很多大公司都拥有大量的数据源,它们的数据格式不尽相同,而且体量巨大。在 Netflix,我们的数据仓库由很多大型的数据集组成,这些数据存储在 Amazon S3、Druid、Elasticsearch、Redshift、Snowflake 和 MySql 中。我们的平台支持 Spark、Presto、Pig 和 Hive,我们用它们来消费、处理和生成数据集。因为数据源的多样性,为了确保我们的数据平台能够横跨这些数据集成为一个“单一”的数据仓库,我们开发了 Metacat。Metacat 是一种元数据服务,方便我们发现、处理和管理数据。
目标
Netflix 大数据平台的核心架构涉及三项关键服务:执行服务(Genie)、元数据服务和事件服务。这些想法并非 Netflix 所独有,在构建一个能够满足现在及未来规模的数据基础设施时,就需要这样的架构。
多年前,当我们开始构建这个平台时,我们使用 Pig 作为 ETL 语言,Hive 作为专用查询语言。由于 Pig 本身并不具备元数据系统,因此对于我们来说,构建一个可以在两者之间进行互操作的方案似乎是理想之选。
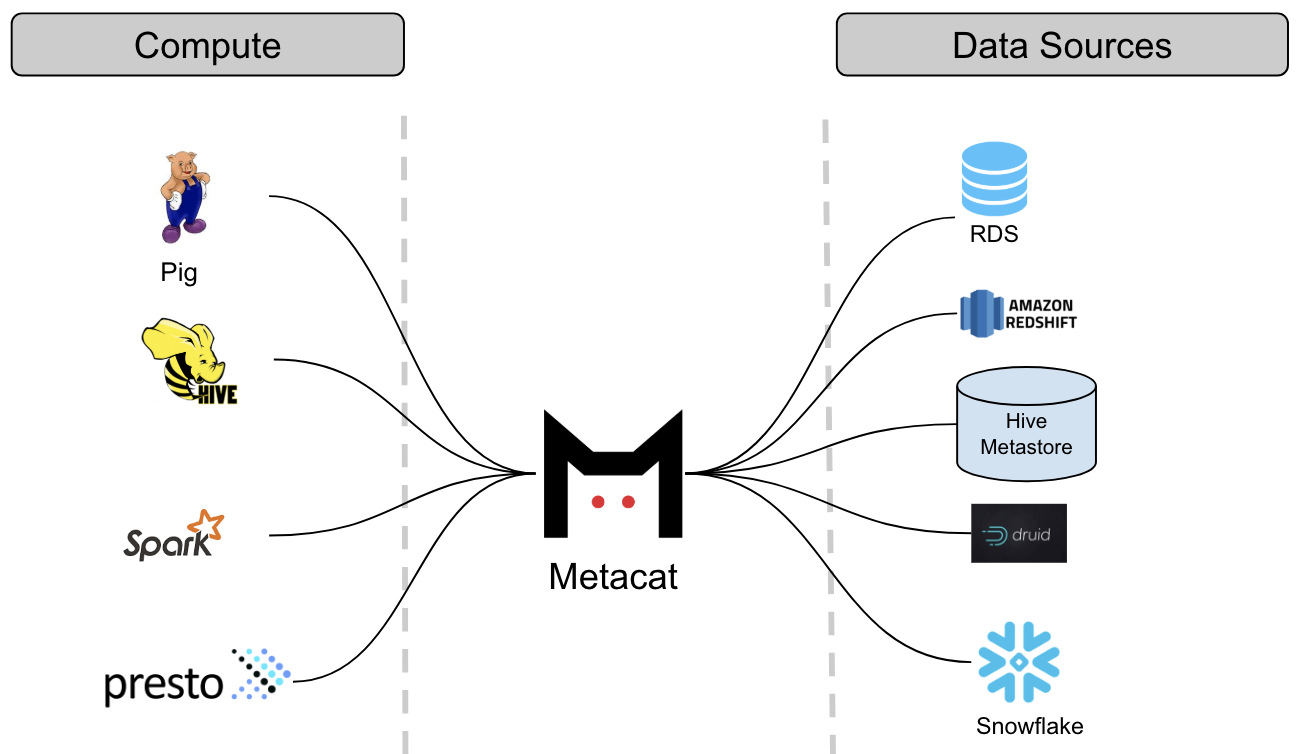
因此 Metacat 诞生了,这个系统充当了所有数据存储的元数据访问层,也是各种计算引擎可以用来访问不同数据集的集中式服务。Metacat 的三个主要目标是:
-
元数据系统的联合视图
-
用于数据集元数据的统一 API
-
数据集的任意业务和用户元数据存储
其他拥有大量分布式数据集的公司也面临着类似挑战。Apache Atlas、Twitter 的数据抽象层和 Linkedin 的 WhereHows(Linkedin 的数据发现服务)等等,都是为了解决类似问题而构建的,只是他们都有各自的架构选择。
Metacat
Metacat 是一种联合服务,提供统一的 REST/Thrift 接口来访问各种数据存储的元数据。元数据存储仍然是模式元数据的事实来源,所以 Metacat 没有保存这部分元数据。Metacat 只保存业务相关和用户定义的元数据。它还将所有关于数据集的信息发布到 Elasticsearch,以便进行全文搜索和发现。
Metacat 的功能可以分为以下几类:
-
数据抽象和互操作性
-
业务和用户定义的元数据存储
-
数据发现
-
数据变更审计和通知
-
Hive Metastore 优化

数据抽象和互操作性
Netflix 使用多种查询引擎(如 Pig、Spark、Presto 和 Hive)来处理和使用数据。通过引入通用的抽象层,不同的引擎可以交互访问这些数据集。例如:从 Hive 读取数据的 Pig 脚本能够从 Hive 列类型的表中读取数据,并转成 Pig 类型。在将数据从一个数据存储移动到另一个数据存储时,Metacat 通过在目标数据存储中创建具有目标类型的表来简化这一过程。Metacat 提供了一组预定义的数据类型,可将这些类型映射到各个数据存储中的数据类型。例如,我们的数据移动工具使用上述功能将数据从 Hive 移动到 Redshift 或 Snowflake。
Metacat 的 Thrift 服务支持 Hive 的 Thrift 接口,便于与 Spark 和 Presto 集成。我们因此能够通过一个系统汇集所有的元数据变更,并发布有关这些变更的通知,实现基于数据驱动的 ETL。当新数据到达时,Metacat 可以通知相关作业开始工作。
业务和用户定义的元数据
Metacat 也会保存数据集的业务和用户定义元数据。我们目前使用业务元数据来存储连接信息(例如 RDS 数据源)、配置信息、度量指标(Hive/S3 分区和表)以及数据表的 TTL(生存时间)等。顾名思义,用户定义的元数据是一种自由格式的元数据,可由用户根据自己的用途进行定义。
业务元数据也可以大致分为逻辑元数据和物理元数据。有关逻辑结构(如表)的业务元数据被视为逻辑元数据。我们使用元数据进行数据分类和标准化我们的 ETL 处理流程。数据表的所有者可在业务元数据中提供数据表的审计信息。他们还可以为列提供默认值和验证规则,在写入数据时会用到这些。
存储在表中或分区中的实际数据的元数据被视为物理元数据。我们的 ETL 处理在完成作业时会保存数据的度量标准,在稍后用于验证。相同的度量可用来分析数据的成本和空间。因为两个表可以指向相同的位置(如 Hive),所以要能够区分逻辑元数据与物理元数据。两个表可以具有相同的物理元数据,但应该具有不同的逻辑元数据。
数据发现
作为数据的消费者,我们应该能够轻松发现和浏览各种数据集。Metacat 将模式元数据和业务及用户定义的元数据发布到 Elasticsearch,以便进行全文搜索。我们的 Big Data Portal SQL 编辑器因此能够实现 SQL 语句的自动建议和自动完成功能。将数据集组织为目录有助于消费者浏览信息,根据不同的主题使用标签对数据进行分类。我们还使用标签来识别表格,进行数据生命周期管理。
数据变更通知和审计
作为数据存储的中央网关,Metacat 将捕获所有元数据变更和数据更新。我们还围绕数据表和分区变更开发了通知推送系统。目前,我们正在使用此机制将事件发布到我们自己的数据管道(Keystone),以更好地了解数据的使用情况和趋势。我们也将事件发布到 Amazon SNS。我们正在将我们的数据平台架构发展为基于事件驱动的架构。将事件发布到 SNS 可以让我们数据平台中的其他系统对这些元数据或数据变更做出“反应”。例如,在删除数据表时,我们的 S3 数据仓库管理员服务可以订阅这些事件,并适当地清理 S3 上的数据。
Hive Metastore 优化
由 RDS 支持的 Hive Metastore 在高负载下表现不佳。我们已经注意到,在使用元数据存储 API 写入和读取分区方面存在很多问题。为此,我们不再使用这些 API。我们对 Hive 连接器(在读写分区时,该连接器直接与 RDS 通信)进行了改进。之前,添加数千个分区的 Hive Metastore 调用通常会超时,在重新实现后,这不再是个问题。
下一步
我们在构建 Metacat 方面已经走了很长的一段路,但还没有完成我们的使命。以下是我们仍需要努力增强的一些特性。
-
模式和元数据的版本控制,用于提供数据表的历史记录。例如,跟踪特定列的元数据变更,或查看表的大小随时间变化的趋势。能够查看过去某个时刻元数据的信息对于审计、调试以及重新处理和回滚来说都非常有用。
-
为数据 lineage 服务提供数据表的上下文信息。例如,在 Metacat 中汇总数据表访问频率等元数据,并发布到数据 lineage 服务中,用于对数据表的关键性程度进行排序。
-
增加对 Elasticsearch 和 Kafka 等数据存储的支持。
-
可插拔的元数据验证。由于业务和用户定义的元数据是自由形式的,为了保持元数据的完整性,我们需要对其进行验证。Metacat 应该有一个可插拔的架构,可在存储元数据之前执行验证策略。
Metacat GitHub 地址: https://github.com/Netflix/metacat




