本文翻译自: Building The LinkedIn Knowledge Graph ,原作者为 Qi He, Bee-Chung Chen, Deepak Agarwal,已获得原网站授权。
我们曾经在 LinkedIn 的主发布平台 Pulse 上发表过这篇文章的精简版。在这篇文章里,我们会更深入的阐述我们知识图谱架构背后的技术细节。
(点击放大图像)

我们在LinkedIn 公司内部广泛应用了机器学习技术来优化我们的产品:比如搜索结果排名、广告、新闻种子的更新,以及推荐人、工作机会、文章和学习机会等。这套技术栈的一个重要部分就是知识图谱,它为机器学习模型提供输入信号,也为LinkedIn 产品提供了理解数据的通道。这篇文章里会介绍构建这套知识图谱的概况。
LinkedIn 的知识图谱
LinkedIn 的知识图谱是一大套知识库,构建的基础是 LinkedIn 的各个实体,如会员(member)、工作、职位、技能、公司、地理区域和学校等等。这些实体和它们之间的关系构成了这个专业世界的本体,也被 LinkedIn 用来改进它的推荐系统、搜索、商业和消费者产品,以及业务和消费者分析等。
创建一个很大的知识库是个巨大的挑战。像 Wikipedia 和 Freebase 之类的网站主要是靠志愿者的人工贡献。其他类似的工作,像谷歌的 Knowledge Vault 和微软的 Satori,主要靠自动从互联网上扒取信息来构建知识库。与这些方法都不同,我们生成 LinkedIn 的知识图谱主要靠的是大量由会员、招聘者、广告商和公司管理者等用户产生的内容,并辅之以从互联网上扒取的数据,这样信息量巨大,也可能会有重复。当有新会员注册、发布了新招聘信息、有新公司、技能或职位出现在会员的简历和工作描述中时,知识图谱就需要扩展。
为了应对我们构建 LinkedIn 知识图谱时面临的挑战,我们应用了机器学习技术,其实就是对用户生成的内容和来源于外部的数据的标准化过程。在这个过程中,机器学习被用于实体分类系统的构建、实体关系推理、下游数据消费者的数据表现、图谱洞察抽取和用户交互数据获取等,以此来验证我们的推理并收集学习数据。LinkedIn 的知识图谱是一张动态的图。新的实体不断加入,新的关系不断形成。现有的关系也可能发生改变。比如说,一个人在得到了一份新工作之后,他的职位信息就会发生改变。当有新的实体出现时,我们必须实时地更新这些类似个人简历的内容。
构建实体分类系统
对 LinkedIn 的系统来说,实体分类系统包括一个实体的身份标记(即标志符、定义、正式名、不同语言中的同义词等)和实体的属性。实体通过两种方法创建:
- 基础实体由用户生成,并由用户生成和维护包含各种信息的属性。会员、工作、公司等都属于此类。
- 自动生成的实体则由 LinkedIn 产生。因为实体的覆盖率(有这个实体属性的会员的数量)是将数据转化为商业价值和映射到消费者产品的关键,我们会关注创建新的实体,并建立会员和这些实体之间的对应关系。通过挖掘用户简历来发现潜在的实体候选,并通过外部数据和人工验证相结合的办法来丰富实体集合,我们创建了数以万计的技能、职位、地理位置、公司、认证等等属性,并把它们与会员对应起来。
到目前为止,我们已经有约 4.5 亿个会员、累计 1.9 亿条招聘信息、900 万家公司、200 多个国家(其中 60 多个有详细的地理位置数据)、由 19 种语言描述的 3.5 万种技能、2.8 万间学校、1500 个学习领域、600 多种学位、2.4 万个职位和 500 多种认证等等,还有一些其他的实体。
实体表现了 LinkedIn 知识图谱中的节点。我们需要整理用户产生的基础实体,因为其中可能会有无意义的名字、不正确或不全面的属性、陈旧的内容,或者再没有任何其他人会有这样的实体属性。我们用归纳式生成规则的办法来发现不准确或有问题的实体。对于自动生成的实体,生成规则则包括:
- 生成候选。每个实体都有一个英文的在很多场合通用的正式名字。实体候选都是通过一些很直观的规则从会员简历和工作描述中摘出来的通用短语。
- 消除歧义的实体。在不同的上下文中一个词可能会有不同的含义,即多义词。为了表示这些会员简历和工作描述中的多义词,我们开发了软件聚类算法来将它们进行归类并表示为出现频率最高的词语向量。多义词可以在多个聚类中出现并代表不同的实体。
- 去重实体。如果多个词只不过互相是对方的别名,它们就可以表示相同的实体。通过把每个词语表示为一个单词向量(也就是由会员简历和工作描述来训练出一个由单词到向量的对应模型),我们会运行聚类算法并辅助以分类专家的手工验证,以此来去除重复的实体。在分类系统有层次结构的时候,相似的技术也会被用于将实体归类。
- 将实体翻译成其他语言。根据会员和实体之间的幂律特性,LinkedIn 的语言专家会手动地将出现频率最高、涉及会员最多的实体手动翻译成各国语言,以保证其准确性,而且基于 PSCFG 的机器翻译模型也被用于自动将使用频率不高的实体翻译成别国语言。
下图以可视化方式显示了在职位分类中的“软件工程师”职位实体。职位分类中有个层次结构:象“程序员”和“网页开发者”这些相似的职位都被归类于相同的“软件工程师”大类之下,而相似的大类职位也都归于相同的“工程”功能之下。
(点击放大图像)

实体属性被分为两类:在一个分类中与其他实体之间的关系,以及不在任何分类中的特征点。比如,一个公司实体就有与其他实体相关的属性,比如会员、技能、公司、行业等,这些都有与相应分类相关的标志符;它也有一些与任何分类中的任何其他实体都没有关系的徽标、收入、网址等。前者就对应着LinkedIn 知识图谱中的边,下一章会详细讨论。后面还会讨论从文本中提取的功能、从搜索引擎中搜得的数据、与外部数据源的数据整合和基于众包的方法等。
所有的实体属性都有相应的信任评分,或者由机器学习模型计算出来,或者是在由人手工验证时设成1.0。由机器算出来的信任分会再由另外一个单独的验证模块来校准,比如下游的应用程序可以在准确度和覆盖率之间轻松地做出权衡,只要把它解释成一种可能性就好了。
推理实体关系
在LinkedIn 生态系统中各实体之间有许多非常有价值的关系。举一些例子,从会员到其他实体(比如一个会员拥有的各项技能)之间的映射对于广告定位、搜索人、搜索招聘者、订阅种子、业务和消费者分析等都至关重要;由工作向其他实体(比如应聘一项工作所需要的各项技能)之间的映射也在驱动着工作推荐和工作搜索;在相关的模型中实体之间的相关性也是非常重要的特征。
有些实体关系是由会员生成的。比如一个会员会选择他就职的公司,而公司管理者会定义公司所处的行业,这些都是由LinkedIn 的事先录入的服务提供的。我们把这些由会员生成的实体关系称为“显式的”。有些实体关系是由LinkedIn 推理出来的。比如,如果一个会员在简历中把自己就职的公司名写成“linkedin_”,那我们就可以认为他真正的公司名是和“LinkedIn”有关的。我们把这些由LinkedIn 推理出来的实体关系称为是“推断的”。不过,并不是所有显式的关系都是可靠的,有个非常有名的问题就是“会员的失误”,就是会员自己输入的时候填错了。在下图中,有个公司规模为1-10 名雇员的名叫“uber”的小开发公司,却有96 个会员和它相关,这就是因为他们中大多数人是从预先输入的公司列表之中错选了开发公司“uber”,而不是他们实际为之效力的著名在线交通网络公司“Uber”。
(点击放大图像)

我们开发了一套近乎实时的内容处理框架来推导实体关系。总之,万亿数量级的关系数据,不管是会员生成的还是LinkedIn 推理生成的,都在知识图谱中共存。下图是一个推理会员技能的例子,LinkedIn 数据副总裁Igor 就有许多项他自己为自己输入的显式的技能,比如“分布式系统”、“Hadoop”等。那么由机器学习模型根据文本特征和别的实体元数据特征就可以为他推理出其他技能,比如“产品管理”、“管理”和“咨询”等等。
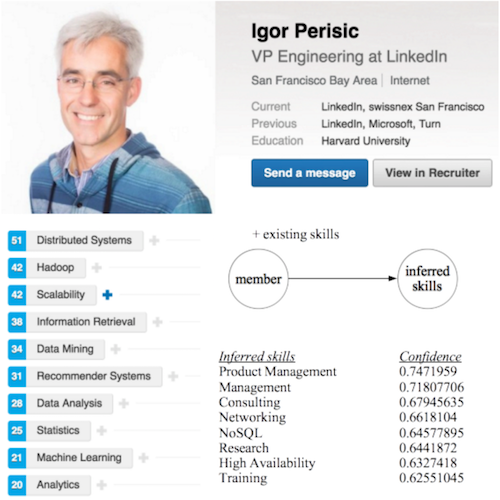
我们为每种实体关系都训练了二进制分类器:基于某些特征集合,一对实体是否以某种二进制形式(属于,或者不属于)确立某种特定的实体关系。为这种备受瞩目的任务收集高质量的训练数据,这件事非常具有挑战性。我们用会员从预输入服务中选择的关系作为正向训练的例子。通过随机添加一些噪声来作为逆向训练例子,我们为每个实体都训练了预测模型。这个方法对于常见的实体很有用。为了训练联合模型来处理那些长尾分布的实体,并修复会员的选择错误,我们就依靠众包来生成额外打了标签的数据。
推理出来的关系也会被主动推送给会员审阅,并选择(接受、拒绝或忽略)来提供反馈。被接受的那些就会成为显式的关系。另外,各种会员反馈数据都被收集起来作为新的训练数据,用于强化分类器的下一轮迭代。
数据表现
实体分类和实体关系共同组成了LinkedIn 数据图库中的标准版本的数据。有了这些,下游的各种产品就都可以在数据层面说相同的语言来交互了。应用程序团队用一组API 获取原始的知识图谱,用文本或其他类型的实体标志符做输出,输出实体标志符。各种不同的分类结果用各种不同结构化的格式展现出来,再在数据版本控制下通过Java 库、REST API、 Kafka (一种高吞吐分布式消息队列系统)流事件和 HDFS 文件等形式提供出去。这些关于原始数据图谱的数据提供机制对于在生产环境展示、索引和过滤实体都是非常有用的。
我们也把知识图谱嵌入潜在的空间(这项研究的相关背景可以在此了解)中。结果,一个实体的潜在向量就包括它在多个实体分类和多种实体关系(分类器)中的语义。在把所有的技能和职能都用深度学习技术嵌入到相同的高维度潜在空间之后,下图就可以在降维之后以图形化的方法显示出诸如“ActionScript”、“HTML Scripting”和“PHP”等技能都是和职位“Web Developer”密切相关的。由此可见,在原有的知识图谱中实体之间的语义相似性在嵌入之后仍然被保留了下来。
(点击放大图像)

在这个例子中,模型目标非常单一,就是在会员的技能潜在向量上进行简单的算法操作,以此预测会员的职务的潜在向量。推测由会员到职务的关系是特别有用的。通过并发地在多个目标方向上优化模型,我们可以在更普遍的意义上了解潜在表示。在相同的潜在空间内把异构的实体表现成向量,这为我们提供了一种简洁的方法来把知识图谱用作数据源,让我们可以从中提取各式各样的特征,作为相关模型(relevance model)的输入。这对相关模型是非常重要的,因为它可以显著地减少在知识图谱上的特征工程工作量。
获得关于图的洞察
还可以从标准化的知识图谱中推理出更多的知识,生成对业务和消费者分析的洞察。比如,通过对不同视图进行 OLAP 操作来有选择地积累图形数据,我们可以得到各种实时洞察数据,比如在某个特定地理区域内有多少会员是具备某项特定技能的(供给方)、在相同的区域内有多少份工作是需要某项技能的(需求方),再把供给方和需求方一起考虑之后,最终得到两者之间的细微差距。我们也可以把数据分析限制在某个特定的时间范围之内,来追溯洞察。根据对会员简历的更新数据所做的数据分析,下图显示了从 2014 年 6 月到 2015 年 6 月期间,可以帮助求职者从求职人群中脱颖而出的十大急需软技能。

在LinkedIn,洞察可以帮助领导和销售做出业务判断,并增强会员的参与度。比如,上图的洞察结果就有助于鼓励会员把这些软技能加到他们自己的简历中,或者通过LinkedIn 的在线课程学习它们。
从标准化后的知识图谱中发现数据洞察是一个由经验驱动的数据挖掘过程。这可以揭示出实体之间以前没有被识别出的联系,也是另一种完善LinkedIn 知识图谱的方式。如下图所示,它上面的洞察的例子定义了一种新的从会员到技能之间的实体关系,即“你可能想要学习的技能”。
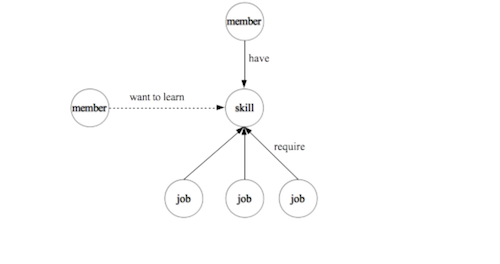
结论
构建LinkedIn 知识图谱的过程包括节点(实体)分类系统搭建、边(实体关系)推理和图形化展示。在图形之上的聚合可以提供更多的洞察,其中有一些还可以形成反馈来进一步完善图谱。这篇文章仅仅是开始分享我们的经验而已,在将来我们还会讨论更多的东西,比如知识图谱的应用程序与洞察、在实体分类和表现中用到的高级机器学习技巧、以及后台架构等等。
鸣谢
感谢 Hong Tam 提供了“uber”的用例来演示实体关系,感谢 Uri Merhav 提供了关于数据表现的“网页开发者”用例,感谢 Link Gan 提供了内容抽取的“十大急需软技能”用例,感谢整个 LinkedIn 数据标准化组,大家一起努力完成了这项令人惊叹的工作的基础部分。




