30个精彩专题。咨询购票可联系票务经理 18514549229(微信同手机号)。

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论