在本系列的第1 部分中,InfoQ 翻译并分享了如何利用机器学习深入了解与App 相关的主题的讨论,以便在 Google Play 应用商店上提供更好的搜索和发现体验。在这篇文章中,Google Play 小组的软件工程师 Ananth Balashankar、Levent Koc 和项目主管 Norberto Guimaraes 讨论了一个深度学习框架,以根据用户以前下载过的 App 和他们所用的 App 上下文为用户提供个性化的建议。
为 Google Play 应用商店的访问者提供有用且相关的应用推荐是我们应用发现团队的主要目标。然而,对与App 相关联的主题的理解仅仅是创建最合适用户服务的系统的一部分。为了创造更好的整体体验,还必须考虑用户的品味并提供个性化的建议。如果没有,“你也可能喜欢”的建议对每个人来说看起来都一样!
发现这些细微差别需要了解App 的功能,以及App 与用户相关的上下文。例如,对于狂热的科幻游戏者,类似的游戏推荐可能是感兴趣的,但是如果用户安装健身App,则推荐健康食谱App 可能比五个以上的健身App 更相关。由于用户可能对下载已经安装的App 或游戏的补充更感兴趣,除了根据与App(“类似App”)相关的主题提供推荐内容外,我们还会提供基于App 相关性的建议(“您可能也喜欢”)。
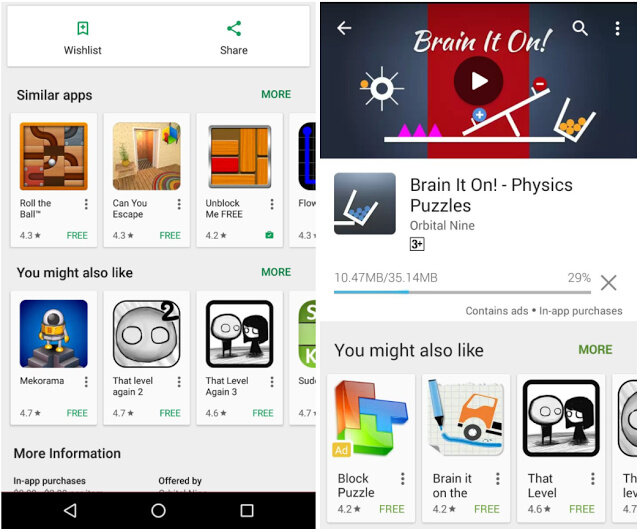
在决定安装决定之前(左)和当前安装正在进行(右)时,您可能还会看到类似的App 和App 建议。
一个特别强的上下文信号是应用相关性,基于先前的安装次数和搜索查询次数。作为示例,已经搜索并且玩很多图像密集型游戏的用户可能偏好图像密集型的App,而不是更简单的图形应用。所以,当这个用户安装赛车游戏时,“你可能也喜欢”的建议包括与“种子”相关的应用程序(因为它们是图像密集型的赛车游戏),排名高于赛车App 和更简单的图像游戏。这允许个性化更为精细,其中App 的特性与用户偏好更为匹配。
要在建议中包含这个App 的相关性,我们采取双管齐下的方法:(a)离线候选生成,即除了所讨论的App 之外,其他用户已经下载的潜在相关App 的生成,和(b)在线个性化重排序,其中我们使用个性化ML 模型重新排序这些候选。
离线候选生成
找到相关App 的问题可以被表示为最近邻搜索问题。给定一个App X,我们想找到k 个最近的App。在“你可能也喜欢”的情况下,一个简单的方法是基于计数的方式,如果许多人安装App X 和Y,那么App Y 将被用作App X 的候选种子。然而,这种方法很刺手,因为在巨大的问题空间中难以有效地学习和推广。由于Google Play 上有超过一百万个App,可能的App 对总数超过〜。
为解决这个问题,我们训练了一个深层神经网络,以预测用户在安装之前安装的下一个App。在这个深层神经网络的最后层的输出,嵌入通常表示给定用户已经安装的App 类型。然后我们应用最近邻算法来找到在训练的嵌入空间中给定的种子App 的相关App。因此,我们通过使用嵌入表示App 来修剪潜在候选的空间来执行维数降低。
在线个性化排名
在上一步骤中生成的候选表示沿着多个维度的相关性。目标是向候选分配分数,使得它们可以以个性化的方式重新排名,以便提供被制作成用户的整体兴趣并且仍然保持用户安装给定App 的相关性的体验。为了做到这一点,我们采取应用候选人的特点作为输入到单独的深层神经网络,然后使用用户特定上下文特征(区域、语言、应用商店搜索查询等)实时地训练用户以预测相关App 与用户特定相关的可能性。
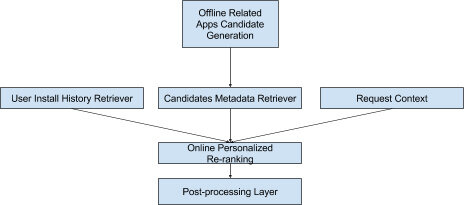
个性化相关App 的架构
这项工作的一个好处是,重新排序内容,如相关的App,是应用商店实现应用发现的关键方法之一,可以为用户带来巨大的价值,而不影响感知的相关性。与控制(没有重新排名)相比,我们发现App 安装率从“您可能也喜欢”的建议中增加了20%。这没有带来用户可察觉的延迟变化。
在本系列的第3 部分中,我们将讨论如何使用机器学习来阻止那些试图操纵我们用于搜索和个性化的信号。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




