
近日,快手自研的大语言模型“快意”(KwaiYii)已开启内测,并为业务团队提供了标准 API 和定制化项目合作方案。
GitHub 链接:
https://github.com/kwai/KwaiYii
据官方介绍,快意大模型(KwaiYii) 是由快手 AI 团队从零到一独立自主研发的一系列大规模语言模型(Large Language Model,LLM),当前包含了多种参数规模的模型,并覆盖了预训练模型(KwaiYii-Base)、对话模型(KwaiYii-Chat)。
其中,13B 规模的系列模型 KwaiYii-13B 主要特点包括:
KwaiYii-13B-Base 预训练模型具备强大的通用技术支撑能力,在鳄鱼权威的中/英文基准上取得了同等模型尺寸下的 State-Of-The-Art 效果。例如,KwaiYii-13B-Base 预训练模型在 MMLU、CMMLU、C-Eval、HumanEval 等 Benchmark 上目前达到同等模型规模的领先水平。
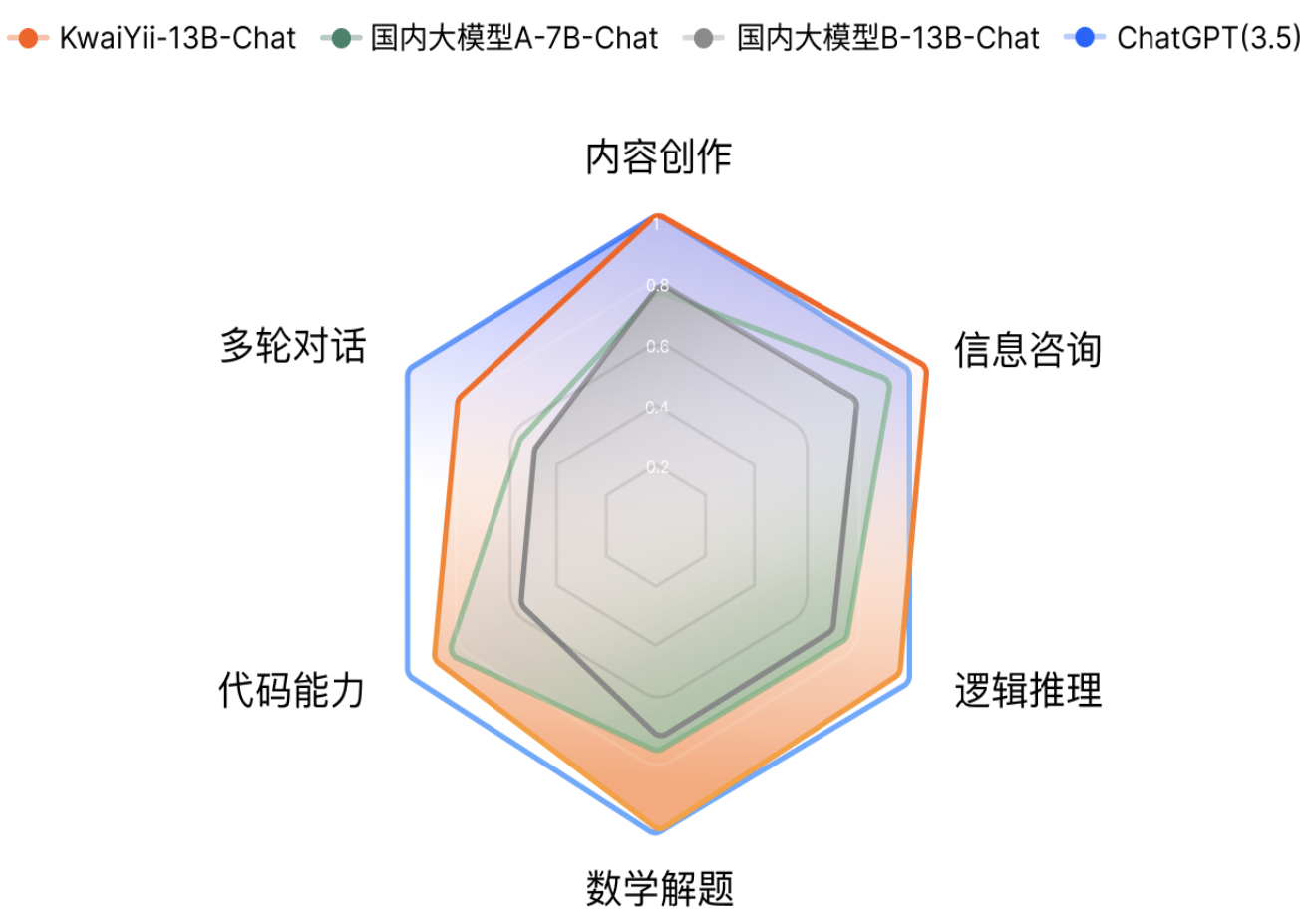
KwaiYii-13B-Chat 对话模型具备出色的语言理解和生成能力,支持内容创作、信息咨询、数学逻辑、代码编写、多轮对话等广泛任务,人工评估结果表明 KwaiYii-13B-Chat 超过主流的开源模型,并在内容创作、信息咨询和数学解题上接近 ChatGPT(3.5)同等水平。
据介绍,快意大模型(KwaiYii)在 MMLU、CMMLU、C-Eval、HumanEval 等 Benchmark 上目前处于同等模型规模的领先水平,在最新的 CMMLU 中文向排名中,快意的 13B 版本 KwaiYii-13B 同时位列 five-shot 和 zero-shot 下的第一名,在人文学科、中国特定主题等方面较强,平均分超 61 分。
KwaiYii-13B-Chat 对话模型具备出色的语言理解和生成能力,支持内容创作、信息咨询、数学逻辑、代码编写、多轮对话等广泛任务。
快手方面表示,从人工评估的结果来看,KwaiYii-13B-Chat 超过了同等规模的开源模型,并接近 ChatGPT 同等水平。在内容创作、信息咨询、逻辑推理和数学解题上,基本与 ChatGPT(3.5)效果相当。在多轮对话能力方面,KwaiYii-13B-Chat 超过同等规模的开源模型,但与 ChatGPT(3.5)仍有一定差距。注意:人工评估结果受到评测数据覆盖面、标注主观性等因素的影响,无法全面反映大语言模型的所有能力。
据悉,快手 AI 团队将持续迭代“快意”大模型,一方面将继续优化模型性能并研发多模态能力 ,另一方面也在推进更多 C 端与 B 端业务场景下的落地 。




