
近日,清华 KEG 实验室与智谱 AI 联合推出了视觉 GUI Agent——CogAgent,CogAgent 是一个通用的视觉理解大模型,具备视觉问答、视觉定位(Grounding)、GUI Agent 等多种能力,可接受 1120×1120 的高分辨率图像输入。在 9 个经典的图像理解榜单上(含 VQAv2,STVQA, DocVQA,TextVQA,MM-VET,POPE 等)取得了通用能力第一的成绩,并在涵盖电脑、手机的 GUI Agent 数据集上(含 Mind2Web,AITW 等),大幅超过基于 LLM 的 Agent,取得第一。
为了更好地促进多模态大模型、Agent 社区的发展,目前团队已将 CogAgent-18B 开源至 GitHub 仓库,并提供了网页版 Demo。
GitHub 项目地址(含开源模型、网页版 Demo):https://github.com/THUDM/CogVLM
视觉 GUI Agent
基于语言预训练模型(LLM)的 Agent 是当下热门的研究话题,其具备良好的应用前景。但受限于 LLM 的模态,它只能接受语言形式的输入。拿网页 Aagent 为例,WebAgent 等工作将网页 HTML 连同用户目标(例如“Can you search for CogAgent on google”)作为 LLM 的输入,从而获得 LLM 对下一步动作的预测(例如点击按钮,输入文本)。
然而,一个有趣的观察是,人类是通过视觉与 GUI 交互的。比如,面对一个网页,当给定一个操作目标时,人类会先观察他的 GUI 界面,然后决定下一步做什么;与此同时,GUI 天然是为了人机交互设计的,相比于 HTML 等文本模态的表征,GUI 更为直接简洁,易于获取有效信息。也就是说,在 GUI 场景下,视觉是一种更为直接、本质的交互模态,能更高效完整提供环境信息;更进一步地,很多 GUI 界面并没有对应的源码,也难以用语言表示。因此,若能将大模型改进为视觉 Agent,将 GUI 界面以视觉的形式直接输入大模型中用于理解、规划和决策,将是一个更为直接有效、具备极大提升空间的方法。
CogAgent 可以实现基于视觉的 GUI Agent,其工作路径与能力如下:
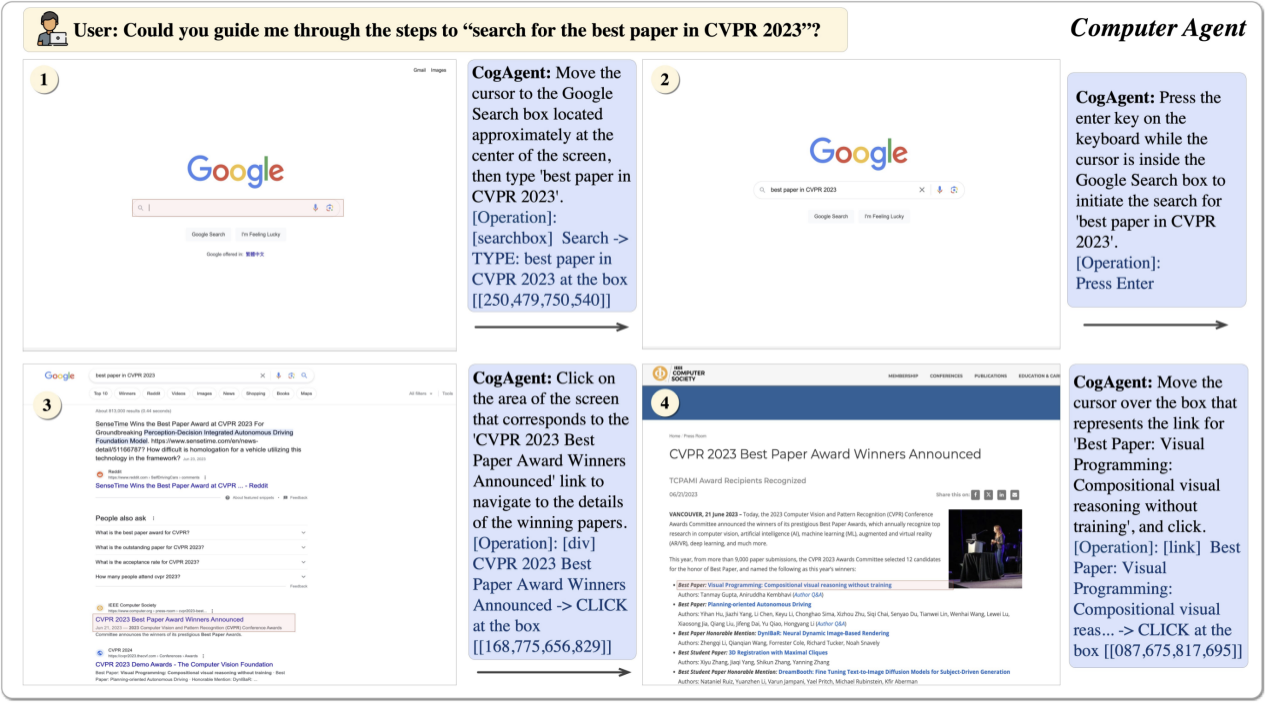
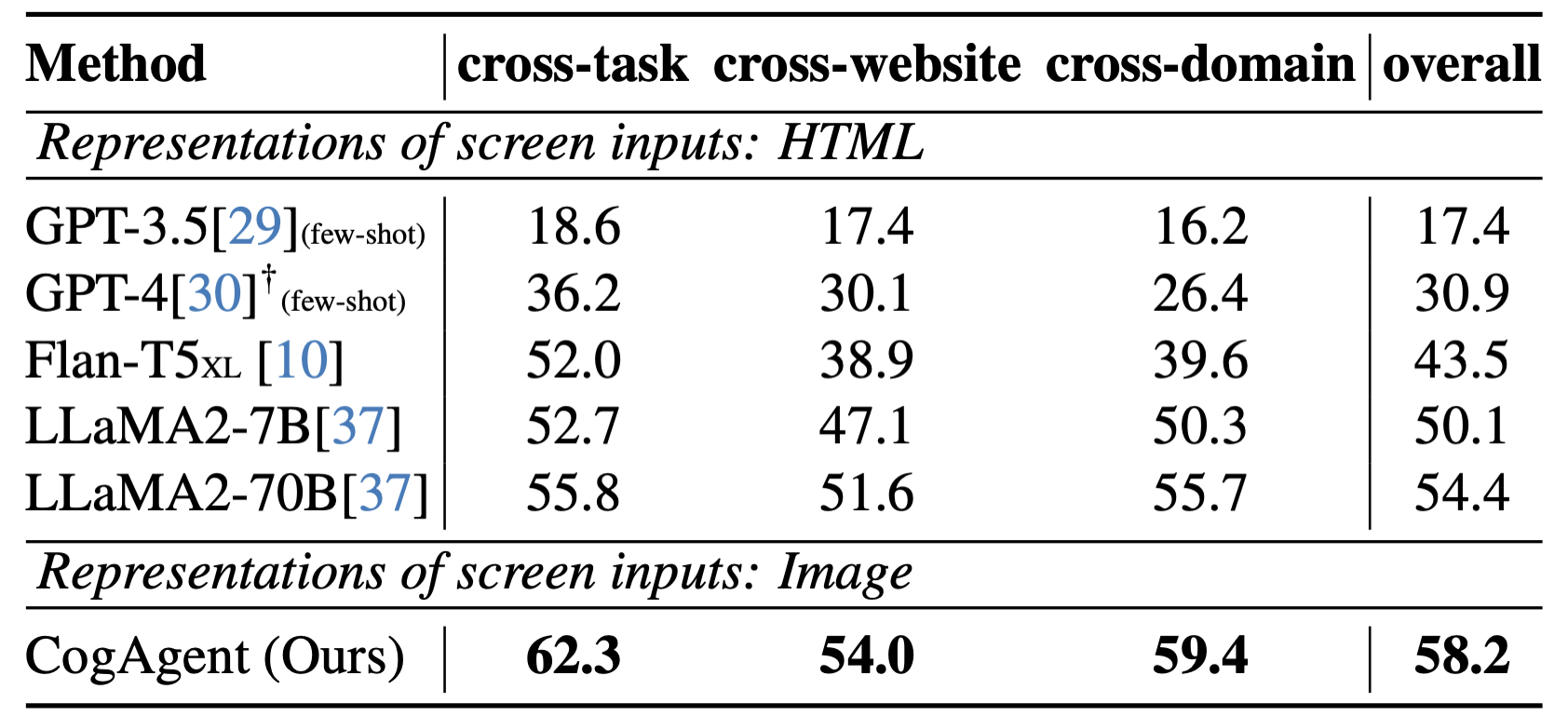
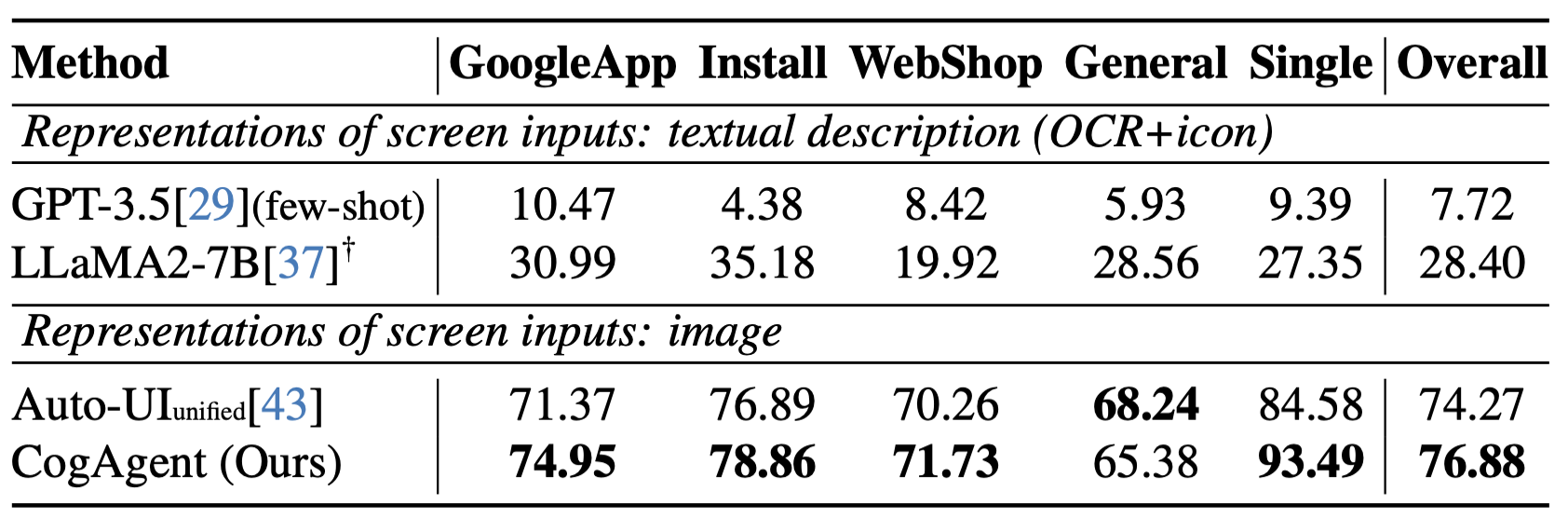
CogAgent 模型同时接受当前 GUI 截图(图像形式)和用户操作目标(文本形式,例如“search for the best paper in CVPR 2023”)作为输入,就能预测详细的动作,和对应操作元素的位置坐标。可以应用于包括电脑、手机的各种场景。受益于 GUI Agent 的可泛化性,CogAgent 能在各类没见过的场景与任务上都取得良好的性能。论文中展示了更多示例,覆盖了 PPT、手机系统、社交软件、游戏等各类场景
CogAgent 的模型结构及训练方法
据介绍,CogAgent 的模型结构基于 CogVLM。为了使模型具备对高分辨率图片的理解能力,可以看清 720p 的 GUI 屏幕输入,团队将图像输入的分辨率大幅提升至 1120×1120(以往的模型通常小于 500×500,包括 CogVLM,Qwen-VL 等)。然而,分辨率的提升会导致图像序列急剧增长,带来难以承受的计算和显存开销——这也是现有多模态预训练模型通常采用较小分辨率图像输入的原因之一。
对此,团队设计了轻量级的“高分辨率交叉注意力模块”,在原有低分辨率大图像编码器(4.4 B)的基础上,增加了高分辨率的小图像编码器(0.3 B),并使用交叉注意力机制与原有的 VLM 交互。在交叉注意力中,团队也使用了较小的 hidden size,从而进一步降低显存与计算开销。
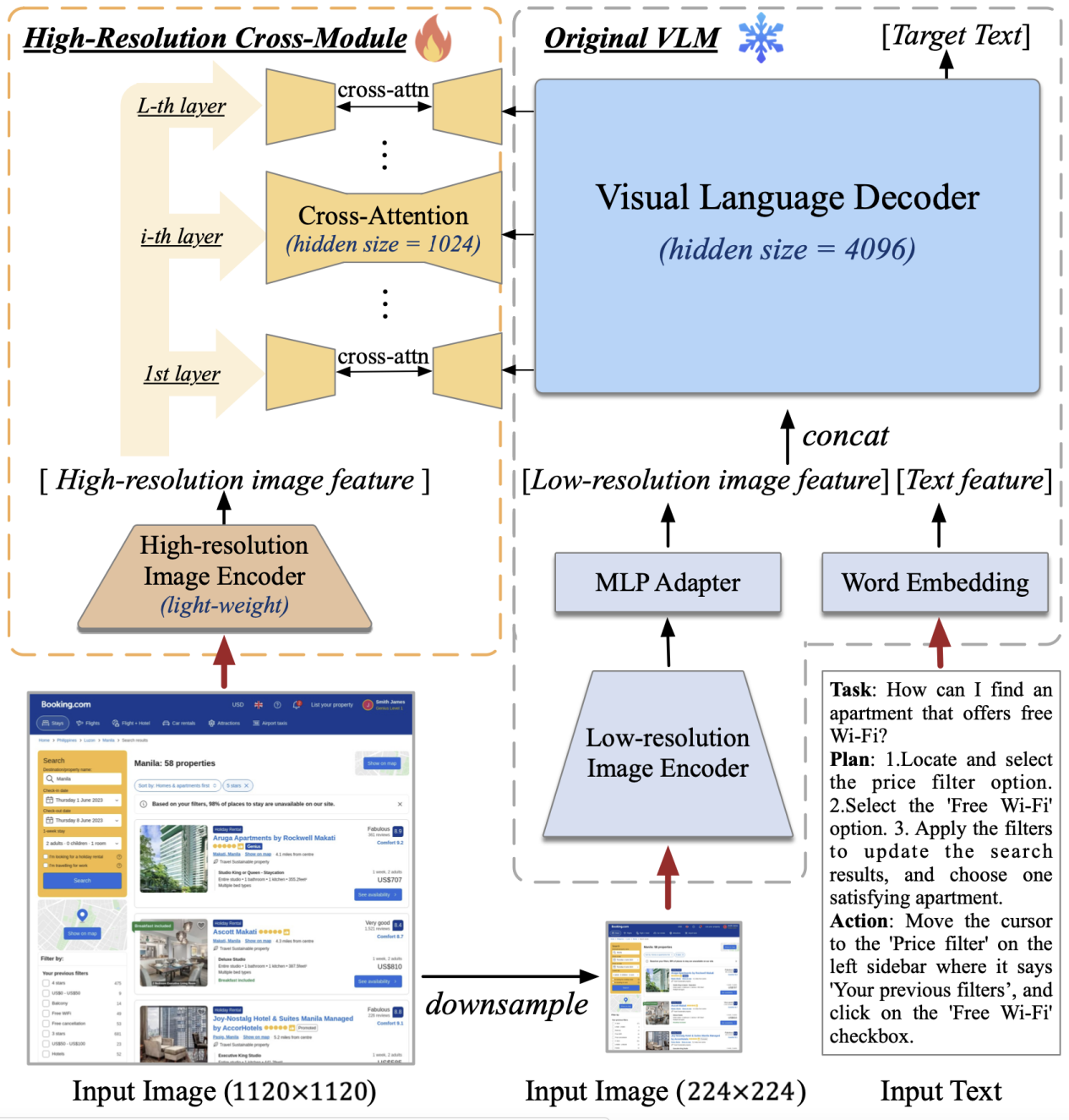
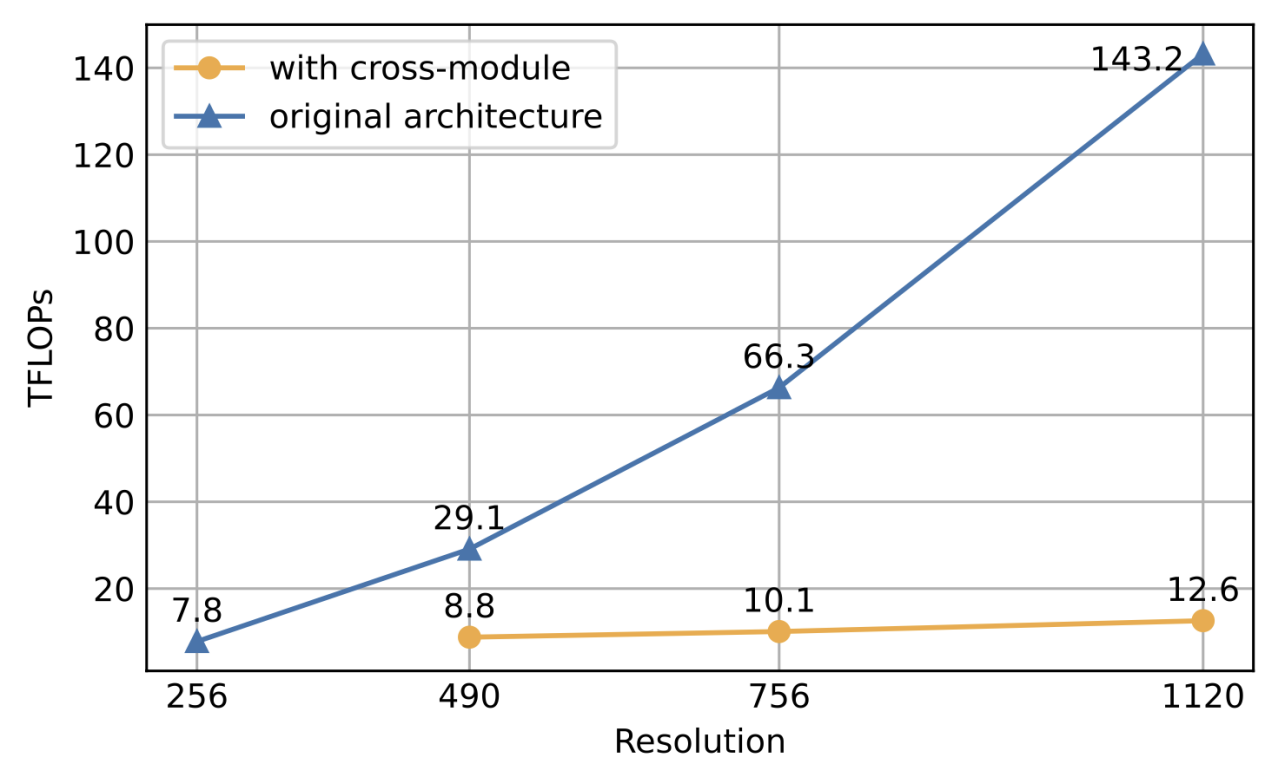
结果表明,该方法可以使模型成功理解高分辨率的图片,并有效降低了显存与计算开销。在消融实验中,团队还比较了该结构与 CogVLM 原始方法的计算量。结果表明,当分辨率提升时,使用文中提出的方案(with cross-module,橙色)将会带来极少量的计算量增加,并与图像序列的增长成线性关系。特别的,1120×1120 分辨率的 CogAgent 的计算开销(FLOPs),甚至比 490×490 分辨率的 CogVLM 的 1/2 还要小。在 INT4 单卡推理测试中,1120×1120 分辨率的 CogAgent 模型占用约 12.6GB 的显存,相较于 224×224 分辨率的 CogVLM 仅高出不到 2GB。
在数据方面,除了 CogVLM 用到的 image caption 数据集之外,团队在文本识别、视觉定位、GUI 图像理解方面进行了数据扩充与增强,从而有效提升了 GUI Agent 场景下的性能。(CogAgent 的预训练和微调数据的采集、生成方法详细介绍于论文的 2.2 和 2.3 部分。)




