
今天,我们将着眼于利用 Route 53 来部署的一个具体用例,了解如何在权衡各项因素的前提下为我们的分区机制作出合理决策。在此之后,我们还将探讨该如何利用其中的指导性概念指导我们自己的应用程序实施工作。
任播 DNS 概述
Amazon Route 53 所制定的预期目标之一,是为客户提供低延迟 DNS 解析服务。作为实施流程的组成部分,我们利用“任播”机制通过全球范围内超过五十个边界位置进行 IP 地址发布,并借此实际上述目标。所谓任播机制,是指通过将数据包路由至最近(网络范围内)位置的方式实现低延迟保障,其中每个最近位置以“公告”方式提供特定地址。在下图当中,我们可以看到其中包含有三大独立位置,它们都能够接收指向 205.251.194.72 地址的相关流量。
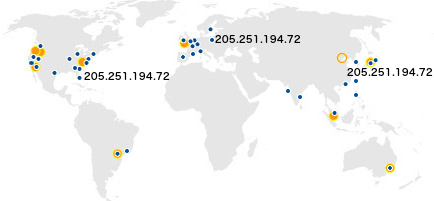
[其中蓝点所示为边界位置 ; 黄点所示则为 AWS 区域]
举例来说,如果客户将 ns-584.awsdns-09.net 分配为域名服务器,那么在查询请求抵达各个位置负责公告的底层 IP 地址时都会指向该域名服务器。查询请求的具体抵达位置取决于互联网的任播路由机制,但总体而言终端用户所接入的应该是与其当前位置距离最近的网络位置(因此能够获得低延迟体验)。
作为幕后实现机制,我们拥有成千上万个域名服务器名称(例如 ns-584.awsdns-09.net), 这些名称由四大顶级域名负责托管(分别为.com、.net、.co.uk 以及.org)。我们将源自单一顶级域名的所有域名服务器划归为一大“类型”; 也就是说,我们分别拥有.com 类型、.net 类型、.co.uk 类型以及.org 类型。而这正是混合型分区机制的起效基础:每个 Route 53 域(即托管区域)都能接收四种域名服务器名称中的任意类型的请求。这样一来,也就不会出现两个区域在全部四种域名服务器上完整重合的情况。事实上,我们可以在域名服务器的分配过程中作出强制要求,使得任何托管区域都不能与之前已经创建完成的其它托管区域存在两个以上域名服务器交集。
DNS 解析
在继续探讨下一个话题之前,我们首先需要快速解释一下 DNS 解析服务的运作机制。通常情况下,每套客户机——例如大家的个人笔记本或者台式机——都拥有一个“根解析器”。这种根解析器的作用仅仅是与递归域名服务器(即解析器)相对接,后者反过来向权威域名服务器发出请求、并在互联网上为 DNS 查询找到答复。在通常情况下,解析器应该由大家的互联网服务供应商或者公司网络基础设施负责提供,但大家也可以使用谷歌 DNS 或者其它一些开放式解析器。Route 53 属于权威域名服务器,负责对来自客户的解析请求作出回应。举例来说,当一款客户机程序尝试查找 amazon.com 时,设备上的根解析器就会指向该解析器进行查询。如果解析器缓存当中驻留有对应数据且其数值尚未过期,那么对应缓存数值就会被直接使用。如果实际情况不符合以上要求,该解析器则会向权威域名服务器发出查询请求以获取对应答复。
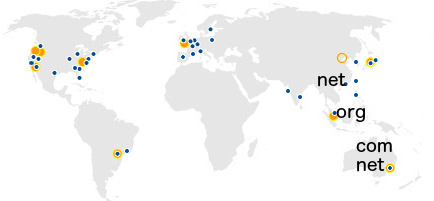
[每个位置都会发布一种或者多种域名类型,但我们在上图中只选取了悉尼、新加坡以及香港作为例来说明]
每一个 Route 53 边界位置都负责接收一种或者多种域名类型的对应流量。举例来说,当我们着眼于澳大利亚悉尼的边界位置时,其所能处理的域名为.com 与.net; 相比之下,新加坡则仅仅能够处理.org 这一域名类型。任何一个给定位置都能够根据设置处理与其它位置等同的域名类型。举例来说,香港就与悉尼一样可以处理.net 域名类型。具体来讲,如果澳大利亚区域内的某个解析器尝试对指向.org 类型域名服务器的查询进行解析——很明显,澳大利亚并不提供此类解析能力——则该查询将被路由至提供.org 类型解析能力的最近位置(例如新加坡)。新加坡区域内的解析器如果尝试处理指向.net 类型域名服务器的查询请求,则很可能被路由至香港或者悉尼——具体情况取决于该解析器所在网络所采用的互联网路由机制。这部分解释配合上图所示内容,相信大家已经对整套 DNS 解析体系有了一定程度的了解。
在一般情况下,在任何一个给定域中,解析器都会根据查询的往返时间找出延迟最低的目标域名服务器(这项技术通常被称为 SRTT,全称为平均往返时间)。对于某些查询而言,澳大利亚区域内的解析器往往倾向于为 Route 53 客户域选择归属于.net 以及.com 类型的域名服务器。
但并不是所有解析器都符合上述特征。某些解析器会在可用域名服务器当中随机作出选择,也有一些甚至会最终选择往返速度最慢的域名服务器——不过根据我们的实验,约有八成比例的解析器会选择往返时间最短的目标域名服务器。感兴趣的朋友也可以点击此处查看与此话题相关的文章,其中阐述了各类解析器到底如何选择所要使用的域名服务器。除此之外,其它一些解析器(例如谷歌的公共DNS)会使用预获取机制,或者是在某解析器无法对特定域名服务器加以解析时出现短暂的服务超时状况。
延迟- 可用性决策
鉴于前面提到的解析器运作机制,像Route 53 这样的DNS 提供方可以选择的方式之一就是通过每个边界位置发布全部四种域名类型。通过这种方式,无论解析器选择什么样的域名服务器、查询请求总能被路由至与起始点距离最近的网络位置。然而在这种情况下,我们发现其可用性模型其实并不好。
为什么会这样?因为边界位置有时候会由于某些复杂的原因而无法顺利完成解析,而且此类原因往往难以确切加以控制。举例来说,边界位置可能受到停电或者互联网连接故障的影响,这时解析器将无法与边界位置或者中间传输供应方进行正常连接。根据我们的实验结果,此类事件可能会导致长达五分钟的互联网路由更新列表连接中断。此外,近年来另一类严重风险也有愈发高企之势:大规模传输网络会由于受到DDoS 攻击而导致流量拥堵。我们的同事Nathan Dye 曾经在AWS re:Invent 大会上就此进行过主题演讲,感兴趣的朋友可以访问以下链接查看相关视频: www.youtube.com/watch?v=V7vTPlV8P3U 。
在以上提到的各类故障场景之下,来自每个位置的每套域名服务器发布机制都可能导致解析器失去后备连接位置。由于所有域名服务器都会通过路由指向相同位置,而各解析器又无法完成对 DNS 查询的解析,因此客户就会面临请求中断这一严重问题。
在下图当中,我们可以看到解析器在对 X 域进行查询时出现的不同情况——X 域中的域名服务器(分别为 NX1、NX2、NX3 以及 NX4)由所有位置进行发布 ; 而 Y 域——其域名服务器分别为 NY1、NY2、NY3 以及 NY4——则在各位置的子集中进行发布。
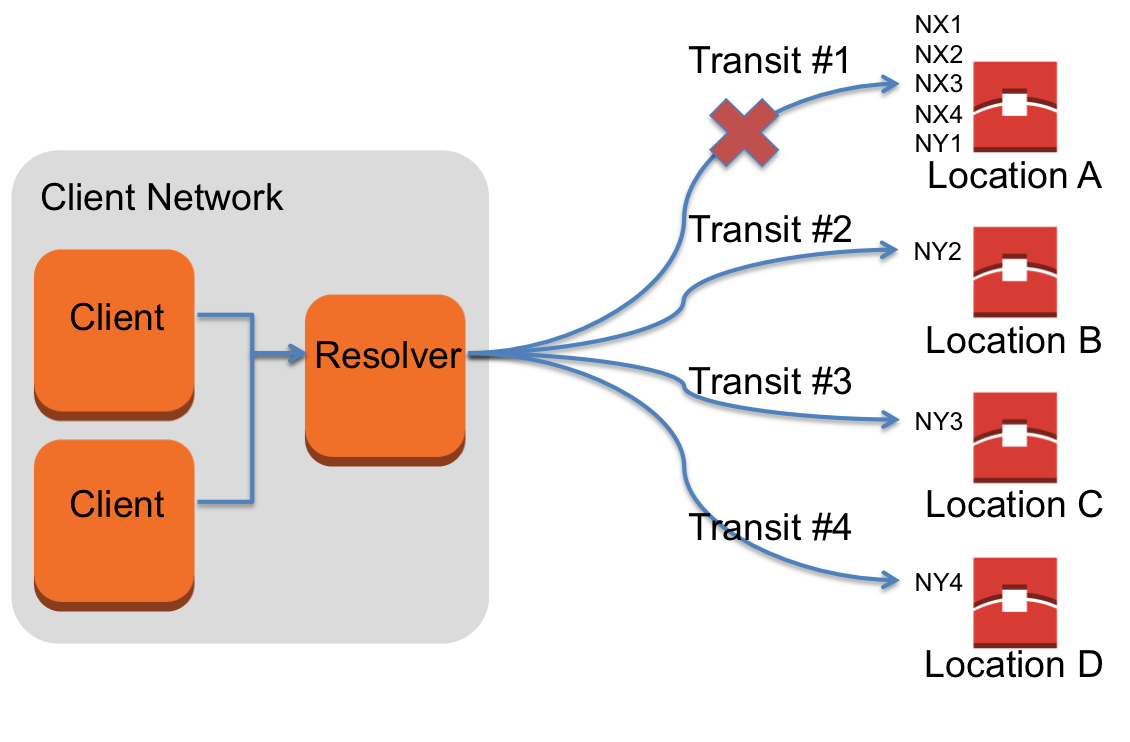
当来自位置 A 的解析器路径无法正常起效时,所有指向 X 域的域名查询请求都将发生故障。相比之下,即使来自位置 A 的解析器路径无法正常生效,位置 B、C 与 D 也仍有能够正常抵达域名服务器的传输路径,因此 Y 域的 DNS 解析服务不会受到影响。
Route 53 通常只会在每个边界位置发布单一域名类型。通过这种方式,如果某解析器在顺利抵达边界位置时遭遇任何故障,该解析器在其它三个位置仍然拥有另外三条域名服务器通路可供使用,从而实现良好的后备服务机制。举例来说,如果我们部署的软件存在问题而导致特定边界位置停止响应,对应解析器仍然可以重新尝试其它指向对象。这也正是我们以“类型规则”对部署方案加以调整的原因所在 ; Nick Trebon 曾经就我们的部署策略撰写过一篇非常出色的概述性文章,感兴趣的朋友可以点击此处进行阅读。这样的处理方式还意味着,Route 53 拥有丰富的互联网路径交付方案可供选择,这显然有助于解析器在面对流量拥堵及其它中间问题时绕过故障路径并顺利与Route 53 相对接。
Route 53 的首要目标在于实现我们为 DNS 查询所设定的 100% 服务水平协议的相关承诺——具体来说,我们承诺客户的 DNS 域名能够随时得到正常解析。但在正常起效之外,我们的客户又提出了其它要求。他们强调称,延迟问题是 DNS 服务供应商需要尽快解决的下一个关键性问题。最大程度拓展互联网路径与边界位置交付机制虽然能够带来必要的可用性提升,但同时也会导致某些域名服务器针对距离更远的边界位置作出响应。对于大多数解析器而言,我们的方法不会对最小往返时间或者最快域名服务器及其响应速度表现造成影响。由于解析器通常会优先使用速度最快的域名服务器,因此我们有信心将解析故障所带来的延时控制在最低程度,而这也是低延迟目标与高可用性之间所能获得的最佳平衡点。
通过对不同位置的域名类型划分,大家可能已经注意到、四种类型所使用的正是四大顶级域名。为了避免三大顶级域名供应商(其中.com 与.net 都由 Verisign 负责运营)之一由于某种原因而出现 DNS 服务中断,我们选择同时使用多个顶级域名。虽然这种情况很少出现,但从客户的角度出发、我们需要为其提供更为万全的保障,从而彻底杜绝顶级域名供应商在遭遇 DNS 服务中断时可能带来的灾难性后果——毕竟四类域名服务器中至少可以有两类继续保持正常工作。
应用程序
当然,大家也可以在自己的内部系统及应用程序当中采用相同的技术方案。如果各位的系统不需要面向终端用户,则不妨考虑同时利用多家顶级域名供应商实现更理想的弹性效果。特别是在大家需要控制自有 API 及调用这些 API 的客户端的情况下,我们实在没有理由将所有鸡蛋都放在一家顶级域名供应商的篮子当中。
我们着力探讨的另一类应用需求在于最大程度降低由故障转移带来的停机时间。对于高可用性应用程序而言,我们建议客户使用 Route 53 DNS Failover。在对故障转移机制进行配置后,Route 53 能够只向正常运作状态下的端点返回应答。为了准确检测端点的运作状态,Route 53 会对用户的端点进行运作状态测试。这样处理的结果是,应用程序的停机时间最低仅为 10 秒(假设大家采用的是快速运作状态检查与单一故障间隔时间配置方案),而此时故障转移机制甚至还没有被触发。在此基础之上,解析器能够利用保存在缓存当中的记录 TTL(即封包在网络中的生效时间)获得额外正常运行时间。为了尽可能降低故障转移的时耗,大家可以将前面提到的解析器运作机制编写到自己的客户端当中。另外,即使大家没有部署任播系统,也可以将自己的端点部署在多个位置(即不同可用区甚至是不同区域)当中。大家的客户端将对各个端点的持续性平均往返时间进行检测并确保查询指向速度最快的端点,而且在最快端点处于不可用状态时、转而使用其它端点。当然,除了以上各种处理方式之外,大家也可以利用混合型分区机制进一步提高故障隔离的实际效果。
本文原载于 AWS 博客。

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论