大约在 5 年前 Olery 创立了,那时的 Olery 只有 Reputation 一个产品,同时还是由一个 Ruby 开发代理机构开发的,经过了几年的发展,现在的 Olery 除了 Reputation 产品之外还发布了很多其他的产品,包括:Olery Feedback、Hotel Review Data API 以及一些能够被嵌入到网页内的部件(widget),在不久的将来,Olery 将会提供更多的产品和服务。之所以能够取得如此巨大的成功,主数据库的作用可谓功不可没,那么 Olery 的数据库架构是如何演进的呢?最近 Yorick Peterse 在 Olery 的开发者网站上发表了一篇题为《再见MongoDB,你好PostgreSQL 》的文章对此进行了介绍,本文根据此文翻译整理而来,查看英文原文请点击这里。
最初,Olery 的数据库体系包含两部分:使用MySQL 存储关键数据(用户、通讯录等);使用MongoDB 存储评论以及其他与之相似的数据(丢失之后能够很容易找回的数据)。这种配置在刚开始的时候还能满足业务需要,但是随着公司的发展,问题就开始出现了,特别是对MongoDB 的使用,这其中有一些问题源于应用程序与数据库的交互方式,而另一些则源于数据库本身。
例如,在某个时间点Olery 必须从MongoDB 中移除大约一百万文档然后稍后再重新插入它们。这种处理方式造成的后果就是:数据库几乎会被完全锁定几个小时,性能非常低,除非使用MongoDB 的repairDatabase 命令执行数据库修复,但是由于数据库比较大,该修复命令也需要耗费数小时的时间。另一个例子是Olery 注意到应用程序糟糕的性能源于MongoDB 集群,但是却无法进一步找到问题的真实原因,无论配置什么指标、使用什么工具或者运行什么命令都找不到原因,直到Olery 替换了集群的主节点才让性能恢复正常。
这样的例子还有很多,其核心的问题不仅仅是数据库会出毛病,还包括当问题出现的时候用户完全无迹可寻。
无模式的问题
Olery 面对的另一个核心问题是 MongoDB 是无模式的。无模式听起来可能比较有趣,同时在某些情况下这样做也有一定的好处,但是大部分情况下使用无模式的存储引擎会引发隐式模式的问题。这些模式并不是由存储引擎定义的,而是基于应用程序的行为和期望定义的。
例如,你可能有一个页面集合,应用程序期望从中获取一个字符串类型的 title,这种情况下模式虽然没有明确定义,但也清晰可见。但是如果数据结构随着时间发生了变化,这种方式就会出现问题,特别是当旧数据没有迁移到新数据结构上的时候。例如,假设有下面的 Ruby 代码:
post_slug = post.title.downcase.gsub(/\W+/, '-')
这段代码适合所有包含 title 域的文档,但是如果文档使用了不同的域名称(例如 post_title),或者没有类似的 title 域,那么这样写就会出现问题。为了处理这种情况,必须将代码调整为下面这样:
if post.title
post_slug = post.title.downcase.gsub(/\W+/, '-')
else
# ...
end
处理该问题的另一种方式就是在模型中定义一个模式,例如使用 Mongoid。这样做还解决了另一个问题:可重用性。如果你只有一个应用程序,那么在代码中定义模式并不是大事,但是如果你有数十个应用程序,那么这样做很快就会成为一个大麻烦。
无模式存储引擎的期望是通过移除模式让用户使用起来更容易。实际上,用户需要自己确保数据的一致性。在某些情况下这种方式可能比较好,但是大部分情况下这可能是一个弊端。
一个优秀数据库的要求
针对以上问题以及自身的业务需要,Olery 认为应该从以下 4 个方面衡量一个数据库:
- 一致性
- 数据以及系统行为的可见性
- 正确性和清晰度(explicitness)
- 可扩展性
一致性是非常重要的,因为它能够帮助一个系统建立明确的期望。如果数据始终按照某种方式存储,那么使用这些数据的系统就会变得非常简单。如果某个域在数据库层面是必须的,那么应用程序就不需要检查该域的存在性。同时即使压力非常大,数据库也应该能够保证某些操作可以完成。
可见性包括两个方面:系统本身以及从系统中获取数据的简单程度。当系统出现问题的时候用户可以很容易地调试。另外,用户也可以很容易地检索到所需的数据。
正确性指系统的行为要符合期望。如果某个域被定义为数字类型,那么任何人都不能插入文本。众所周知,MySQL 在这一方面做的并不好,它没有阻止用户这么做,以致于数据中可能包含错误的内容。
可扩展性不仅指性能,还包括财务成本以及随着时间的推移系统是否能够很好地处理变化的需求。
远离 MongoDB
基于以上标准,Olery 开始寻找 MongoDB 的替代品,因为这些标准通常又是传统 RDBMS 的核心特性,所以 Olery 将目光移向了 MySQL 和 PostgreSQL。
MySQL 是第一个候选产品,之前 Olery 已经使用它存储了少量的关键数据。但是 MySQL 有它自己的问题,例如,即使一个域被定义为 int(11), 用户依然能够插入文本型的数据,MySQL 会进行转换:
mysql> create table example ( `number` int(11) not null );
Query OK, 0 rows affected (0.08 sec)
mysql> insert into example (number) values (10);
Query OK, 1 row affected (0.08 sec)
mysql> insert into example (number) values ('wat');
Query OK, 1 row affected, 1 warning (0.10 sec)
mysql> insert into example (number) values ('what is this 10 nonsense');
Query OK, 1 row affected, 1 warning (0.14 sec)
mysql> insert into example (number) values ('10 a');
Query OK, 1 row affected, 1 warning (0.09 sec)
mysql> select * from example;
+--------+
| number |
+--------+
| 10 |
| 0 |
| 0 |
| 10 |
+--------+
4 rows in set (0.00 sec)
虽然出现这种情况的时候 MySQL 会发出一个警告,但是这一信息通常会被忽略。
MySQL 的另一个问题就是所有的表修改(例如增加列)操作都会导致锁表,无论是读还是写。这意味着在修改完成之前对该表的所有操作都必须等待。如果表的数据量非常大,修改操作可能需要数小时才能完成,这可能导致应用程序停止服务。而这也是导致 SoundCloud 等公司开发 lhm 这种工具的原因。
鉴于以上原因,Olery 开始考察 PostgreSQL,与 MySQL 相比 PostgreSQL 能把很多事情做得更好。例如,用户无法将文本值插入到数字类型的域中:
olery_development=# create table example ( number int not null );
CREATE TABLE
olery_development=# insert into example (number) values (10);
INSERT 0 1
olery_development=# insert into example (number) values ('wat');
ERROR: invalid input syntax for integer: "wat"
LINE 1: insert into example (number) values ('wat');
^
olery_development=# insert into example (number) values ('what is this 10 nonsense');
ERROR: invalid input syntax for integer: "what is this 10 nonsense"
LINE 1: insert into example (number) values ('what is this 10 nonsen...
^
olery_development=# insert into example (number) values ('10 a');
ERROR: invalid input syntax for integer: "10 a"
LINE 1: insert into example (number) values ('10 a');
PostgreSQL 能够以多种方式对表进行改变,不是每一个操作都需要锁表。例如,添加一个没有默认值同时可以设置为 NULL 的列能够很快地完成,不需要锁定整个表。
PostgreSQL 还支持很多其他的特性,例如:基于三元模型(trigram)的索引和搜索、全文检索、支持查询 JSON、支持查询 / 存储键值对,支持 pub/sub 等。
最重要的是 PostgreSQL 在性能、可靠性、正确性和一致性方面做了很好的平衡。
使用 PostgreSQL
将整个平台从 MongoDB 迁移到一个完全不同的数据库上并不容易,为此,Olery 将整个过程分为了三步:
- 创建一个 PostgreSQL 数据库,将一小部分数据迁移过去
- 更新所有依赖于 MongoDB 的应用程序,使用 PostgreSQL 替代,并完成所有必须的重构工作
- 将生产数据迁移到新数据库并部署新平台
迁移子集
虽然有一些工具能够处理这项工作,但是依然需要对某些数据进行转换(例如重命名的域、类型的差异),此时需要编写自己的工具。这些工具大部分是一次性的 Ruby 脚本,每个脚本执行特定的任务,例如:挪动评论、清除编码、纠正主键序列等。
尽管在迁移的过程中有一部分数据存在问题——例如某些用户可能提交了错误编码的内容,导致在被清除之前无法被导入;评论的语言名称需要从全名(“dutch”、“english”等)修改为语言代码以适应新的情感分析栈的需要——但是该阶段并没有遇到任何阻碍迁移的麻烦。
更新应用程序
更新应用程序占用了大部分时间,特别是那些严重依赖于 MongoDB 聚合框架的程序。更新的过程分为下面几步:
- 使用 PostgreSQL 相关的代码替换 MongoDB 驱动 / 模型设置代码
- 运行测试
- 修复部分测试
- 再次运行测试,修改并重复直到所有的测试都通过
非 Rails 应用程序固定使用 Sequel,Rails 应用程序则摆脱不了 ActiveRecord。Sequel 是一个非常棒的数据库工具,它支持 Olery 可能会用到的大部分 PostgreSQL 特有的特性,虽然有时有一点繁琐,但是它的查询构建 DSL 远比 ActiveRecord 要强大。
例如,如果想计算有多少位用户在某个区域以及每个区域的百分比,那么普通的 SQL 可能会是这样:
SELECT locale,
count(*) AS amount,
(count(*) / sum(count(*)) OVER ()) * 100.0 AS percentage
FROM users
GROUP BY locale
ORDER BY percentage DESC;
在本文的例子中该 SQL 会产生下面的输出:
locale | amount | percentage
--------+--------+--------------------------
en | 2779 | 85.193133047210300429000
nl | 386 | 11.833231146535867566000
it | 40 | 1.226241569589209074000
de | 25 | 0.766400980993255671000
ru | 17 | 0.521152667075413857000
| 7 | 0.214592274678111588000
fr | 4 | 0.122624156958920907000
ja | 1 | 0.030656039239730227000
ar-AE | 1 | 0.030656039239730227000
eng | 1 | 0.030656039239730227000
zh-CN | 1 | 0.030656039239730227000
(11 rows)
Sequel 允许使用普通的 Ruby 编写上面的查询,不需要字符串片段 (ActiveRecord 通常会需要):
star = Sequel.lit('*')
User.select(:locale)
.select_append { count(star).as(:amount) }
.select_append { ((count(star) / sum(count(star)).over) * 100.0).as(:percentage) }
.group(:locale)
.order(Sequel.desc(:percentage))
如果不喜欢使用 Sequel.lit(’*’),还可以使用下面的语法:
User.select(:locale)
.select_append { count(users.*).as(:amount) }
.select_append { ((count(users.*) / sum(count(users.*)).over) * 100.0).as(:percentage) }
.group(:locale)
.order(Sequel.desc(:percentage))
虽然这两个查询可能有一点繁琐,但是却让我们能够更容易地部分重用,不需要使用字符串连接。
迁移生产数据
迁移生产数据基本上有两种方式:
- 关闭整个平台,待所有的数据都迁移完成之后再一次性上线
- 迁移数据的同时保持服务继续运行
第一种方法有一个明显的弊端:要停止服务。第二种方式虽然不需要停止服务但是非常难处理,例如,在迁移数据的同时必须考虑正在添加的所有数据,否则就会丢失数据。
幸运的是 Olery 对数据库的大部分写操作时间间隔都非常规律,确实会频繁变化的数据(用户、通讯录等)只占一小部分,这意味着迁移它们所需的时间要比迁移评论少的多。
该部分的基本流程是:
- 迁移关键数据(基本上包括所有绝对不能丢失的数据),例如用户、通讯录
- 迁移不太重要的数据(可以重新获取或计算的数据)
- 测试所有的事情是否都已完成并运行在一组单独的服务器上
- 切换生产环境到这些新服务器上
- 重新迁移第一步的数据,确保没有丢失这期间创建的数据
第 2 步花费的时间最长,差不多需要 24 小时,第 1 步和第 5 步中提到的数据迁移仅需要大约 45 分钟。
结论
Olery 大约在一个月之前就完成了迁移,目前来看除了一些积极的影响之外没有其他副作用,某些场景下对性能的提升甚至非常显著。例如 Hotel Review Data API(运行在 Sinatra 上)的响应时间明显缩短了:
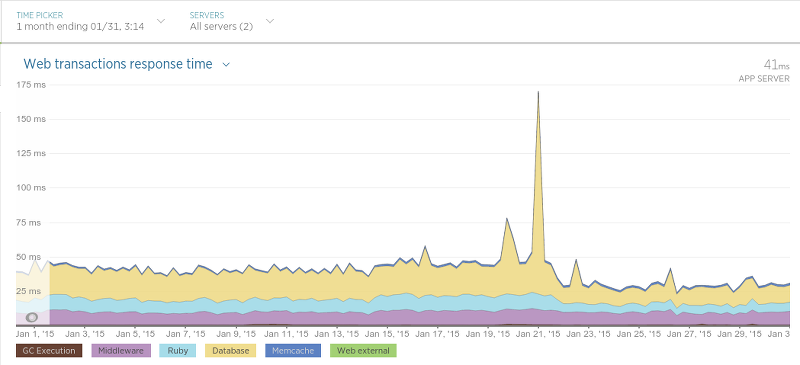
迁移发生在 1 月 21 号,大峰值是因为应用程序执行了重启,导致其响应时间非常长,但是在 21 号之后平均响应时间几乎降低了一半。
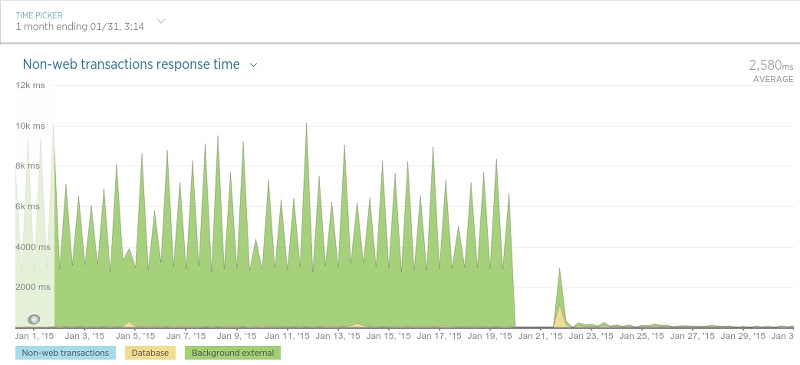
另外,“评论持久化”部分的性能提升也非常显著。该应用程序的责任非常简单:保存评论数据。虽然 Olery 最终对该应用程序作了非常大的改变以便于完成迁移,但是这些改变非常值得:
Scraper 也变得更快了:
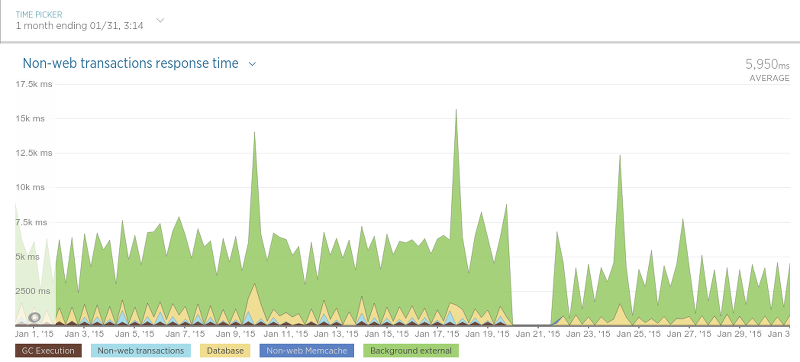
虽然提升没有评论持久化部分那么明显,但是考虑到 Scraper 只使用一个数据库检查某条评论是否存在,这种提升也非常令人兴奋。
最后是 Scraper 的调度程序 Scheduler:
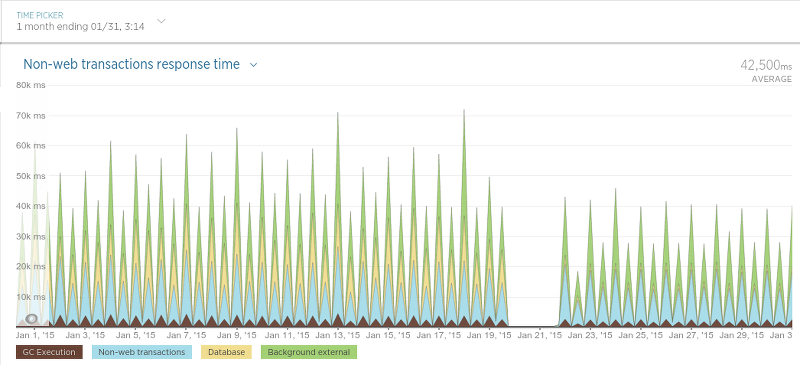
因为 Scheduler 会按照一定的时间间隔执行,所以这幅图理解起来有点难,但是非常明显的是在迁移之后平均处理时间降低了。
到目前为止 Olery 对于这次迁移非常满意,性能非常好,与之相关的工具也优于其他数据库,查询体验也比 MongoDB 要好得多。虽然 Olery 依然有一个服务(Olery Feedback)在使用 MongoDB,但是相信不久之后便会迁移到 PostgreSQL 上。
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流。




