
Facebook 的 MySQL 数据库遍布在我们位于全球的数据中心内,我们必须能在任何时间内从任何位置发生的故障中恢复。在发生此类灾难事件后,不仅需要尽量快速可靠地恢复服务,而且需要确保整个过程不会丢失任何数据。为此我们构建了一套能够对从备份中恢复数据库的能力进行持续不断测试的系统。
我们的还原系统包含两个重要组件:
- 持续还原层(Continuous Restore Tier,CRT) - 负责对所有还原操作进行调度和监控。该组件会查找包含新备份的数据库,为其创建还原作业,监控还原过程,并确保每个备份可以成功还原。
- ORC 还原协调器(ORC) - 由负责执行还原的工作进程(Peon)和负载均衡器(Warchief)组成。Warchief 接收来自 CRT 的新建还原作业并将其分配给 Peon。Peon 承载了负责执行实际还原过程的本地 MySQL 实例。
数据 CRT 会收集每个还原作业的进度信息,借此帮助我们了解数据库还原操作的资源需求,ORC 则可以帮助我们验证备份的完整性。本文将侧重于介绍 ORC 的内部原理,尤其是内部的 Peon 状态机(State machine),以及在对单一数据库进行还原的过程中我们遇到并克服的挑战。
备份概述
在构建持续还原流程前,我们首先需要了解各种可用备份选项的本质。目前我们主要进行三种备份,所有备份内容均存储在 HDFS 中:
- 完整逻辑备份,使用
mysqldump每几天进行一次。 - 差异(Diff)备份在所有未进行完整备份的日子里进行。备份过程中会再次创建完整转储,但只存储与上一次完整备份相比有差异的内容。我们会通过元数据记录每次差异备份是基于哪个完整备份进行的。
- 二进制日志(Binlog)备份从主数据库持续不断地流式传输至 HDFS。
完整和差异备份均会将--single-transaction选项传递至mysqldump,这样我们就可以对数据库获得一致的快照,该快照可取自从属(Slave)或主(Master)实例。下文会将差异和完整备份统称为转储(Dump)。
由于每天只进行一次转储操作,因此可通过 Binlog 备份确保自从备份之后,数据库所执行的每一笔事务都能被我们记录在案。随后只要对转储内容执行还原操作将数据库恢复至某个时点,随后通过 Binlog 对事务进行重播(Replay),即可顺利实现数据库的时点还原。我们的所有数据库服务器都使用了全局事务 ID(GTID),因此在从 Binlog 备份进行事务重播时我们可以获得额外的一层控制能力。
除了将备份存储在 HDFS 中,我们还会将其写入离场位置。Code as Craft 活动中 Shlomo Priymak 的讲话更详细地介绍了我们的备份基础架构。
ORC:ORC 还原协调器
架构
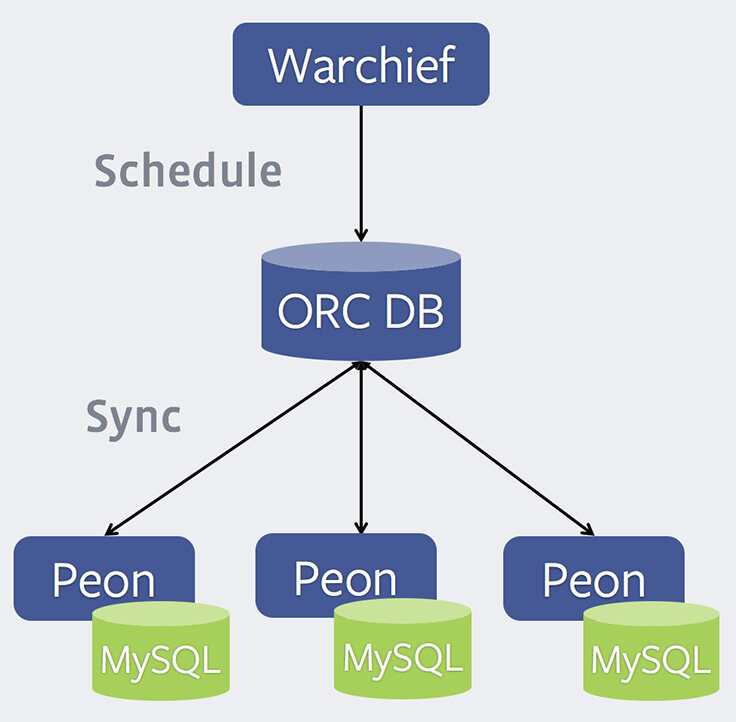
ORC 包含三个组件:
- Warchief - 负载均衡器。这是一种可暴露出 Thrift 接口的 Python 程序,通过接口可接收新的还原请求,并将其调度至可用的 Peon。
- ORC DB - 负责维持分配给每个 Peon 的作业状态、每个作业的当前状态,以及 Peon 健康度状态等信息的中央 MySQL 数据库。Warchief 会使用该数据库中存储的信息决定要将某个作业分配给哪个 Peon,以及故障恢复过程中要使用的 Peon。
- Peon - 负责还原操作的工作进程。Peon 也使用 Python 编写,可暴露出 Thrift 接口,通过该接口接收有关 Peon 的各类状态信息。每个 Peon 会定期与 ORC DB 进行同步,查询分配给自己的新作业,并汇报自己的健康度状态。运行 Peon 的服务器上还运行了一个本地 MySQL 实例,备份将还原至该实例中。
内部原理:Peon
Peon 中包含了从 HDFS 获取备份,将其载入自己的本地 MySQL 实例,通过 Binlog 重播将实例推进至某一时点等操作的所有相关逻辑。Peon 处理的每个还原作业会经历下列五个步骤:
- 选择(SELECT) - 决定需要用哪个备份进行还原(例如完整或增量,HDFS 或离场等)。
- 下载(DOWNLOAD) - 将所选文件下载至磁盘。如果要还原的是完整备份,只需下载一个文件。对于差异备份,首先需要下载完整和差异备份,随后在完整备份的基础上应用差异备份,并将最终结果存储到磁盘上。无论备份类型为何,至此我们已经在磁盘上有了一个
mysqldump输出的内容。 - 加载(LOAD) - 将下载的备份载入 Peon 的本地 MySQL 实例。按照与备份文件中每张表有关的语句进行解析,并行恢复每张表,这一过程类似于 Percona 的 Mydumper 。
- 验证(VERIFY) - 针对载入 MySQL 的数据执行健康检查(Sanity check)。
- 重播(REPLAY) - 如果有必要,在已还原备份的基础上,下载二进制日志备份并进行事务重播。我们会使用
mysqlbinlog程序筛选掉来自其他共置数据库以及空事务的 Binlog 事件,随后对同一个 MySQL 实例重播所需的事务。
每个步骤有自己对应的失败状态,因此如果某个作业在DOWNLOAD步骤失败,将显示为DOWNLOAD_FAILED状态,并且不会继续进入到LOAD步骤中。
Binlog 的选择逻辑
还原过程中最具挑战的部分可能就是确定所要下载并重播的 Binlog。完整和差异备份可以从主或从属数据库获取,然而我们只从主数据库创建 Binlog 备份。这意味着简单的时间戳对比已经无法用于确定要重播的 Binlog。
我们于 2014 年在所有服务器上部署了 GTID ,因此每笔事务都可以获得一个全局唯一标识符。此外每台运行 MySQL 的服务器也维持了一个 gtid_executed (GTID 集)变量,可将其作为对应实例目前已执行事务数量的计数器。
在具备 GTID 的情况下,从主数据库重播至从属数据库的事务可以维持自己的 GTID,这也意味着我们可以清楚地知道每笔事务是否包含在某个 GTID 集中。此外还可以针对服务器的gtid_executed值进行超集 / 子集(Superset/subset)比较,因为该值实际上就是一种严格递增的计数器和数学意义上的函数。
通过配合使用这些技术,即可在创建转储时记录服务器的gtid_executed值,同时记录每个 Binlog 文件中包含的 GTID 集,借此执行一致的比较并确定 Binlog 中的哪些事务需要重播。此外一旦需要重播的第一笔事务确定后,无需重新对比其他 GTID 即可确定需要重播的所有后续事务。我们还会使用mysqlbinlog的--stop-datetime选项确定 Binlog 流要在何处停止。
结论
面对灾难性事件,备份是最后一重保障,备份的存在使得我们具备了更自信的故障恢复能力。然而仅仅创建备份是不够的。ORC 可以帮助我们对备份进行持续不断的测试,借此验证备份的完整性,并让我们更清楚地确定成功还原数据所需提供的资源。
以 Facebook 的规模,打造一个类似 ORC 这样的系统还需要具备大量警报、监控,以及自动化的失败检测和补救机制。这些功能均是通过 CRT 实现的,我们将通过另一篇文章介绍如何将这种还原过程扩展至成千上万个数据库。
作者: Divij Rajkumar ,阅读英文原文: Continuous MySQL backup validation: Restoring backups
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论