在 2016 LighLoad++ 大会上,“M-Tex”的开发经理 Vadim Madison 讲述了从一个由数百个微服务组成的系统到包含数千个微服务的高负载项目的发展历程。本文已获得翻译授权,查看英文原文: Microservices in a High-Load Project 。
我将告诉大家我们是如何开始一个高负载微服务项目的。在讲述我们的经历之前,先让我们简单地自我介绍一下。
简单地说,我们从事视频输出方面的工作——我们提供实时的视频。我们负责“NTV-Plus”和“Match TV”频道的视频平台。该平台有 30 万的并发用户,每小时输出 300TB 的内容。这是一个很有意思的任务。那么我们是如何做到的呢?
这背后都有哪些故事?这些故事都是关于项目的开发和成长,关于我们对项目的思考。总而言之,是关于如何提升项目的伸缩能力,承受更大的负载,在不宕机和不丢失关键特性的情况下为客户提供更多的功能。我们总是希望能够满足客户的需求。当然,这也涉及到我们是如何实现这一切,以及这一切是如何开始的。
在最开始,我们有两台运行在 Docker 集群里的服务器,数据库运行在相同机器的容器里。没有专用的存储,基础设施非常简单。
我们就是这样开始的,只有两台运行在 Docker 集群里的服务器。那个时候,数据库也运行在同一个集群里。我们的基础设施里没有什么专用的组件,十分简单。

我们的基础设施最主要的组件就是 Docker 和 TeamCity,我们用它们来交付和构建代码。
在接下来的时期——我称其为我们的发展中期——是我们项目发展的关键时期。我们拥有了 80 台服务器,并在一组特殊的机器上为数据库搭建了一个单独的专用集群。我们开始使用基于 CEPH 的分布式存储,并开始思考服务之间的交互问题,同时要更新我们的监控系统。
现在,让我们来看看我们在这一时期都做了哪些事情。Docker 集群里已经有数百台服务器,微服务就运行在它们上面。这个时候,我们开始根据数据总线和逻辑分离原则将我们的系统拆分成服务子系统。当微服务越来越多时,我们决定拆分我们的系统,这样维护起来就容易得多(也更容易理解)。
(点击放大图像)

这张图展示的是我们系统其中的一小部分。这部分系统负责视频剪切。半年前,我在“RIT++”也展示过类似的图片。那个时候只有17 个绿色的微服务,而现在有28 个绿色的微服务。这些服务只占我们整个系统的二十分之一,所以可以想象我们系统大致的规模有多大。
深入细节
服务间的通信是一件很有趣的事情。一般来说,我们应该尽可能提升服务间通信效率。我们使用了 protobuf ,我们认为它就是我们需要的东西。
它看起来是这样的:
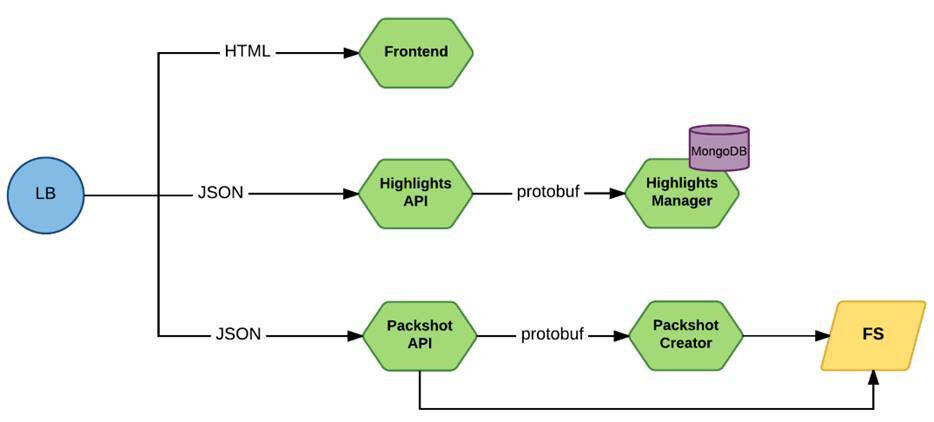
微服务的前面有一个负载均衡器。请求到达前端,或者直接发送给提供了 JSON API 的服务。protobuf 被用于内部服务之间的交互。
protobuf 真是一个好东西。它为消息提供了很好的压缩率。现如今有很多框架,只要使用很小的开销就能实现序列化和反序列化。我们可以将其视为有条件的请求类型。
但如果从微服务角度来看,我们会发现,微服务之间也存在某种私有的协议。如果只有一两个或者五个微服务,我们可以为每个微服务打开一个控制台,通过它们来访问微服务,并获得响应结果。如果出现了问题,我们可以对其进行诊断。不过这在一定程度上让微服务的支持工作变得复杂。
在一定时期内,这倒不是什么问题,因为并没有太多的微服务。另外,Google 发布了 gRPC 。在那个时候,gRPC 满足了所有我们想做的事情。于是我们逐渐迁移到 gRPC。于是我们的技术栈里出现了另一个组件。

实现的细节也是很有趣的。gRPC 默认是基于 HTTP/2 的。如果你的环境相对稳定,应用程序不怎么发生变更,也不需要在机器间迁移,那么 gRCP 对于你来说就是个不错的东西。另外,gRPC 支持很多客户端和服务器端的编程语言。
现在,我们从微服务角度来看待这个问题。从一方面来看,gRPC 是一个好东西,但从另一方面来看,它也有不足之处。当我们开始对日志进行标准化(这样就可以将它们聚合到一个独立的系统里)时,我们发现,从 gRPC 中抽取日志非常麻烦。
于是,我们决定开发自己的日志系统。它解析消息,并将它们转成我们需要的格式。这样我们才可以获得我们想要的日志。还有一个问题,添加新的微服务会让服务间的依赖变得更加复杂。这是微服务一直存在的问题,这也是除版本问题之外的另一个具有一定复杂性的问题。
于是,我们开始考虑使用 JSON。在很长的一段时间里,我们无法相信,在使用了紧凑的二进制协议之后会转回使用 JSON。有一天,我们看到一篇文章,来自 DailyMotion 的一个家伙在文章里提到了同样的事情:“我们知道该如何使用 JSON,每个人都可以使用 JSON。既然如此,为什么还要自寻烦恼呢?”

于是,我们逐渐从 gRPC 转向我们自己实现的 JSON。我们保留了 HTTP/2,它与 JSON 组合起来可以带来更快的速度。
现在,我们具备了所有必要的特性。我们可以通过 cURL 访问我们的服务。我们的 QA 团队使用 Postman ,所以他们也感觉很满意。一切都变得简单起来。这是一个有争议性的决定,但却为我们带来了很多好处。
JSON 唯一的缺点就是它的紧凑性不足。根据我们的测试结果,它与 MessagePack 之间有 30% 的差距。不过对于一个支持系统来说,这不算是个大问题。
况且,我们在转到 JSON 之后还获得了更多的特性,比如协议版本。有时候,当我们在新版本的协议上使用 protobuf 时,客户端也必须改用 protobuf。如果你有数百个服务,就算只有 10% 的服务进行了迁移,这也会引起很大的连锁反应。你在一个服务上做了一些变更,就会有十多个服务也需要跟着改动。
因此,我们就会面临这样的一种情况,一个服务的开发人员已经发布了第五个、第六个,甚至第七个版本,但生产环境里仍然在运行第四个版本,就因为其他相关服务的开发人员有他们自己的优先级和截止日期。他们无法持续地更新他们的服务,并使用新版本的协议。所以,新版本的服务虽然发布了,但还派不上用场。然后,我们却要以一种很奇怪的方式来修复旧版本的 bug,这让支持工作变得更加复杂。
最后,我们决定停止发布新版本的协议。我们提供协议的基础版本,可以往里面添加少量的属性。服务的消费者开始使用 JSON schema。
标准看起来是这样的:

我们没有使用版本 1、2 和 3,而是只使用版本 1 和指向它的 schema。
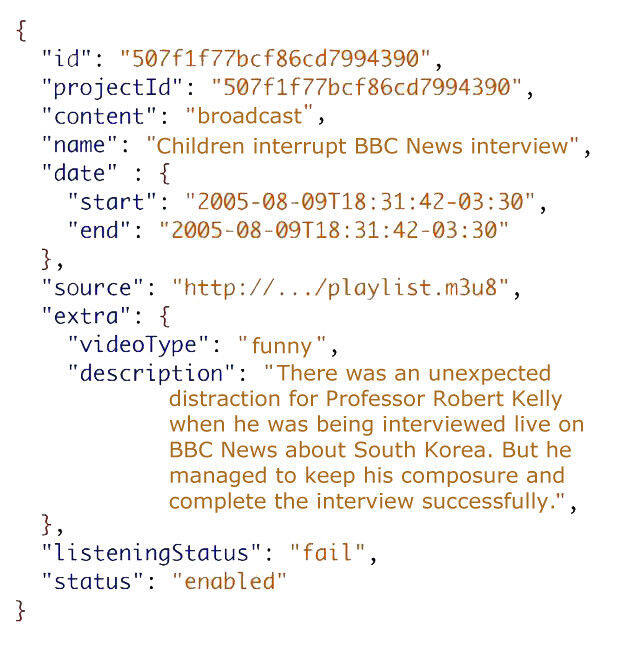
这是从我们服务返回的一个典型的响应结果。它是一个内容管理器,返回有关广播的信息。这里有一个消费者 schema 的例子。

最底下的字符串最有意思,也就是"required"那块。我们可以看到,这个服务只需要 4 个字段——id、content、date 和 status。如果我们使用了这个 schema,那么消费者就只会得到这样的数据。

它们可以被用在每一个协议版本里,从第一个版本到后来的每一个变更版本。这样,在版本之间迁移就容易很多。在我们发布新版本之后,客户端的迁移就会简单很多。
下一个重要的议题是系统的稳定性问题。这是微服务和其他任何一个系统都需要面临的问题(在微服务架构里,我们可以更强烈地感觉到它的重要性)。系统总会在某个时候变得不稳定。
如果服务间的调用链只包含了一两个服务,那么就没有什么问题。在这种情况下,你看不出单体和分布式系统之间有多大区别。但当调用链里包含了 5 到 7 个调用,那么问题就会接踵而至。你根本不知道为什么会这样,也不知道能做些什么。在这种情况下,调试会变得很困难。在单体系统里,你可以通过逐步调试来找出错误。但对于微服务来说,网络不稳定性或高负载下的性能不稳定性也会对微服务造成影响。特别是对于拥有大量节点的分布式系统来说,这些情况就更加显而易见了。
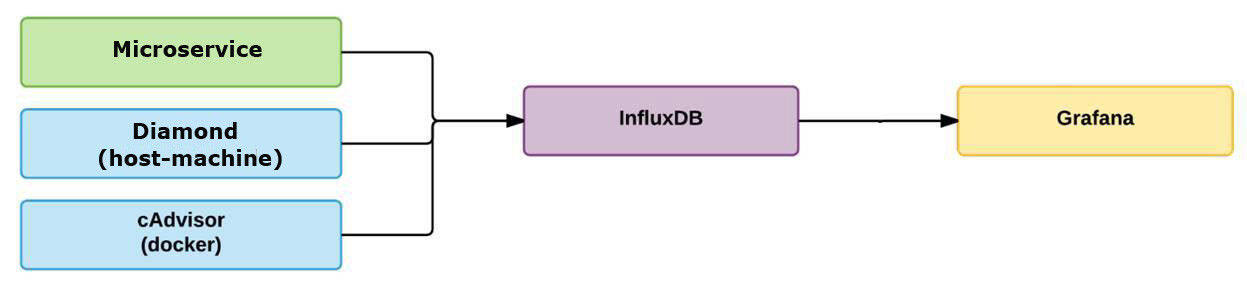
在一开始,我们采用了传统的办法。我们监控所有的东西,查看问题和问题的发生点,然后尝试尽快修复它们。我们将微服务的度量指标收集到一个独立的数据库里。我们使用 Diamond 来收集系统度量指标。我们使用 cAdvisor 来分析容器的资源使用情况和性能特征。所有的结果都被保存到 InfluxDB ,然后我们在 Grafana 里创建仪表盘。

于是,我们现在的基础设施里又多了三个组件。
我们比以往更加关注所发生的一切。我们对问题的反应速度更快了。不过,这并没有阻止问题的出现。
奇怪的是,微服务架构的主要问题出在那些不稳定的服务上。它们有的今天运行正常,明天就不行,而且有各种各样的原因。如果服务出现超载,而你继续向它发送负载,它就会宕机一段时间。如果它在一段时间不提供服务,负载就会下降,然后它就又活过来了。这类系统很难维护,也很难知道到底出了什么问题。
最后,我们决定把这些服务停掉,而不是让它们来回折腾。我们因此需要改变服务的实现方式。
我们做了一件很重要的事情。我们对每个服务接收的请求数量设定了一个上限。每个服务知道自己可以处理多少个来自客户端的请求(我们稍后会详细说明)。如果请求数量达到上限,服务将抛出 503 Service Unavailable 异常。客户端知道这个节点无法提供服务,就会选择另一个节点。
当系统出现问题时,我们就可以通过这种方式来减少请求时间。另外,我们也提升了服务的稳定性。
我们引入了第二种模式——回路断路器(Circuit Breaker)。我们在客户端实现了这种模式。
假设有一个服务 A,它有 4 个可以访问的服务 B 的实例。它向注册中心索要服务 B 的地址:“给我这些服务的地址”。它得到了服务 B 的 4 个地址。服务 A 向第一个服务 B 的实例发起了请求。第一个服务 B 实例正常返回响应。服务 A 将其标记为可访问:“是的,我可以访问它”。然后,服务 A 向第二个服务 B 实例发起请求,不过它没有在期望的时间内得到响应。我们禁用了这个实例,然后向下一个实例发起请求。下一个实例因为某些原因返回了不正确的协议版本。于是我们也将其禁用,然后转向第四个实例。
总得来说,只有一半的服务能够为客户端提供服务。于是服务 A 将会向能够正常返回响应的两个服务发起请求。而另外两个无法满足要求的实例被禁用了一段时间。
我们通过这种方式来提升性能的稳定性。如果服务出现了问题,我们就将其关闭,并发出告警,然后尝试找出问题所在。
因为引入了回路断路器模式,我们的基础设施里又多了一个组件—— Hystrix 。
Hystrix 不仅实现了回路断路器模式,它也有助于我们了解系统里出现了哪些问题:
(点击放大图像)

圆环的大小表示服务与其他组件之间的流量大小。颜色表示系统的健康状况。如果圆环是绿色的,那么说明一切正常。如果圆环是红色的,那么就有问题了。
如果一个服务应该被停掉,那么它看起来是这个样子的。圆环是打开的。
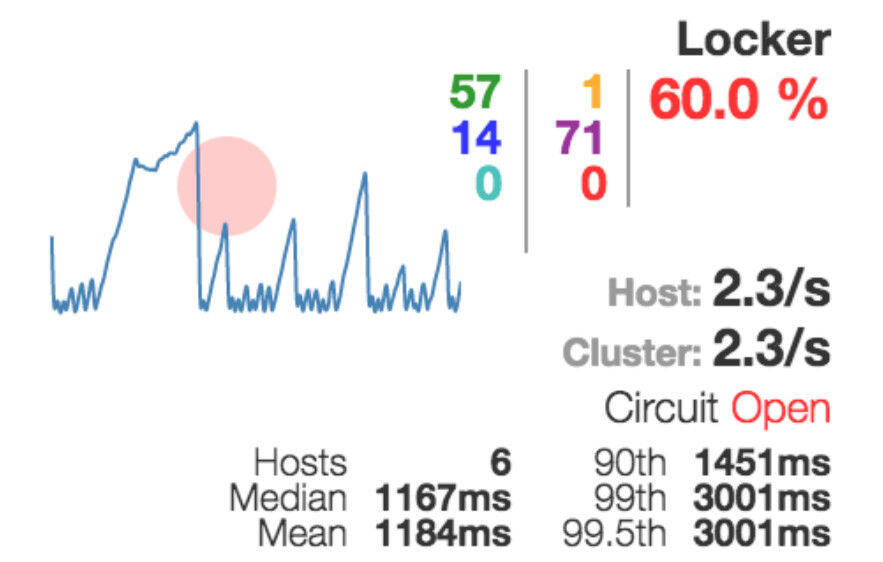
我们的系统变得相对稳定。每个服务至少都有两个可用的实例,这样我们就可以选择停掉其中的一个。不过,尽管是这样,我们仍然不知道我们的系统究竟发生了什么问题。在处理请求期间如果出现了问题,我们应该怎样才能知道问题的根源是什么呢?
这是一个标准的请求:
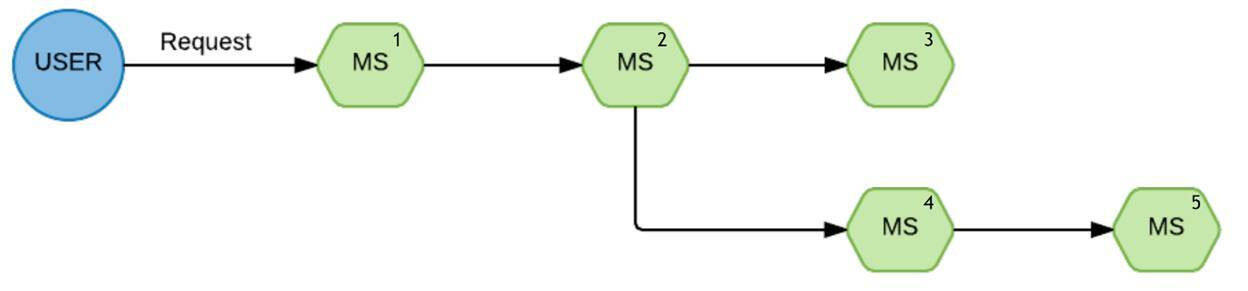
这是一个处理链条。用户发送请求到第一个服务,然后是第二个。从第二个服务开始,链条将请求发送到第三个和第四个服务。

然后一个分支不明原因地消失了。在经历了这类场景之后,我们尝试着提升这种场景的可见性,于是我们找到了Appdash。Appdash 是一个跟踪服务。
它看起来是这个样子的:
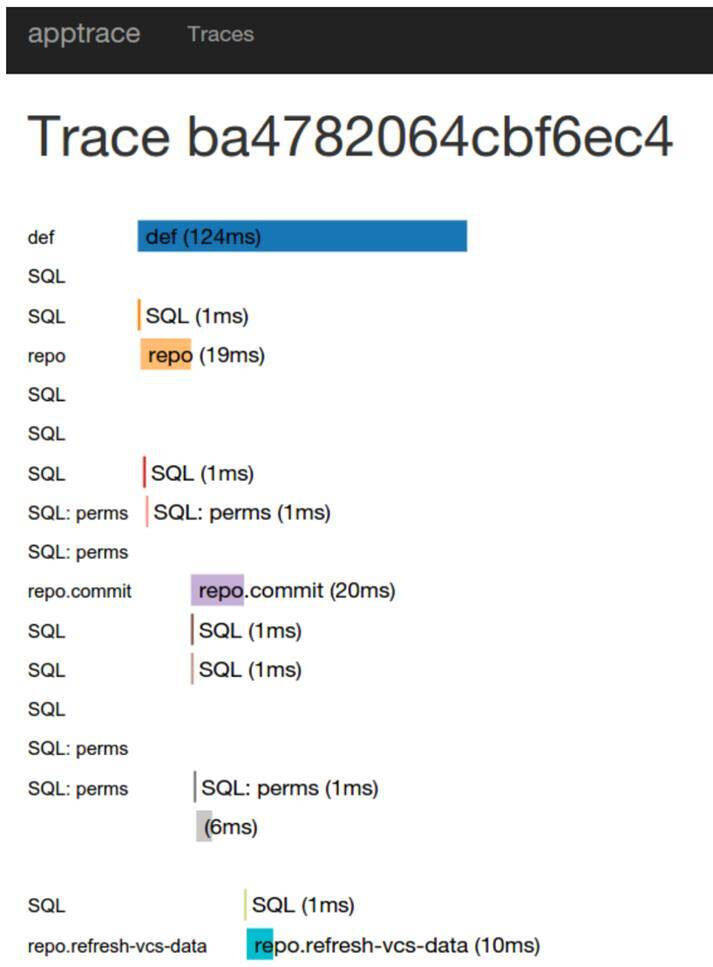
可以这么说,我们只是想尝试一下,看看它是否适合我们。将它用在我们的系统里是一件很容易的事情,因为我们那个时候使用的是Go 语言。Appdash 提供了一个开箱即用的包。我们认为Appdash 是一个好东西,只是它的实现并不是很适合我们。
于是,我们决定使用 Zipkin 来代替Appdash。Zipkin 是由 Twitter 开源的。它看起来是这个样子的:
(点击放大图像)

我认为这样会更清楚一些。我们可以从中看到一些服务,也可以看到我们的请求是如何通过请求链的,还可以看到请求在每个服务里都做了哪些事情。一方面,我们可以看到服务的总时长和每个分段的时长,另一方面,我们完全可以添加描述服务内容的信息。
我们可以在这里添加一些与数据库的调用、文件系统的读取、缓存的访问有关的信息,这样就可以知道请求里哪一部分使用了最多的时间。TraceID 可以帮助我们做到这一点。稍后我会介绍更多细节。
我们就是通过这种方式知道请求在处理过程中发生了什么问题,以及为什么有时候无法被正常处理。刚开始一切都正常,然后突然间,其中的一个出现了问题。我们稍作排查,就知道出问题的服务发生了什么。
不久前,一些厂商推出了一个跟踪系统的标准。为了简化系统的实现,主要的几个跟踪系统厂商在如何设计客户端API 和客户端类库上达成了一致。现在已经有了 OpenTracing 的实现,支持几乎所有的主流开发语言。现在就可以使用它了。
我们已经有办法知道那些突然间崩溃的服务。我们可以看到其中的某部分在垂死挣扎,但是不知道为什么。光有环境信息是不够的,
我们还需要日志。是的,这应该成为标准的一部分,它就是 Elasticsearch、Logstash 和 Kibana(ELK)。不过我们对它们做了一些改动。
我们并没有将大量的日志直接通过 forward 传给 Logstash,而是先传给 syslog ,让它把日志聚合到构建机器上,然后再通过 forward 导入到Elasticsearch和Kibana。这是一个很标准的流程,那么巧妙的地方在哪里呢?
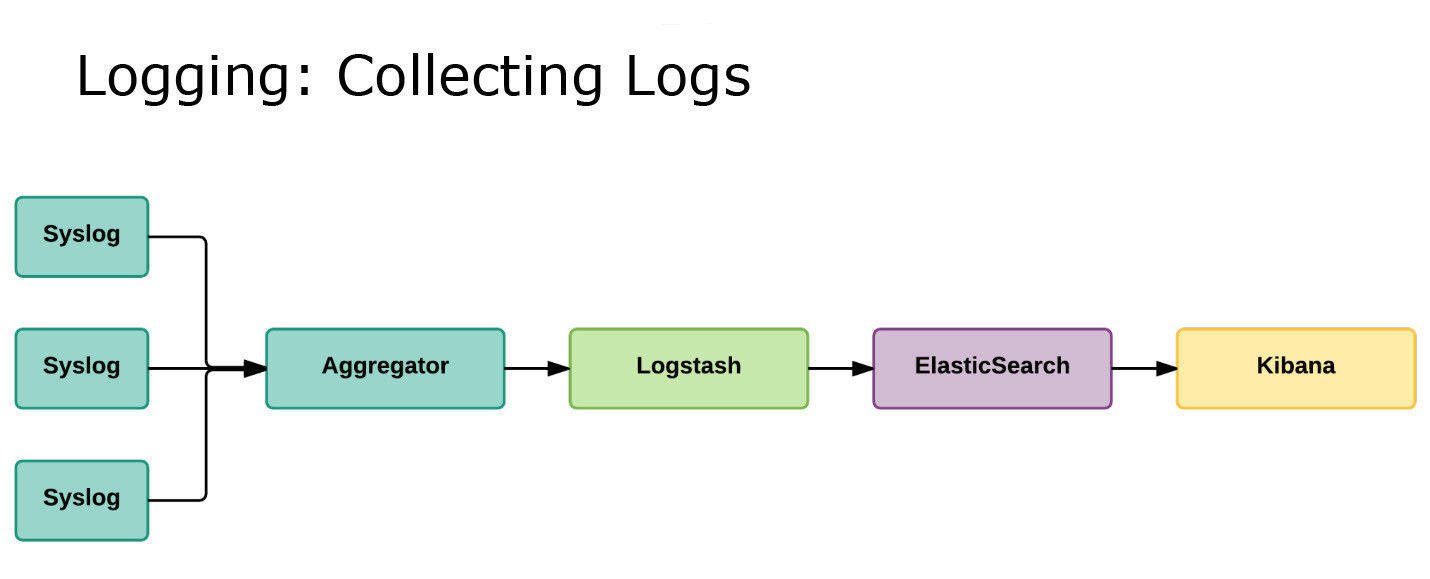
巧妙的是,我们可以在任何可能的地方往日志里加入 Zipkin 的 TraceID。
这样一来,我们就可以在 Kibana 仪表盘上看到完整的用户请求执行情况。也就是说,一旦服务进入生产环境,就为运营做好了准备。它已经通过了自动化测试,如果有必要,QA 可以再进行手动检查。它应该没有什么问题。如果它出现了问题,那说明有一些先决条件没有得到满足。日志里详细地记录了这些先决条件,通过过滤,我们可以看到某个请求的跟踪信息。我们因此可以快速地查出问题的根源,为我们节省了很多时间。
我们后来引入了动态调试模式。现在的日志数量还不是很大,大概只有 100 GB 到 150 GB,我记不太清楚具体数字了。不过,这些日志是在正常的日志模式下生成的。如果我们添加更多的细节,那么日志就可能变成 TB 级别的,处理起来就很耗费资源。
当我们发现某些服务出现问题,就打开调试模式(通过一个 API),看看发生了什么事情。有时候,我们找到出现问题的服务,在不将它关闭的情况下打开调试模式,尝试找出问题所在。
最后,我们在 ELK 端查找问题。我们还对关键服务的错误进行聚合。服务知道哪些错误是关键性的,哪些不是关键性的,然后将它们传给 Sentry 。
Sentry 能够智能地收集错误日志,并形成度量指标,还会进行一些基本的过滤。我们在很多服务上使用了 Sentry。我们从单体应用时期就开始使用它了。
那么最有趣的问题是,我们是如何进行伸缩的?这里需要先介绍一些概念。我们把每个机器看成一个黑盒。
我们有一个编排系统,最开始使用 Nomad 。确切地说,应该是 Ansible 。我们自己编写脚本,但光是这些还不能满足要求。那个时候,Nomad 的某些版本可以简化我们的工作,于是我们决定迁移到 Nomad。
同时还使用了 Consul ,将它作为服务发现的注册中心。还有 Vault,用于存储敏感数据,比如密码、秘钥和其他所有不能保存在 Git 上的东西。
这样,所有的机器几乎都变得一模一样。每个机器上都安装了Docker,还有Consul和Nomad代理。总的来说,每一个机器都处于备用状态,可以在任何时候投入使用。如果不用了,我们就让它们下线。如果你构建了云平台,你就可以先准备好机器,在高峰期时将它们打开,在负载下降时将它们关闭。这会节省大量的成本。
后来,我们决定从Nomad迁移到 Kubernetes ,Consul也因此成为了集中式的配置系统。
这样一来,部分栈可以进行自动伸缩。那么我们是怎么做的呢?
第一步,我们对内存、CPU 和网络进行限制。
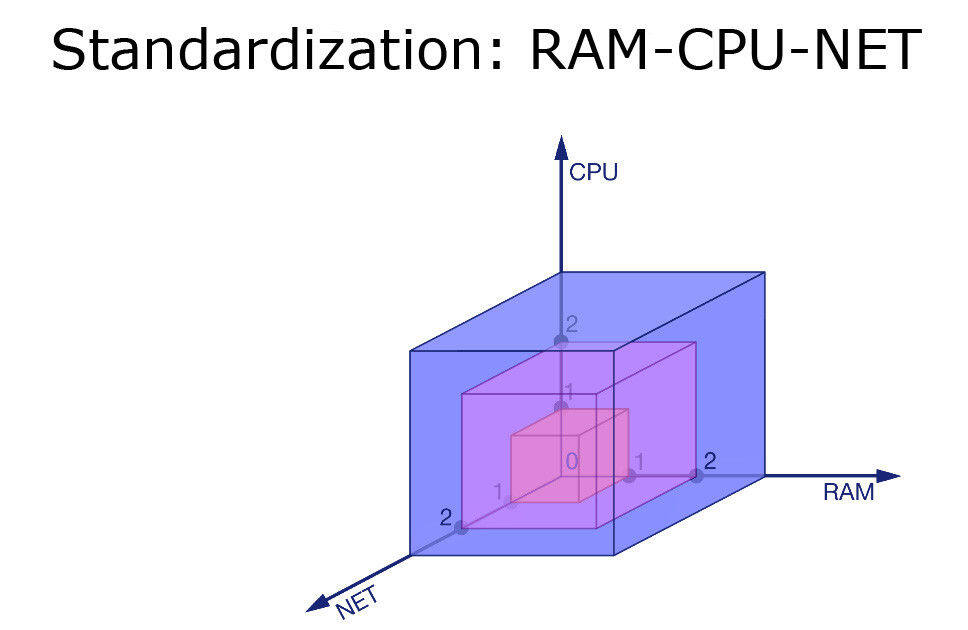
我们分别将这三个元素分成三个等级,砍掉其中的一部分。例如,
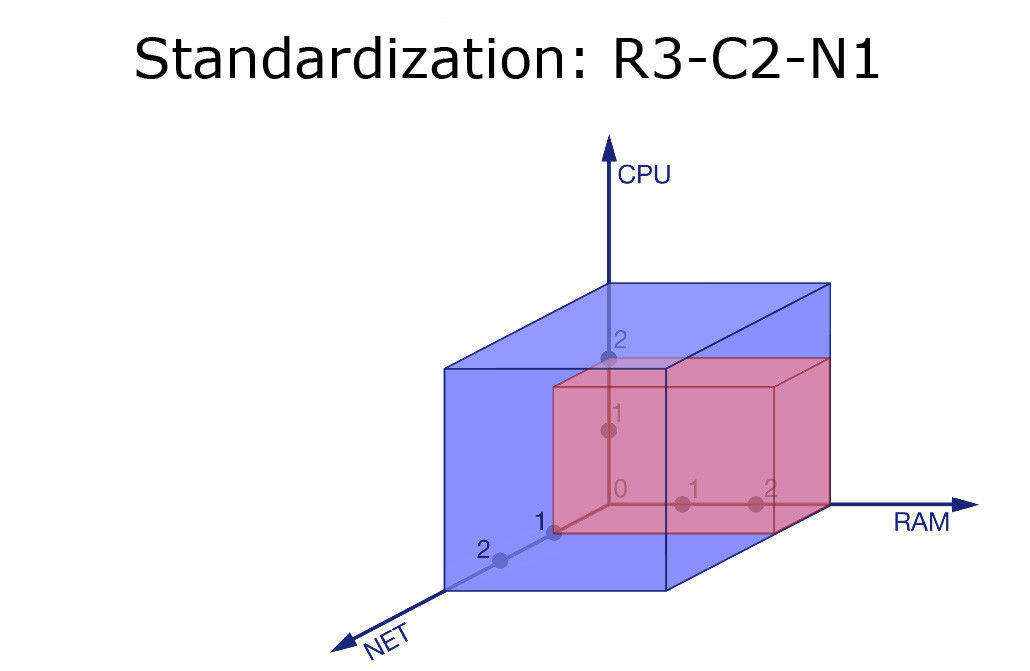
R3-C2-N1,我们已经限定只给某个服务一小部分网络流量、多一点点的 CPU 和更多的内存。这个服务真的很耗费资源。
我们在这里使用了助记符,我们的决策服务可以设置很多的组合值,这些值看起来是这样的:
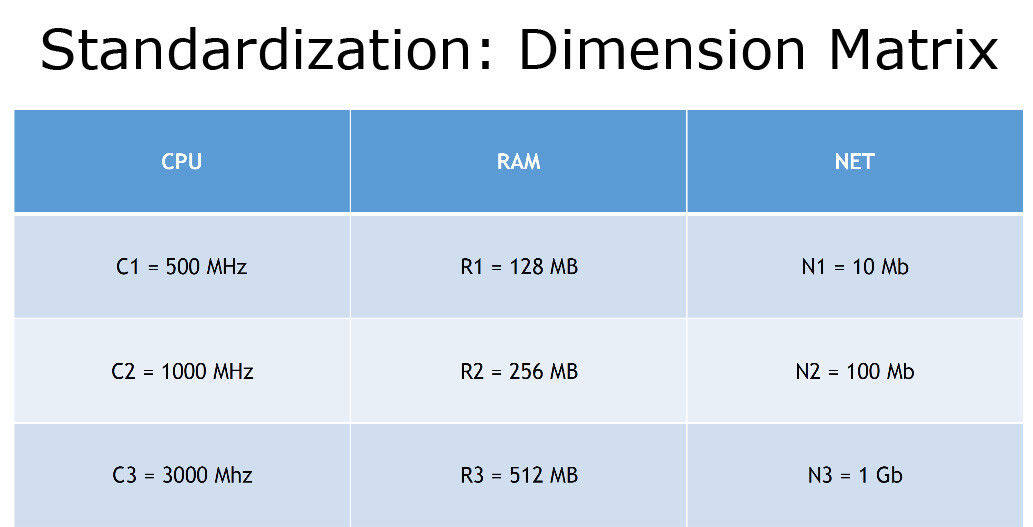
事实上,我们还有 C4 和 R4,不过它们已经超出了这些标准的限制。标准看起来是这样的:

下一步开始做一些预备工作。我们先确定服务的伸缩类型。
独立的服务最容易伸缩,它可以进行线性地伸缩。如果用户增长了两倍,我们就运行两倍的服务实例。这就万事大吉了。
第二种伸缩类型:服务依赖了外部的资源,比如那些使用了数据库的服务。数据库有它自己的容量上限,这个一定要注意。你还要知道,如果系统性能出现衰退,就不应该再增加更多的实例,而且你要知道这种情况会在什么时候发生。
第三种情况是,服务受到外部系统的牵制。例如,外部的账单系统。就算运行了 100 个服务实例,它也没办法处理超过 500 个请求。我们要考虑到这些限制。在确定了服务类型并设置了相应的标记之后,是时候看看它们是如何通过我们的构建管道的。
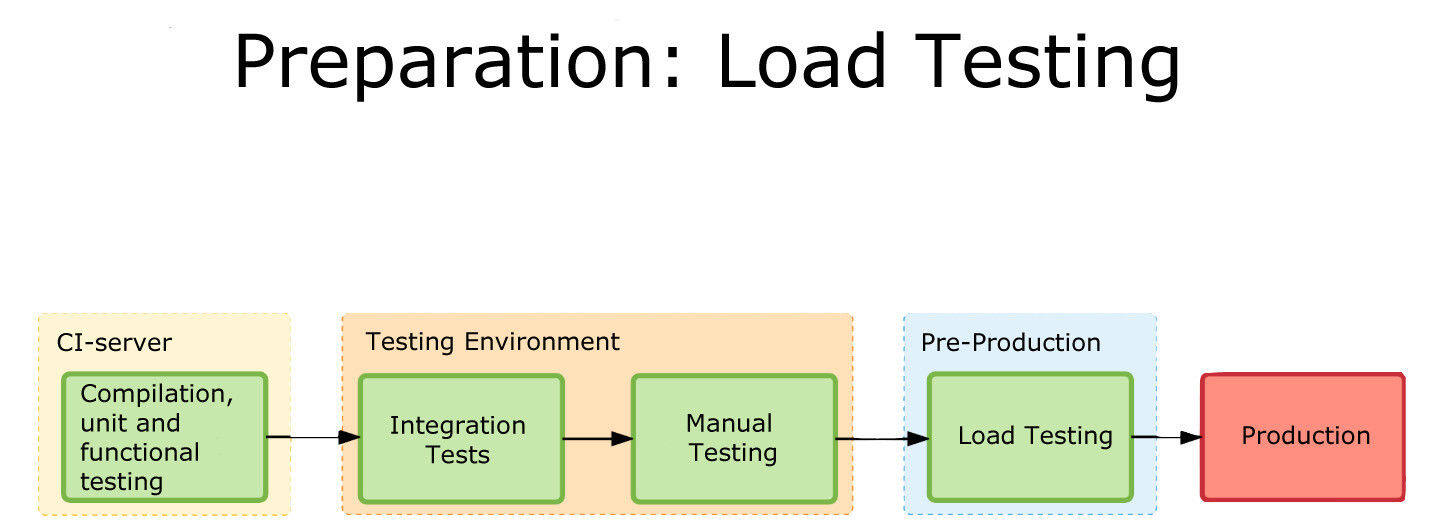
我们在 CI 服务器上运行了一些单元测试,然后在测试环境运行集成测试,我们的 QA 团队会对它们做一些检查。在这之后,我们就进入了预生产环境的负载测试。
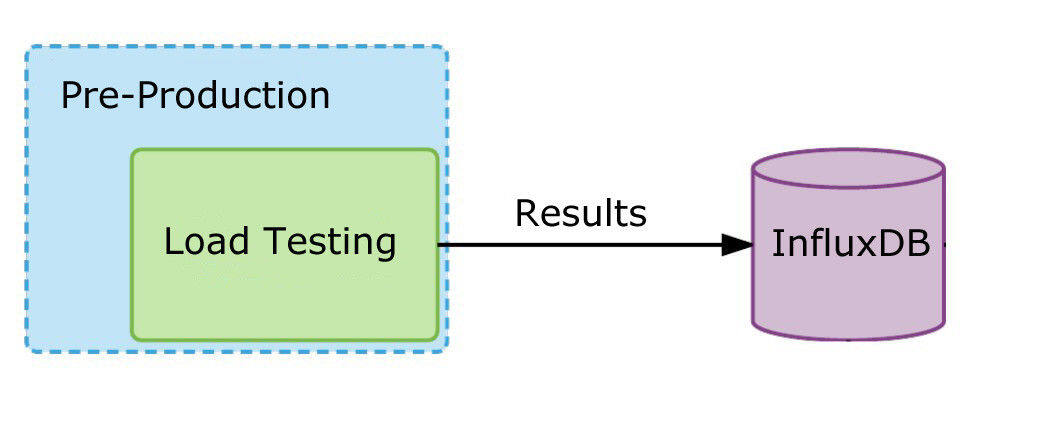
如果是第一种类型的服务,我们使用一个实例,并在这个环境里运行它,给它最大的负载。在运行了几轮之后,我们取其中的最小值,将它存入InfluxDB,将它作为该服务的负载上限。
如果是第二种类型的服务,我们逐渐加大负载,直到出现了性能衰退。我们对这个过程进行评估,如果我们知道该系统的负载,那么就比较当前负载是否已经足够,否则,我们就会设置告警,不会把这个服务发布到生产环境。我们会告诉开发人员:“你们需要分离出一些东西,或者加进去另一个工具,让这个服务可以更好地伸缩。”
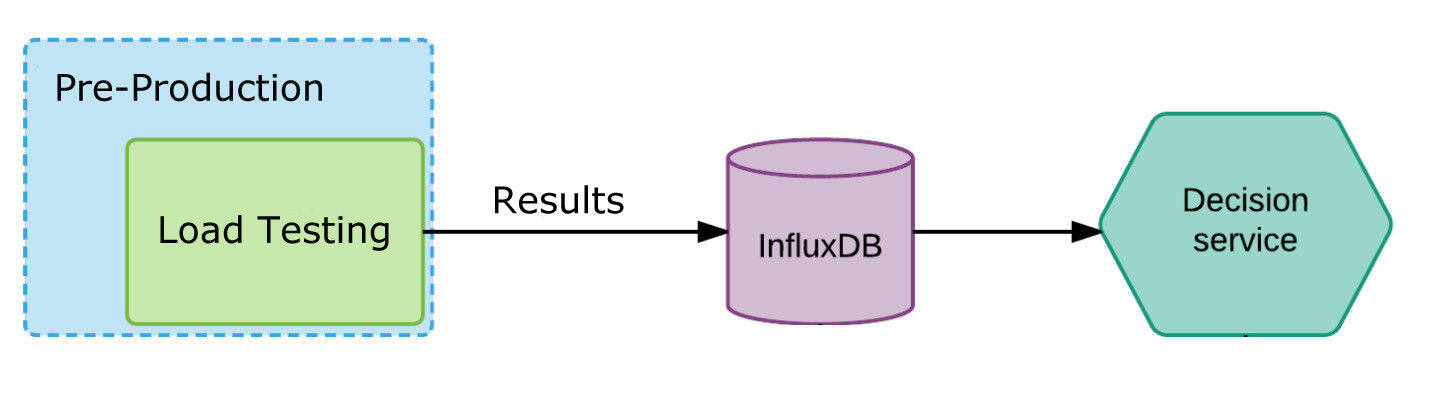
因为我们知道第三种类型服务的上限,所以我们只运行一个实例。我们也会给它一些负载,看看它可以服务多少个用户。如果我们知道账单系统的上限是 1000 个请求,并且每个服务实例可以处理 200 个请求,那么就需要 5 个实例。
我们把这些信息都保存到了 InfluxDB。我们的决策服务开始派上用场了。它会检查两个边界:上限和下限。如果超出了上限,那么就应该增加服务实例。如果超出下限,那么就减少实例。如果负载下降(比如晚上的时候),我们就不需要这么多机器,可以减少它们的数量,并关掉一部分机器,省下一些费用。
整体看起来是这样的:
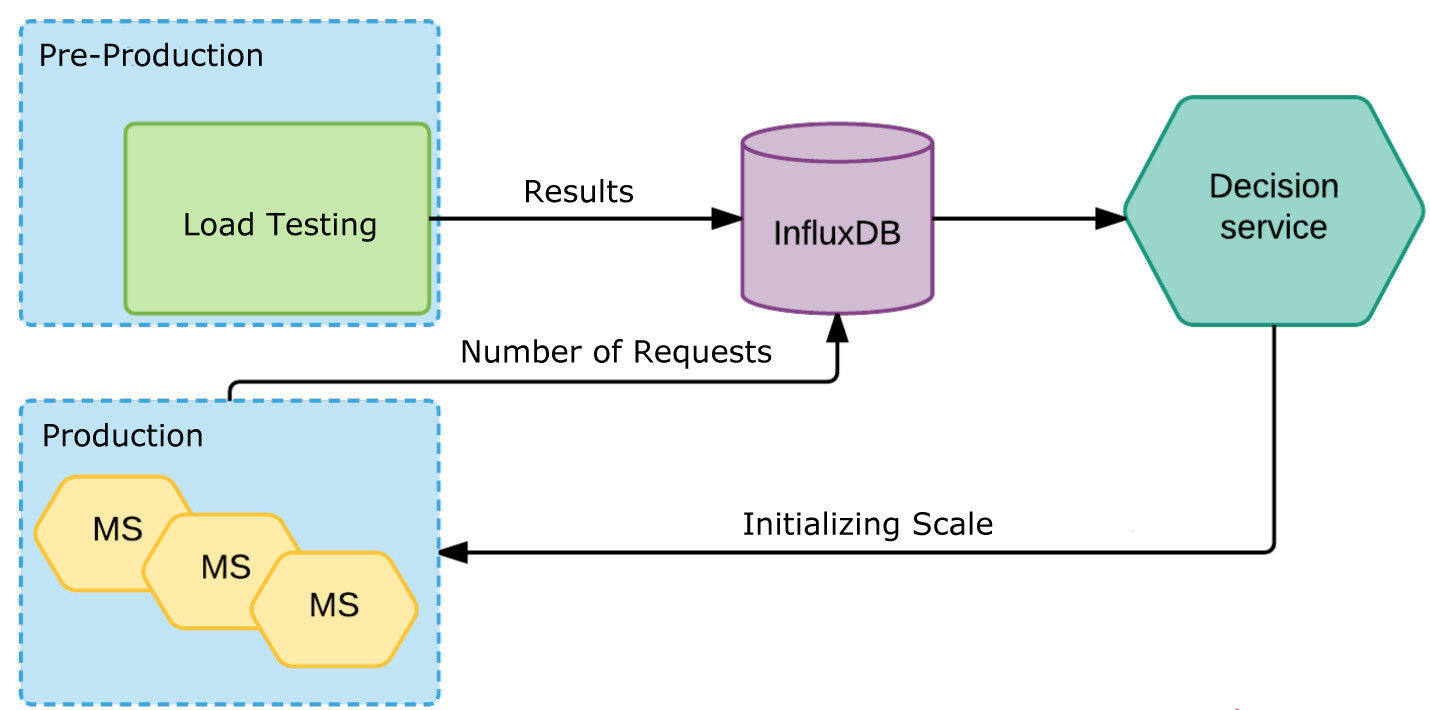
每个服务的度量指标表明了它们当前的负载。负载信息被保存到 InfluxDB,如果决策服务发现服务实例达到了上限,它会向 Nomad 和 Kubernetes 发送命令,要求增加服务实例。有可能在云端已经有可用的实例,或者开始做一些准备工作。不管怎样,发出要求增加新服务实例的告警才是关键所在。
一些受限的服务如果达到上限,也会发出相关的告警。对于这类情况,我们除了加大等待队列,也做不了其他什么事情。不过最起码我们知道我们很快就会面临这样的问题,并开始做好应对措施。
这就是我想告诉大家有关伸缩性方面的事情。除了这些,还有另外一个东西—— Gitlab CI 。
我们一般是通过 TeamCity 来开发服务的。后来,我们意识到,所有的服务都有一个共性,这些服务都是不一样的,并且知道自己该如何部署到容器里。要生成这么的项目真的很困难,不过如果使用 yml 文件来描述它们,并把这个文件与服务放在一起,就会方便很多。虽然我们只做了一些小的改变,不过却为我们带来了非常多的可能性。
现在,我想说一些一直想对自己说的话。
关于微服务开发,我建议在一开始就使用编排系统。可以使用最简单的编排系统,比如 Nomad,通过 nomad agent -dev 命令启动一个编排系统,包括 Consul 和其他东西。
我们仿佛是在一个黑盒子工作。你试图避免被绑定到某台特定的机器上,或者被附加到某台特定机器的文件系统上。这些事情会让你开始重新思考。
在开发阶段,每个服务至少需要两个实例,如果其中一个出现问题,就可以关掉它,由另一个接管继续服务。
还有一些有关架构的问题。在微服务架构里,消息总线是一个非常重要的组件。
假设你有一个用户注册系统,那么如何以最简单的方式实现它呢?对于注册系统来说,需要创建账户,然后在账单系统里创建一个用户,并为他创建头像和其他东西。你有一组服务,其中的超级服务收到了一个请求,它将请求分发给其他服务。经过几次之后,它就知道该触发哪些服务来完成注册。
不过,我们可以使用一种更简单、更可靠、更高效的方式来实现。我们使用一个服务来处理注册,它注册了一个用户,然后发送一个事件到消息总线,比如“我已经注册了一个 yoghurt,ID 是……”。相关的服务会收到这个事件,其中的一个服务会在账单系统里创建一个账户,另一个服务会发送一封欢迎邮件。
不过,系统会因此失去强一致性。这个时候你没有超级服务,也不知道每个服务的状态。不过,这样的系统很容易维护。
现在,我再说一些之前提到过的问题。不要试图修复出问题的服务。如果某些服务实例出现了问题,将它找出来,然后把流量定向到其他服务实例(可能是新增的实例)上,然后再诊断问题。这样可以显著提升系统的可用性。
通过收集度量指标来了解系统的状态自然不在话下。
不过要注意,如果你对某个度量指标不了解,不知道怎么使用它,或者它对你来说没有什么意义,就不要收集它。因为有时候,这样的度量指标会有数百万个。你在这些无用的度量指标上面浪费了很多资源和时间。这些是无效的负载。
如果你认为你需要某些度量指标,那么就收集它们。如果不需要,就不要收集。
如果你发现了一个问题,不要急着去修复。在很多情况下,系统会对此作出反应。当系统需要你采取行动的时候,它会给你发出告警。如果它不要求你在半夜跑去修复问题,那么它就不算是一个告警。它只不过是一种警告,你可以在把它当成一般的问题来处理。
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




