
报道称,DeepSeek 正在加速推出其 R2 人工智能模型,其最初计划在五月推出,但目前正在努力尽快推出。
而就在刚刚,DeepSeek 开源了 DeepGEMM,一个专为简洁高效的 FP8 通用矩阵乘法(GEMMs)设计的库,具有细粒度缩放功能(如 DeepSeek-V3 中提出的方案)。

该库采用 CUDA 编写,采用轻量级即时编译(JIT)模块,安装时无需编译(所有内核在运行时编译)。它支持普通 GEMMs 以及专家混合 (MoE) 分组 GEMMs。
目前,DeepGEMM 仅支持 NVIDIA Hopper 张量核心,该库使用 CUDA 核心两级累加(promotion)(晋升)策略来解决 FP8 张量核心累加不精确问题。尽管 DeepGEMM 借鉴了 CUTLASS 和 CuTe 的一些理念,但避免了过度依赖模板或复杂的代数结构。该库设计简洁,仅包含一个核心内核函数,代码大约只有 300 行左右。
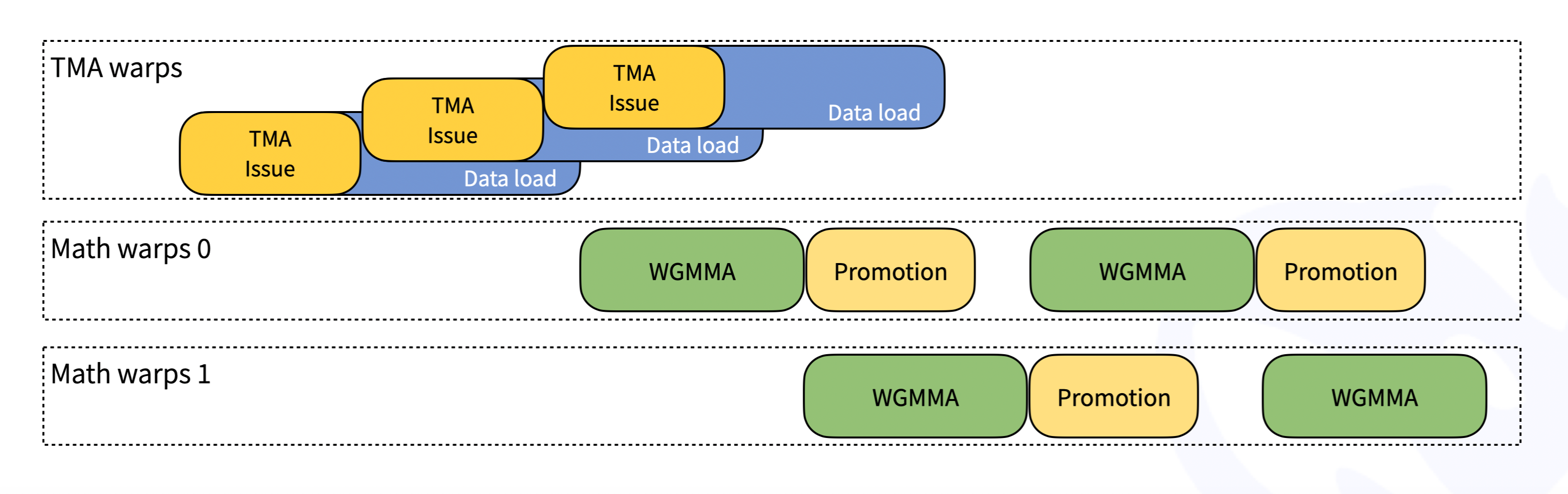
按照 CUTLASS 设计,DeepGEMM 中的内核经过了 warp 专门化,可实现重叠数据移动、张量核心 MMA 指令和 CUDA 核心提升。DeepGEMM 使用 TMA 加载 LHS、RHS 和缩放因子,以及存储输出矩阵。
尽管设计轻量,DeepGEMM 的性能在各种矩阵形状下均能匹配或超越经过专家调优的库。
DeepSeek 在配备 NVCC 12.8 的 H800 计算卡上对 DeepSeek-V3/R1 推理流程(包含预填充和解码阶段,除了张量并行场景)可能涉及的所有矩阵形状进行全量测试,所有加速性能指标均基于 CUTLASS 3.6 深度优化的内部实现作为基准对比。DeepGEMM 在部分特定矩阵形状上的性能表现仍有提升空间。
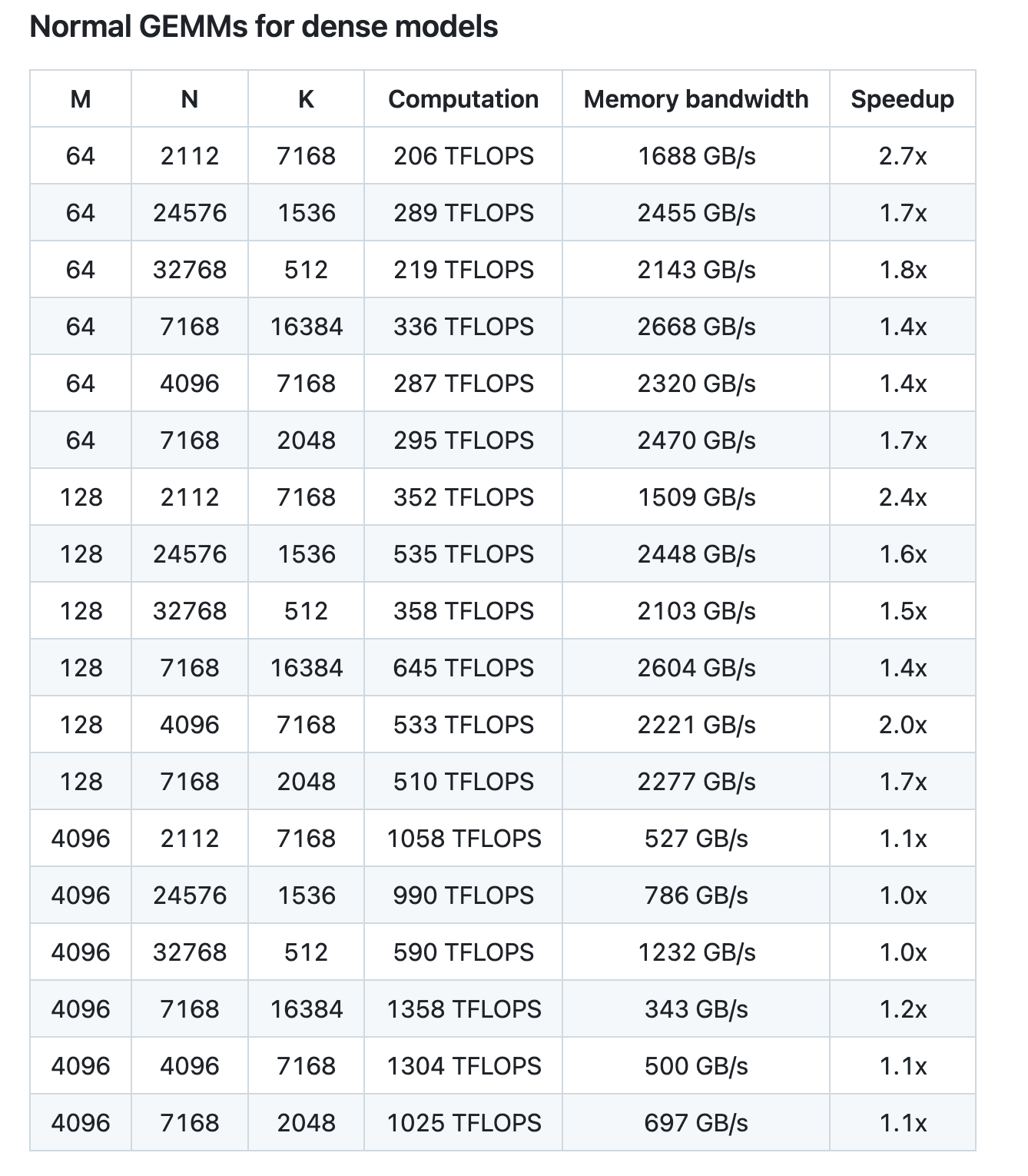
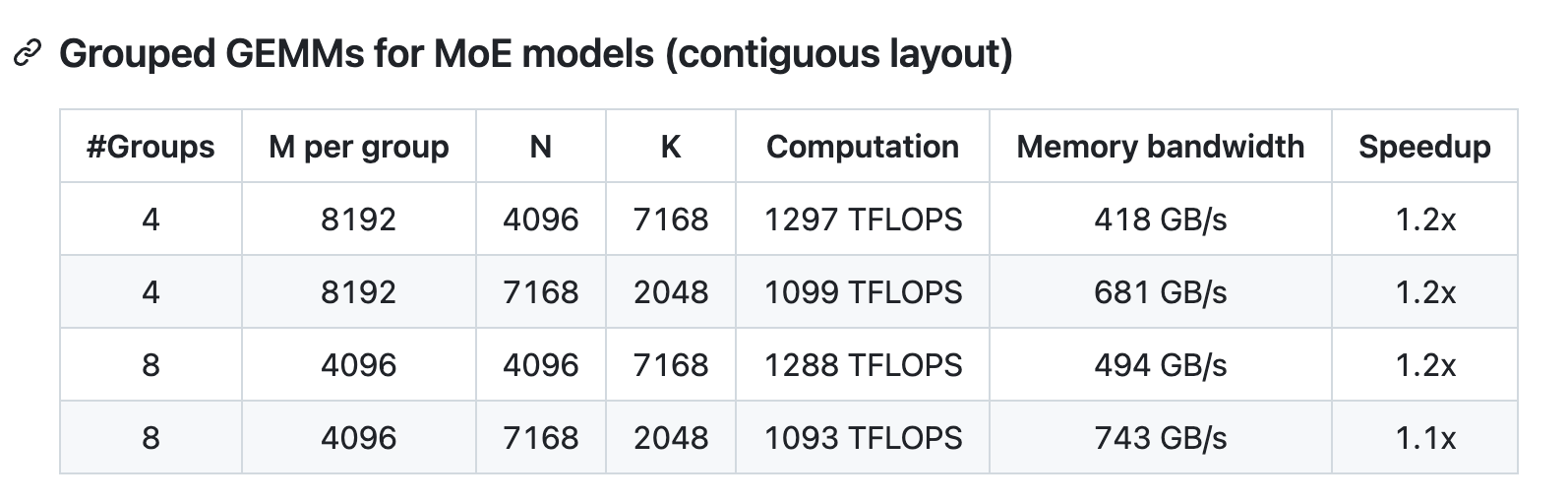
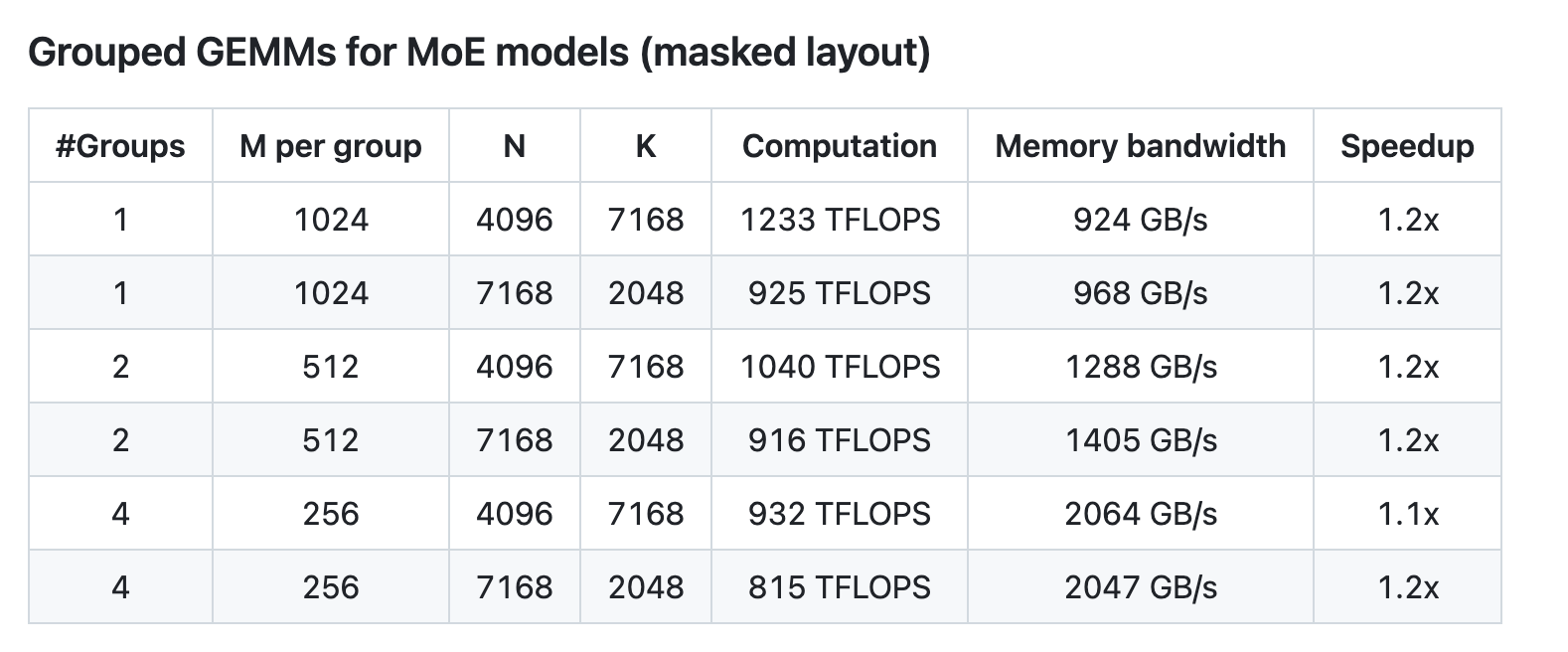
“虽然 FP8 在生产中还处于相对早期阶段,但 DeepGEMM 代表着在使 FP8 成为大规模 MoE 模型的可行选择方面迈出了重要一步。朋友们,这真是太酷了。”有网友评价。
使用要求:
Hopper 架构 GPU,sm_90a 必须支持
Python 3.8 或更高版本
CUDA 12.3 或更高版本(官方强烈建议使用 12.8 或更高版本)
PyTorch 2.1 或更高版本
CUTLASS 3.6 或更高版本(可以通过 Git 子模块克隆)
开源地址(MIT 许可证):




