
故障转移已经过时了。现在你需要的是由多个数据中心组成的始终在线架构。
– Martin Van Ryswyk ,DataStax 工程副总裁
故障转移是指当组件故障后切换至冗余或后备系统继续运行的做法。在应对故障方面,这种方法有着漫长曲折的历史,这么说是因为你所用的故障转移机制很容易造成单点故障,并且往往会在你最需要的时候掉链子。在经手过几个使用了故障转移策略的电信系统后,我非常清楚地了解到故障转移事件会给人造成多大的压力,以及当故障转移操作失败后你会有多抓狂。如果系统中有双重或三重缺陷,肯定会在进行故障转移的过程中发作。
很长一段时间来,唯一可以帮我们实现容错的方法只能是提供热、温,或冷的后备系统(磁盘、接口、接口卡、服务器、路由器、发电机、数据中心等),并在不同组件出现问题后故障转移至后备系统。这种古老的灾难恢复计划已经不适用或者非必需了。
现在有了云基础架构,至少在软件系统层面上我们有了备选方案:始终在线的架构。谷歌将其称之为原生多宿主(Multihomed)架构。可以借助这种方式将数据分散在多个数据中心内,并让所有数据中心始终保持活跃。取决于其他数据中心内执行的操作,每个数据中心可自动对容量进行伸缩。其实这就是云计算技术最常用的宣传话术。Robin Schumacher 列举了一个很棒的例子:亲爱的 CXO – 达美航空的遭遇何时会发生在你身上?。
灾难!恢复遇到的新问题
美国西南航空公司一年前遭遇过一次服务中断,最近又遭遇了一次“千年一遇的事故”再次导致服务中断(最近千年一遇事故的发生是否太频繁了些?)。前一次事故的原因在于一套“遗留系统”无法继续处理该公司规模扩张后激增的负载,此次事故的根源是一台路由器部分失效(Partial failure)导致故障转移机制未能起作用。超过四天的时间里,此次故障导致 2300 架航班被取消,损失估计高达 1 千万美元。在对自己的系统进行工程评估时,你是否考虑过部分失效的问题?可能没有。但这种问题时有发生,并且众所周知地难以检测和解决。
美国电信运营商 Sprint 也遭遇过糟糕的备份问题:
Sprint 称华盛顿特区的一场火灾导致 Sprint 位于弗吉尼亚州雷斯顿的数据中心故障。这场火灾到底是如何从 Sprint 位于华盛顿特区的交换中心穿过大街造成 20 英里外设施产生故障的,原因还不确定,但是很明显他们部署在华盛顿特区的紧急发电机并没有按照预期正常工作,而通常这类问题也会造成一系列连锁反应。
除非身处火星上,否则你肯定听说过达美航空最近遭遇的故障转移问题:
根据 JFK-SLC 机长今早所述,计划于今天凌晨 2:30 进行的例行备份发电机切换操作过程中起火,导致数据的备份和主要副本损毁。消防员灭火后供电已恢复,共 500 台服务器中有 400 台已重新启动,但整个系统要在剩余 100 台服务器重启完成后才能恢复正常运行。
达美航空受到大量指责。备用发电机与主要发电机的距离为何如此接近,以至于被一场火灾全部摧毁?对于一个在全球范围内提供服务的系统为何只运行在一个数据中心内?为何不进行更多测试?为何没有全面故障转移至备用数据中心?为何他们更在意的是如何缩减构建可靠系统所需的成本?为何还在使用那些古老的大型机?为何一家年收入 420 亿美元的公司会使用如此蹩脚的系统?仅仅 500 台服务器,为何还没有创建群集?为何管理层只关心自己的奖金并砍掉 IT 成本?这是否是多年来一直将 IT 外包造成的苦果?
可想而知,类似的怨念还有很多。但如果你想略微深入地了解一下达美航空的系统,这里有篇不错的文章:达美航空全面管控自己的数据系统。实际上截止2014 年,达美航空为乘客提供服务的所有系统以及航行调度系统都是自行维护的。他们通过180 个专用的应用程序控制着自己的票务、网站、航班登机手续办理、机组调度等任务。他们在IT 方面每年的花销约为2.5 亿美元。
是否整个系统需要重构?
FormerRTCoverageAA 对于这些系统所涉及的技术有一些有趣的评论:
我建议让每个主要航空公司出资大约 1 千万美元(20-30 家航空公司就可以集资大约 2-3 亿美元)对相互之间的接口,以及与酒店和租车系统、游客系统,还有 SABRE/Amadeus/Apollo 等其他系统之间的接口进行现代化改造。借此可以注资一家承担研究任务的财团,对当前采用的技术进行调查,并针对下一代系统定义所需接口。也许 HP、IBM、微软等公司想要参与的话也可以注资。这个财团的主要任务在于定义所需接口,随后将制定好的规范交给构建下一代预定系统时涉及到的供应商(HP、IBM、微软、谷歌、Priceline、希尔顿、Hertz 等),接下来给他们一年时间,让他们在同一套规范的基础上实现互操作(正如他们之前在电传打字机、最后可售座位库存等技术上的合作一样)。
医疗健康领域买家和卖家之间这样的合作就取得了不错的收效。每个潜在供应商需要计划好针对自己提议的解决方案花掉 1 千万 -5 千万美元,这样我们才能获得足够公平,可互操作的技术(大概需要等待 2 周到 1 个月的时间),每个供应商可以向每家航空公司、租车公司、酒店、旅游公司、优步等公司宣传推荐自己的做法。只要能满足统一的规范,不同供应商想怎么做都行。最终能胜出的当然是最棒的技术供应商。
更新这些系统的时机早已离我们远去。否则更多难题很可能需要政府介入,甚至对更大规模的旅游和航空服务造成影响。更长的使用期限很可能导致航空公司彻底停业。还记得美国东方航空(译注:Eastern Air Lines,成立于 1926 年,在 1991 年倒闭前依然是美国第四大航空公司,该公司数年内经历过多起空难以及事故导致多名乘客死亡)吗?我反正还记得……
听起来这个主意不错,但达美航空是如何处理自己的架构问题的?
始终在线的架构
今年上半年我根据谷歌的一篇论文:大规模高可用:谷歌如何为广告业务构建数据基础架构撰写了一篇介绍始终在线技术历史的文章。那篇文章的内容和本文主题较为相关,主要内容为:
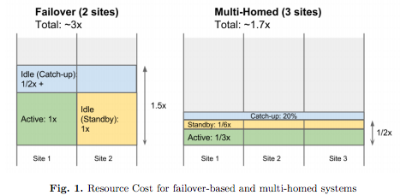
该论文的主要想法在于,典型的故障转移架构在从单一数据中心扩展至多数据中心使用场景后,实际的效果并不理想。更理想的方式应该是一种原生多宿主架构,这里所谓的“理想”是指可以使用更少的资源提供高可用性和一致性:
我们目前采用的方法是构建原生的多宿主系统。这类系统所有时间里会在多个数据中心活跃运行,并能结合实际情况在数据中心之间移动负载,借此即可以完全透明的方式应对任何规模的故障。此外计划内的数据中心停机和维护事件也是完全透明的,只会对系统的正常运行造成最少量的中断。过去此类事件需要大量人力投入,将运营着的多个系统从一个数据中心移动至另一个数据中心。
该语境中提到的“多宿主”这个概念可能会造成混淆,因为多宿主通常用来代表同时连接到多个网络的计算机。以谷歌的规模来说,也许同时连接至多个数据中心,这本身就是个非常自然的概念。
面对可能出现的数据中心层面的故障,为确保高可用(4-5 个“9”)和一致性,谷歌已经构建了多个多宿主系统: F1/Spanner:关系型数据库、 Photon:联接持续数据流(Joining Continuous Data Streams)、 Mesa:数据仓库。这篇论文介绍了这些系统所采用的方式,以及在构建多宿主系统过程中遇到的各种挑战:全局状态同步(Synchronous Global State)、检查点内容(What to Checkpoint)、可重复的输入(Repeatable Input)、严格的一次输出(Exactly Once Output)。
此时最大的约束在于具备可用性和一致性,这是令人耳目一新,也是谷歌不断强调的重点,他们甚至让这么复杂的系统也能被程序员轻松使用:
多宿主系统的简化可以为用户提供巨大的价值。在不使用多宿主系统的情况下,故障转移、恢复,以及不一致问题的处理都要由应用程序来完成。借助多宿主系统,可由基础架构解决这些复杂的问题,应用程序开发者可以免费获得高可用性和一致性,也就能更专注于自己应用程序的开发工作。
论文中最让人惊喜的地方在于,他们认为多宿主系统占用的资源甚至比故障转移系统更少:
如果将一个多宿主系统部署在三个数据中心内,这些数据中心共预留了 20% 的容量,此时资源占用总量将是稳定状态时的 170%,相比上文提到的故障转移设计 300% 的占用,比例已有大幅降低。
故障转移到底遇到了什么问题?
然而基于故障转移的方法并不能真正实现高可用,由于需要部署后备资源,反而需要付出更多成本。
我们团队过去在使用基于故障转移的系统时就遇到过一些很糟糕的体验。由于计划外的中断很罕见,通常只能以“事后想法”的方式制定故障转移规程,无法以自动化的方式进行,无法进行妥善的测试。在很多情况下,团队可能需要花费数天从故障中恢复,逐个修复不同组件让系统重新上线,并使用诸如自定义 MapReduce 等即席工具恢复系统状态,并逐步对系统进行调优,因此这时候系统正忙于处理最初故障之后开始积压的任务。这种情况不仅导致不可用的情况进一步加剧,而且会对负责复杂的关键任务系统的团队造成极大的压力。
多宿主系统的效果如何?
对比来看,多宿主系统按照设计可以运行在多个数据中心内,这是此类系统最核心的设计特性,因此不存在旁侧(On-the-side)故障转移的概念。多宿主系统所有时间会在多个数据中心内活跃运行。每个数据中心内的进程需要全时运行,并会通过多个数据中心动态分享工作任务实现负载平衡。当一个数据中心速度变慢后,部分工作会自动转移至速度更快的数据中心。当某个数据中心彻底不可用后,所有工作将自动分布至其他数据中心。
除了持续进行的动态负载平衡,无须其他任何故障转移过程。多宿主系统会使用共享的全局状态跨越数据中心对工作进行协调,全局状态必须保持同步更新。此外会对所有关键系统的状态进行复制,这样任何工作随时均可在另一个数据中心内重启动,同时依然可以确保严格遵循相同的语义。多宿主系统的独特之处在于可以在遇到数据中心层面的故障后继续维持高可用和完全的一致性。
在任何一个典型的流式系统中,我们会根据用户的交互处理相关事件,并由遍布全球的众多数据中心内负责处理用户流量的系统进行记录。由专门的日志收集服务将所有日志汇总在一起,并将其复制到两个或更多专用的日志数据中心内。每个日志数据中心保存有日志的完整副本,这样可以确保保存到任何一个数据中心的事件(最终都将)复制到所有日志数据中心。流处理系统在一个或多个这样的日志数据中心内运行,负责处理所有事件。流式处理系统的输出结果通常会存储在某些全局复制的系统中,这样便可随时随地使用输出的内容。
在多宿主系统中,所有数据中心均是活跃的,并会全时参与任务的处理。通常典型的做法是部署三个数据中心。在稳定状态下,三个数据中心中的每一个负责处理 33% 的流量。当一个数据中心遇到故障脱机后,剩余两个数据中心各负责处理 50% 的流量。
很明显,达美航空和其他大量使用了遗留系统的公司很难采用类似这样的方法。但如果不将 IT 看作成本中心,并打算继续沿袭这些费时费力的工作,而全国人民都对你的基础架构质量有较高依赖,也许是时候考虑一下其他做法了。毕竟还有别的技术可以选择。
相关文章
- HackerNews 的报道
- 十年 IT 故障经历收获的教训
- 事后反思的清单!
- CEO 向顾客道歉,航班时间表恢复工作继续进行中
- 航空公司准点情况统计和延误的原因
- 航空事故数据库和摘要
- 达美航空因备用数据中心电源问题导致故障加剧
- 数据中心设计 | 我们能从达美航空的数据中心故障中学到些什么
- Comair 航空公司取消所有 1100 架航班
- F1 和 Spanner 的全面对比
- Google Spanner 最令人惊喜的革新:NoSQL 已落伍,NewSQL 正新潮
- Spanner – 意在帮助程序员使用 SQL 语义构建 NoSQL 规模的应用
- 谷歌的三个时代 – 批处理、数据仓库、即时
作者: Todd Hoff ,阅读英文原文: The Always On Architecture - Moving Beyond Legacy Disaster Recovery
感谢陈兴璐对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




