
链家网是集房源信息搜索、产品研发、大数据处理、服务标准建立为一体的国内领先且重度垂直的全产业链房产服务平台。链家网的前身为链家在线,成立于 2010 年并于 2014 年正式更名为链家网。目前,链家网线上房源已覆盖北京、上海、广州、深圳、天津、成都、青岛、重庆、大连等 22 个城市。在房产 O2O 服务领域,链家网旨在通过不断提高服务效率、提升服务体验,为用户提供更安全、更便捷、更舒心的综合房产服务。
我曾经先后在 nvidia 从事过 cuda 高性能计算、在百度从事过策略算法研发的工作。今天的分享内容主要包括如下两个部分:
1)数据挖掘在房产领域的可行性和必要性
2)数据挖掘在链家网的实践详情
数据挖掘在房产领域的可行性和必要性
下面开始第一部分, 数据挖掘在房产领域的可行性和必要性。
我们先说可行性: 链家成立已经有 15 年了,15 年内我们积累了百万级别的成交数据,楼盘字典累积了 7000 万套房屋详情信息; 超过 2000 万购房者的用户数据; 目前日均成交近千套,每日新增房源达 6000 套;每日 uv 超过千万,经纪人带购房者带看近达 4 万;每日产生的日志数据超过 5T…等等这些海量的数据构成了数据挖掘在数据来源上的可行性。
咱们再说必要性:房地产行业是一个古老的行业,自打人类进入文明阶段以来这个行业就存在。然而房产交易一直是一个复杂而艰难的过程。对于购房者而言不知道在什么时候,什么地点,怎么才能买到最合适自己的住房; 对于卖房者而言,如何将自己的房屋在合适的时间点以合适的价格卖出去; 对于经纪人而言,如何很好的服务好买家和卖家,提升自己的服务体验和业绩···这些都是需要解决的问题。 在大数据数据挖掘还没介入房产行业以前,这些只能通过口口相传的经验来解决。如今数据挖掘可以很好的解决房产领域的这些个痛点。
一句话: 数据挖掘依托房地产行业累积的海量数据,从中挖掘出最有价值的数据, 从而改善行业体验,推动行业进步。
数据挖掘在链家网的实践
接下来是第二部分, 数据挖掘在链家网的实践详情。
主要介绍链家网数据挖掘体系结构,然后从多个项目来阐述如何使用挖掘技术提升服务体验和效率,并展示效果。
数据挖掘体系图
首先看看链家网的数据挖掘体系图

从下到上依次是 基础平台、画像层、算法层、业务应用层。 我们一层层的来看。
一,基础层
基础层主要的是数据采集、数据存储、数据运算平台。
数据采集不仅仅包括线上的日志采集, 也包括线下数据。 我们先说说线下数据采集:得益于链家在数据上的早期布局, 我们采集到经纪人在当天的线下大部分行为,包括经纪人带看行为数据,经纪人对房屋的点评, 经纪人和用户的 400 电话数据,经纪人成交数据等等(后来链家经纪人作业工具 link 上线后,这些行为数据都得已线上化了), 还包括 10 万经纪人手动采集的 6000 万楼盘字典的数据。 这些数据构成了数据挖掘能够行之有效的基石。
再说线上数据采集, 为了采集到丰富的线上用户行为数据以及经纪人的作业行为数据,我们在产品进行了丰富的埋点, 包括用户注册、登陆、浏览、点击、关注、取关注、搜索、线上聊天、点评、地图找房等。这些埋点也进一步会反馈回业务系统,辅助进行模型效果的评估。
无论是线上还是线下行为数据, 从数据质量上来说,都不会是完美的,都需要进行有效的清洗和矫正。例如搜索数据中包括了很多爬虫行为,会严重影响推荐的效果; 例如经纪人在填写挂牌价格数据时,会不经意间忘却价格的单位是万元还是元,就会使得价格有些是 10 有些就是 100000 这样的,需要进行矫正。
二,画像层
画像层是整个挖掘算法的基础, 它的直接输出是挖掘算法的数据来源。
我们的画像层包括了四个方面: 用户画像; 经纪人画像;房源(业主)画像;小区画像;
先来说用户画像。
链家网的用户画像不仅仅是策略算法的基础之一,它的目的还包括:
- 整理用户线下和线上行为记录,分析用户行为、刻画用户偏好
- 快速的检索与 Olap 查询
- 实时收集线上行为,反映在用户标签
- 用户留存分析,服务于产品和运营,例如产品能够从用户画像中得到一段时间内的活跃用户后来不活跃时,如何进行针对性的激活.
- 横向提供商机服务
因此用户画像在链家网是作为一个完整的数据产品在做。
我们分如下几个方面来说明用户画像:
1)其数据流框架结构,如下图所示:
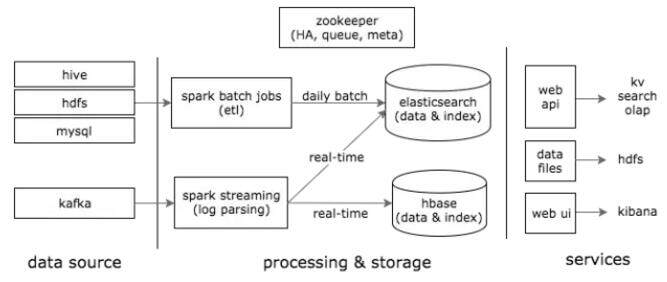
从这幅图可以看出,用户画像采用的是 Lambda 架构,包含三层架构:批处理层、实时处理层、服务层。
这种架构的优点:
a) 实时:低延迟处理数据 ; b) 可重计算:由于数据不可变,重新计算一样可以得到正确的结果 ; c) 容错:第二点带来的,程序 bug、系统问题等,可以重新计算 ; d) 复杂性分离、读写分离
这种架构的缺点:
开发和运维的复杂性:Lambda 需要将所有的算法实现两次,一次是为批处理系统,另一次是为实时系统,还要求查询得到的是两个系统结果的合并.
同时,我们使用 elasticsearch 来建立索引,保证 olap 实时查询和检索功能。方便产品经理和其他业务方根据需要获取自己需要的数据。
2)用户画像还必须能从更抽象的层面,对用户进行喜好和行为建立标签。为了能够得到准确的用户喜好和行为的标签,我们在开发的过程中考虑了如下几点:
a) 行为时间衰减
b) 负样本惩罚
c) 热门降权
d) 剔除爬虫和 Spam 数据
e) 实时数据实时加入
f) json 数据结构方便添加新标签
希望这几点对于大家自己的工作有所借鉴。
下面给出一个我们的同事的画像标签数据。

由这幅图大家可以看出,这位同事对于团结湖公寓小区和阳光 100 小区的兴趣度,他想要买的房屋价格分布在 500-800 万中间,商圈是团结湖,面积更倾向于在 130-150 平米。最后这个同事成交的地方就在团结湖公寓,价格是在 700 多万。因此,画像标签数据精准的获取了这些有用的信息。
3)为了得到完备的自然人的画像数据,我们基于 spark 和 MLlib 做了跨设备用户识别, 其整体思路如下图所示:
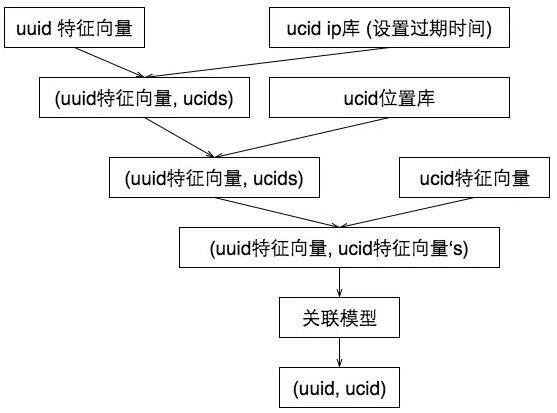
从上到下每一个 uuid 都有自己的特征向量, 我们逐步在其中考虑进 ip 特征,位置特征。最后使用关联模型,进行 uuid 和 uuid 之间的关联度,从而识别出来 uuid 们背后的自然人。我们使用了 spark 体系中的 Mllib 来完成跨设备用户识别。这是非常必要的。因为很多用户并不登陆链家 app,我们通过这种方法,就可以将用户多次不登录查看的行为绑定到一个自然人身上,从而使得画像数据足够完备。
4)最终用户画像还做了可视化。
为了避免泄露用户隐私,我们这里只给出群体用户的画像展示。
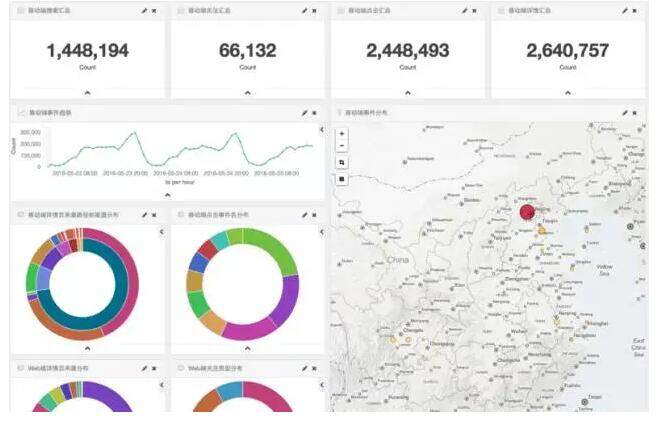
这是基于 kibana 实现的。
其他的几个画像:经纪人画像、房源画像、小区画像虽然在内容上有不一致,但是实现方法和架构上是一致的,这里就不再多缀述。
三,算法层
算法层是在业务应用层的需求过程中慢慢累积下来的, 其中重要算法的详细描述我们留在第四部分来阐述。 这里我们简单列举如下:
- CF:协同过滤,是在推荐系统中常用的算法;
- GBDT、Hedonic、ANN、RandomForest 是我们在估价中使用的四种算法,估价中需要对样本做比较严格的过滤,因此我们还使用了 LOF 算法
- LR、SVM 是在房源分级中使用的算法
- HMM 是我们在客源解读中刻画用户购房意愿的算法
- Kmeans 是寻找相似房源相似小区时使用的方法
- CNN 卷积神经网络为基础的深度学习方法,是我们在做图片方面的处理时使用的算法
四,业务应用层
业务应用层,是指的挖掘算法结合业务,在产品端的落地。这里会涉及到实际中已经运行在线上的项目。我们先简单列举链家网的产品中使用了数据挖掘技术的项目:
房源推荐、内容推荐、住哪儿、链链小机器人、房屋估价、房价频道、房源竞争力、客源解读、相似房源、检索策略、排序策略、展位规则、标签体系
可以看出来,数据挖掘技术在链家网的产品中得到了广泛深入的使用。 由于时间关系,不打算全部描述所有列举出来的项目。 我们挑其中的房屋估价、房源推荐、展位规则来讲述。
1)房屋估价
房屋估价顾名思义,是对房屋的出售价格进行预估。房屋交易的核心是价格,经纪人、用户、业主三方围绕着房屋的价格进行博弈,最终形成成交; 因此如果能够通过系统的机器学习方法,预估出来房屋的成交价格,那么对于用户购房和业主卖房的定价都有助益作用; 同时其还会对未来的价格涨跌做一定的预测,所以也能够帮助用户做决策;
另外从我们产品上线后的经验来看, 估价也是增强老用户粘性和吸引新用户的一个很好的入口, 因此买了房的人必定很关心自己的房子买了后到底涨跌几何, 同样你也可能很好奇自己的土豪老板的房子到底值多少钱,是吧? 因此,大家如果没有使用过我们的估价产品,可以下载掌上链家 app 试用这个功能。目前估价已经累计有 400 万用户使用过这个功能,每天的 uv 在 2-3 万左右。
下面我们说说估价我们是怎么做的, 我们如何评估估价功能,以及我们如何在迭代中一步步的提升了估价的准确率和用户体验。
a)我们是怎么做的估价
模型训练的框架图:
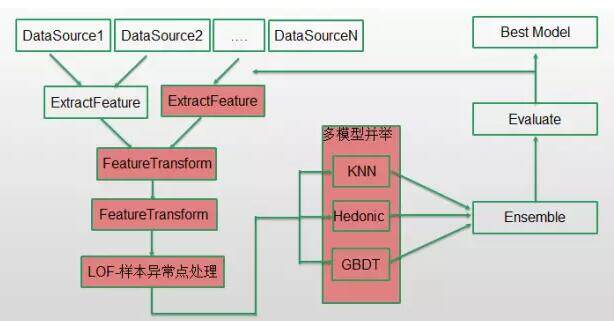
基本思路就是将链家海量的成交和挂牌数据,特征化后训练出多个回归模型,然后在线上将新上的房源特征输入到这些模型中,预估出其在不同的时间点的成交价格。比较重要的是特征提取、多模型的使用,以及样本的增加。这些小小的点对于估价效果的提升都有很大的助益。我们先来说下如何评估估价的效果。做机器学习,效果评估是不可缺少也是非常重要的一环。
b) 评估方法
评估指标包括两个: 估价准确率 和 估价平均误差;
估价准确率定义为: 估价准确的房源数比上全部房源数目 ---- 这里的准确是指如果房子成交价格在 100 万,我们估算出来的价格在 95—105 范围内就算准确;
估价平均误差:就是估算出来的价格和真实成交价差值的百分比的平均。 也即如果 A 房源我们估价的误差是 5%,B 房源我们估价的误差是 4%,那么平均误差就是 4.5%。
估价目前的准确率在 80%, 平均误差率 4%-5%。
这两个指标的时间基准都是 T-1, 也即我们会在每天对所有房源进行估价,同时会将这些价格存储起来。如果第二天其中某些房源成交了,就会将它当天的成交价和昨天的估价进行计算比较。
c) 一些迭代过程和经验
i) 影响房屋价格的因素千千万万, 但是有些特征对房屋价格的影响是具有边界递减效应的,因此可以对这类特征做 log 变换,例如面积, 这是 hedonic 模型中的主要思想, 这个思想也可以借鉴在其他算法模型中。
ii) 税收等相关特征对于价格的影响很大,也很复杂,需要辅助以相应的规则
iii) 复杂场景下,非线性模型的效果要好于线性模型。 这也是我们后来抛弃 hedonic 转而使用 GBDT 的原因,不过带来的影响就是模型的可解释性不高; 同时神经网络这样的非线性模型的调参过程相当精细和复杂,我们在使用中发现其效果并没有一些论文中描述的那么好,这可能是我们的调参没到位。
iv) 样本很重要, 这里包含两层意思, 第一层是要将坏样本剔除,也即异常点过滤,这点我们使用了经典的 LOF 算法; 第二层是尽可能增加好的训练样本,这里我们做了两件事,第一件事是我们发现 LOF 算法过滤条件过于严苛,所以后续我们采用了最简单的平均值周边过滤,第二件事是结合业务,我们发现交了意向金的在售房源,也是可以纳入到“已成交”的样本中的。经过这一步,我们估价的准确率稳定在了 80%,同时用户的负反馈也少了很多
v) 需要考虑平滑策略, 这是非线性回归模型在纳入时间因子时需要考虑的。从我们的角度而言,我们之所以要做价格平滑,是不想让用户看到自己的房子的价格在相隔两天中发生比较大的感知到的差异。
2) 房源推荐
做一件事,我们得先讨论这件事的必要性。 一般我们认为推荐系统的目的有如下几个:
i) 发掘物品长尾, the long tail
ii) 增加用户满意度和忠诚度
iii) 增加用户可选择的路径,从而提升转化
可是,不同于京东淘宝或者豆瓣, 房屋买卖是一个低频交易, 而且几乎是大部分人一生中最重大的一次大额交易. 因此对于推荐在房产交易中是否有必要,一直是我们讨论的点, 因为我们当然可以认为买房这件事是如此重要,买房者当然会每一个房源仔细的查看。为此我们做了初步的数据分析,发现房屋买卖中也确实存在长尾效应,同时基于搜索结果的排序规则也没法满足全部用户,因此房源推荐本身有其必要性。
在链家网,房源推荐在多个产品都有落地。不同的产品上的推荐其评估方法有所不同,以方便针对目标进行不同的调优。例如 web 端我们考量的是推荐结果的点击率和用户行为动作对推荐结果影响的实时性。 例如经纪人使用的 link 端,我们更多考量经纪人对房源约带看的成功率,从而更深层次的来对推荐结果进行业务调优。
链家网的房源推荐,我们使用了多重推荐结果的组合,从而有效的解决了单一推荐方法的一些缺点。 下面我们把这些方法列举如下表。
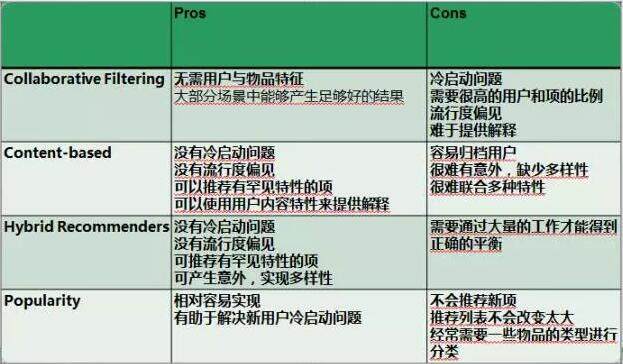
3) 展位规则
展位规则在链家网的应用,大家可以类比为百度的 ctr 预估。
a)我们选取的模型实 GBDT,之所以选择 GBDT 来做匹配度计算, 主要是因为
i)GBDT 能够自动做特征交叉,发现有效的特征组合, 符合复杂业务场景
ii) 房产行业相比而言训练数据相对较少,人工构造的 high level 特征多, 需要使用复杂的非线性模型
iii)GBDT 非线性,拟合能力强,且不易过拟合
b)选用的特征方面,
i) 客户特征: 我们选用了表征客户购房意愿看房热度,以及看房喜好的一些特征。例如线上关注房源数目,近期看房的价格分布,面积分布等等
ii) 经纪人特征: 选用了表征经纪人服务能力和服务特质的特征。例如当前其服务客户数目,主要服务小区的价格分布,地域分布,年限分布等
iii) 市场形势特征: 大家知道房产领域的交易热度和市场背景有不小的关联,因此需要加上在不同时间点的市场行情特征
iv) 经纪人客户相似度: 价格相似、面设相似等等
c) 特征的表征方面,我们做了如下几点:
i) 权重归一: 对于线上不同行为线下不同行为,做了统计学意义上的归一化
ii) 特征离散化: 对价格分布做了 5000 为间隔的离散
iii) 价格相似使用了经纪人和用户离散特征向量的余弦距离
d) 从调研结果来看,符合此特征的展位匹配关系,能够带来 20% 的效果提升。
由于时间有限, 以上就是这次分享的全部内容,感谢大家的参与。谢谢。
Q&A
Q1:请问具体使用了 spark MLlib 里面的什么算法来做跨用户识别的?
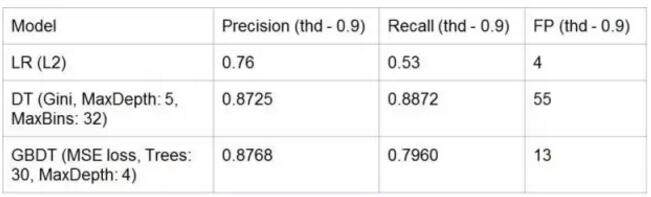
A1:我们使用了多钟方法进行了实验。实验效果如下图:
可以看得出来,准确率上 GBDT 是最好的。因此我们实际上使用的是 GBDT。然后,在这里我们使用的特征包括:

A2:深度分页受节点内存限制,对于几十万的结果的返回支持不能很充分;
聚集操作的计数上目前支持的是非精确的计数,使用时需要注意,例如上百万的 cardinality 误差在 1% 左右
Q3:链家总共的数据量大概是什么量级?
A3:参见我之前的分享内容哈。 日志数据 6T,成交数据超过百万,用户画像数量超过 2000 万。
Q4: 请问产品经理需要的临时的较特别的数据,如何提取?
A4: 看了车品觉的《决战大数据》后以及自己工作中得到的观点:
1) 临时需求我们需要接,因为这是做数据人的使命 2)我们需要有战斗小组能够将产品的需求进行抽象,从而落地在画像或者其他数据产品中。
讲师介绍
蔡白银,链家网大数据架构师,毕业于北京大学,负责链家网大数据体系的建设,运用大数据挖掘大数据价值助力房产领域的 O2O,提升房屋买卖体验,使得房产买卖不再难;在大数据数据挖掘领域有多年的经验。加入链家网之前就职于百度,负责百度口碑后端策略架构。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论