
1. 历史与三重迷雾
在“认识软件测试中黑天鹅”一文中,我描述了什么是软件测试中的黑天鹅及其特点,本文将探讨测试中的黑天鹅发生之前、之后、以及正在发生之中的故事。 《黑天鹅》一书的作者 Nassim 指出“历史是模糊的。你看到了结果,但看不到导致历史事件发生的幕后原因。”其实,测试何尝不是这样,假如把测试看成一个盒子,这个盒子也是模糊的,你看不到盒子里面是什么,整个机制是如何运行的。 书中描述:“对待历史问题,人类思维会犯三个毛病,我称之为三重迷雾。他们是:
- 假想的理解,也就是人们都以为自己知道在一个超出他们认知的更为复杂(或更具随机性)的世界中正在发生什么。
- 反省的偏差,也就是我们只能在事后评价事务,就像只能从后视镜里看东西(历史在历史书中比在经验现实中显得更加清晰和有调理)。
- 高估事实性信息的价值,同时权威和饱学之士本身有缺陷,尤其是在他们进行分类的时候,也就是进行‘柏拉图化’的时候。” 我很容易联想到,这三重迷雾分别对应测试中的黑天鹅发生之前、之后、以及黑天鹅形成之中的故事,即:发生之前的“盲目预测”、发生之后的“假想解释”、以及黑天鹅形成之中的“柏拉图化”。
2. 黑天鹅发生之前的“盲目预测”
“第一重迷雾就是我们以为我们生活的这个世界比它实际上更加可理解、可解释、可预测”。打开收音机或电视机,你就会听到或看到,每天都有无数的人在信心满满地预测着各种各样的事情:股市的走势、房价的走势、战争是否会爆发、疾病是否会流行……
正向 Nassim 指出的那样,“几乎所有关心事态发展的人似乎都确信自己明白正在发生什么。每一天都发生着完全出乎他们预料的事情,但他们就是认识不到自己没有预测到这些事。很多发生过的事情本来应该被认为是完全疯狂的,但在事情发生之后,看上去就没有那么疯狂。这种事后合理性在表面上降低了事件的稀有性,并使事件看上去具有可理解性。”就拿我所生活的这座城市 - 上海来说,近来的许多事件都在证实着这点:黄浦江上打捞出数千头病死猪、H7N9 的流行,昨天突然看到一条“上海自来水中添加了 XX”的微博更是令人触目惊心,我们内心都预测这些事情不应该发生,可是实际上却发生了。
这种黑天鹅发生之前的“盲目预测”让我想到软件测试中版本发布之前的“测试评估(test evaluation)”。一个产品经过测试团队的集中测试后,发布到用户那里,谁能准确预测是否会出现“黑天鹅”呢?在你的团队,在版本对外发布之前,是否需要测试团队填写一个关于产品质量的测试评估表?下图是测试评估表的一个样例。
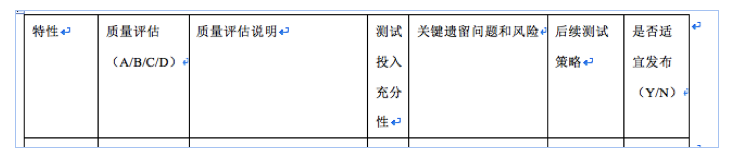
这里的特性指的是“测试特性(test feature)”。根据各团队上下文的不同,这个测试特性可能与开发特性直接对应,也可能不与开发特性一一对应,每个测试特性对应一条到多条需求(用户需求或系统设计需求)。我最常看见的质量评估说明是“XX 特性基本功能正常。”有些人会在后面附上所发现的比较严重的 bug。这样的描述显然并不令人满意。
问题是:
每个特性质量的 A/B/C/D 的结论是否准确?所有特性的 A/B/C/D 的结论加一起又如何判别整个系统的质量?是否所有特性的质量都是 A 或 B,版本就可以对外发布,并且发布以后不会出现令人意想不到的“黑天鹅”现象?测试人员给出的 A/B/C/D 有多大成分是基于一种 feeling 给出的?
对于任何一条需求,开发人员的任务就是实现它,无论是由一个项目组实现,还是多个项目组配合实现。但是,对于测试人员,考虑的事情就复杂一些。我们除了要验证这条需求本身的功能实现是否正确,还要验证该需求和其它功能之间的交互,还要考虑客户可能使用的各种场景(Scenario),包括各种组网场景、各种参数的配置等。如果把测试场景和测试特性交互起来,测试就无穷无尽了,并且也没有必要在每一种测试场景下,都验证被测特性的基本功能、异常功能、与其它功能的交互、非功能属性等各方面。如何设计更有效的、有限数目的用例尽量做到最大的测试覆盖,这属于另外一个话题,本文不做探讨。
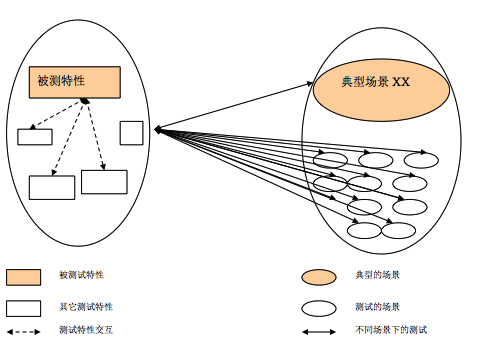
毫无疑问,尽管测试设计人员和测试执行人员精疲力尽的试图覆盖该特性的所有可能的场景,测试人员仍然只覆盖了一小部分的场景下的该特性的部分测试用例,如果没有 Fatal 的遗留问题,是否该特性的质量就可以评价为 A 或 B,并且认为可以对外发布了呢?这种测试评估工作,与其说是让测试人员对被测对象的质量进行测试评价,不如说是让测试人员对被测对象进行质量预测,因为测试人员所了解的只是部分信息,而不是全部。Nassim 说“在这些错误的预测和盲目的希望中,有一些愿望的成分,但也有知识的问题。”我更愿意相信,测试人员对产品质量的预测主要是“知识的问题”,毕竟完整测试是不可能的。 既然测试无法做到完整覆盖,不如在有限的时间和资源内,尽可能覆盖典型的场景,测试评估中针对已经覆盖到的典型场景进行评估,具体地,James Bach 和 Michael Bolton 在 RST(Rapid Software Testing)课程里提出的三步法可以供参考:
- 测试中发现了哪些问题;
- 做了哪些测试活动发现了这些问题;
- 测试活动本身的有效性如何,哪些地方可以改善。
那么对于典型场景之外的其他场景又如何评估呢,这与测试评价之前的那些测试活动息息相关,也就是与黑天鹅正在形成之中的那些故事有关,我们在后面第四部分再探讨。
3. 黑天鹅发生之后的“假想解释”
不管怎样,那些你认为不应该发生的“黑天鹅”经常如期而至。很多组织要求缺陷发生后开展缺陷根因分析(RCA)(我总是在尽力避免使用“缺陷回溯”这个词)。尤其对黑天鹅这样的重要的 bug,更要仔细开展缺陷根因分析了。对黑天鹅开展 RCA 的目的是利用这个黑天鹅,挖掘它带给我们的信息,从而尽可能在以后的测试中发现更多类似的缺陷,对开发而言则是在以后尽可能避免引入此类的 bug。
RCA 的目的是做到基于缺陷的过程改进,而不是解释黑天鹅的发生这个动作本身。不要试图去解释所有的黑天鹅,尤其是那些在实验室很难重现的黑天鹅。我看到有些测试团队,当黑天鹅发生了很紧张,又是一个严重的 bug 漏测了,赶紧组织人力调查分析,尽快写出一个看起来像样的缺陷分析报告。而阅读这个 RCA 报告,很难从中找出真正有力的措施可以有效避免今后这类 bug 不再漏测。举几个现实中的“RCA 现象”:RCA 报告中,错误的原因有“人为错误”、“沟通不畅”、“缺乏相应的测试用例”等;避免漏测的措施有“加强代码走读”、“加强白盒测试”、“提高测试设计能力”、“加强与开发人员的沟通”等。Nassim 发现,“我们的头脑是非常了不起的解释机器,能够从几乎所有事物中分析出道理,能够对各种各样的现象罗列出各种解释,并且通常不能接受某件事是不可预测的想法。”
我曾对多个团队进行 T-RCA(我提出的一个缺陷根因分析的方法)引导,发现一个有趣的现象,尽管各个团队所测试的产品是不同的,但是他们 RCA 分析的结论却是惊人的相似,很多团队都存在我上述所列的“RCA 现象”。我分析原因大致有二,一是没有找到有效开展 RCA 的方法,没有找到缺陷发生的根本原因;二是很多团队使用了比较“细致”的 RCA 模板,模板里对每一项可能的情况进行了细致的分类,比如该缺陷所处的测试级别、涉及的测试活动、所属的测试类型、可能的原因分类等等。缺陷根因分析工作仿佛变成了测试人员只要对照模板逐一打钩去筛选就可以了,但实际上 RCA 是个高度探索性的过程,需要与缺陷相关的各干系人去沟通,需要从纷繁复杂的种种因素中创造性地找到改进的措施。面对着电脑,填写那些 RCA 模板中的空白项不是最主要的工作。实际上,某种程度上讲,过细的 RCA 模板简化了缺陷分析过程,掩盖了缺陷根因分析过程的复杂性,也比较容易导致分析结果的雷同。《黑天鹅》里的这句话也许可以给我们更多启示:“我们对周围世界的任何简化都可能产生爆炸性后果,因为它不考虑不确定性的来源,它使我们错误地理解世界的构成。”
4. 黑天鹅形成之中的“柏拉图化”
既然,测试中的黑天鹅的发生是个经常性的事件,那么测试的过程不也正处于黑天鹅形成的过程吗?想象一下,当前我们正在测试一个产品,我们了解黑天鹅理论,我们知道这个产品发布给用户后极有可能会冒出“黑天鹅”来,那么我们当前可以采取什么措施呢?
我在“认识软件测试中黑天鹅”一文中解释了什么是“测试的柏拉图化”:只注重外在的形式、尤其是针对具体明确的事情进行简单分类的时候,犯“柏拉图化”错误的人容易高估他们已经掌握的事实性信息的价值,而对大量的他们还不知晓的并且非常重要的信息视而不见。我是在 2006 年发现这个“我所不知道的大量信息的”,也同时发现了之前我所犯的“测试的柏拉图化”的错误,即特别重视诸如“测试用例设计个数、测试用例执行个数、发现的 bug 数”等这些数据,也许在这些明确的、外在的形式之外,有更多值得我们思考的东西。
那一年,我负责一个特性(大体就是在手机上通过蜂窝小区广播的形式收看电视)的测试,这个特性是个全新开发的特性,我是第一个、也是当时唯一一个测试人员,测试任务很紧张,因为这个特性已经定于一、两个月以后在香港某个运营商网络里首次商用。像大多数测试人员一样,我很辛勤地、按照既定方法和策略测试这个特性,在有限的测试时间里:我熟悉了这个特性、设计了很多测试用例、执行了大量的测试用例、发现了很多 bug、对这个特性相关的每一个 bug 都了如指掌、通过和开发人员不断地交涉和定位 bug 还对该特性当前存在的缺陷非常清楚、熟悉这个特性的代码和问题定位手段。当我奔赴香港作为测试人员辅助开通这个特性的商用之前,研发团队解决了所有严重的缺陷,我很有信心应对各种可能的状况,我几乎认为我对这个特性的了解已经很完整了。
可是,当我抵达用户那里,看到我们的产品在真实网络中的运行环境、配置、使用方式,与用户和当地技术支持人员的各种交流,坐在地铁里看到身边的人员拿着手机正在开启使用我刚刚参与开通商用的特性,从真实网络环境中获取的大量错误报告和跟踪消息和后台日志。。。短短几天内,有关这个特性的、以前我所不知道的、大量的信息冲进了我的大脑,我像突然捡到宝藏一样地忙着分析日志、记录 bug,生怕遗漏了哪个 bug 没有记录,然后回到实验室都不知道如何触发。
我发现了一个重要的事实:这一回,我只用了几天时间,没有设计任何测试用例,没有执行任何测试用例,却在一个我几乎认为没有什么严重缺陷的特性上,“不费吹灰之力”似的又发现了很多严重的缺陷。而且这些缺陷不是实验室触发的,而是就发生在用户的身上,有些遭到用户的投诉,有些用户还不知晓,换句话说,这些缺陷都是优先级很高的非常重要的缺陷。
从香港回来,我一直在思考,测试团队如何发现这些重要的缺陷?甚至如何让平常我们在实验室中的测试也能这么高效、这么有效?您可能已经猜到了,这就是后来备受重视的 UBT(Usage Based Testing),或者有的行业叫做 TiP(Test in Production),也有人称为 Testing-in-the-wild。
再回到前面曾提到的一个关于测试评估的问题上:假如平常的测试更关注典型场景的测试,那么对于非典型场景如何测试以及如何评估呢?我想 UBT 是个不错的选择。既然无法做到全覆盖的测试,就不去做,不要试图在现有的测试模式下,测试设计和测试执行都投入很大精力去覆盖各种场景和交互,因为这样做收效甚微,依然达不到目的。平常的功能测试只做最普通、最典型、最重要场景下的功能验证,保证每个测试特性的基本功能 OK。此外,还要开展 UBT 或 TiP,主要考虑各种配置和场景,用模拟器模拟真实商用组网环境和业务模型,或者直接在用户使用产品的真实环境中开展测试。
假如被测系统如下图的方框,灰色的小块就是我们平常的功能测试覆盖,可能很多测试团队的做法是试图尽最大能力增加这些灰色小块的覆盖,但依然会有很多覆盖不到的地方。而 UBT 就相当于红色的范围,虽然没有针对性的设计测试用例,但由于模拟了可能使用的商用场景和业务,业务之间交互的测试在这种测试环境下自动进行,潜在的一般的 bug 都被自动发现(比较难触发的异常 bug 依然发现不了),如果这样的 UBT 测试连续执行几天或数周都没有问题,此时测试的评估中就可以很有信心地写到:在 XXX UBT 环境下连续运行 XX 天,没有发现严重问题。 这样,也大大减少了版本发布后“黑天鹅”出现的几率。

5. 结论
如果你认同“测试的黑天鹅”就在我们身边,那么:
- 在“测试的黑天鹅”发生之前,不要在信息不完整的情况下对全局做“盲目预测”,因为你只掌握了部分信息,你要做的是更准确地陈述这些“部分信息”;
- 在“测试的黑天鹅”发生之后,不要试图对所有黑天鹅都做“假想解释”,更重要的是从已经发生的黑天鹅身上挖掘更有价值的信息,以减少更多类似黑天鹅事件的发生;
- 在“测试的黑天鹅”形成过程之中,不要犯“测试的柏拉图化”错误,重视你知道的信息,更重视那些你所不知道的大量的更有价值的信息。
References
Nassim Nicholas Taleb, The Black Swan: Second Edition: The Impact of the Highly Improbable, 2008

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论