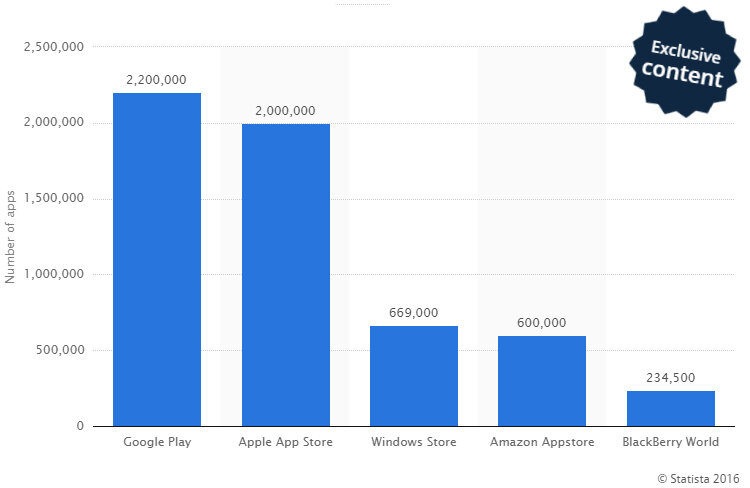
据 statista 统计,截止到 2016 年 6 月,Google Play 应用商店有 220 万个 App ,超越了苹果的应用商店的 200 万个 App,Windows 和 Amazon 的应用商店则被这两家远远甩在身后。那么,你是不是好奇,在这浩烟如海的应用商店来发现你中意的 App,是怎么做到的呢?
今天,我们就来看看 Google Play 小组的软件工程师 Malay Haldar、Matt MacMahon、Neha Jha 和 Raj Arasu 分享的这篇文章,了解到Google Play 的应用商店的工作机理。本文是Google Play 的应用发现,第一部分:了解主题。
每个月,超过10 亿的用户来在Google Play 为他们的移动设备下载App。虽然有些人寻找特定的App,如Snapchat,其他人对他们感兴趣的只有一个粗略的概念,如“恐怖游戏”或“自拍App”。这些按主题进行的宽泛搜索,就占据了应用商店中的查询的将近一半,因此找到最相关的App 至关重要。
按主题进行搜索不仅仅需要通过查询字词对App 进行索引;他们需要了解与App 相关的主题。机器学习方法已经应用于类似的问题,但它的成功,在很大程度上取决于学习一个主题的训练样本的数量。虽然对于一些热门主题,如“社交网络”,我们有许多已贴标签的App 来学习,大多数主题只有少数几个例子。我们的挑战是从数量有限的训练样本中学习,并扩展到数千个App 的数千个主题,迫使我们去适应机器学习技术。
我们最初的尝试是建立一个深度神经网络(DNN),训练根据App 标题和描述的字词和词组预测App 的主题。例如,如果App 描述提到“可怕”、“非常可怕”和“恐惧”,然后将“恐怖游戏”主题与它相关联。然而,鉴于DNN 的学习能力,它完全“记忆”了我们的小型训练数据中提到的App 主题,却不能推广到之前未见过的新App。
为了有效地推广,我们需要一个更大的数据集来训练,于是,我们转向研究人们如何学习来寻找灵感。与DNN 相反,人类只需少得多的训练数据即可。例如,在学习如何推广和关联新App 之前,您可能需要查看非常少的“恐怖游戏”App 说明。只要知道描述App 的语言,人们甚至可以从少数几个例子就能正确推断出主题。
为了效仿这一点,我们尝试了这种以语言为中心的学习的非常粗略的思路。我们训练了一个神经网络来学习如何使用语言来描述App。我们建立了一个 Skip-gram 模型,其中神经网络尝试预测给定单词周边的单词,例如给定单词“photo”的“share”。神经网络将其知识编码为浮点数的向量,称为嵌入。这些嵌入用于训练另一个称为分类器的模型,能够区分应用于 App 的主题。得益于使用 Skip-gram 模型进行大量的学习,现在我们只需很少的训练数据即可了解 App 的主题。
虽然这种架构适用于热门主题,如“社交网络”。我们碰到一个新的问题,就是有更多的小众主题,比如“自拍”。单个分类器内置预测的所有主题大部分都集中在它学过的热门主题,对于不常见的错误则忽略之。为了解决这个问题,我们为每个主题构建了一个单独的分类器,并单独调整它们。
这种架构产生了合理的结果,但仍然有时会过度概括。例如,它可能会将 Facebook 与“约会”关联,或者将“植物大战僵尸”与“教育游戏”相关联。为了产生更精确的分类器,我们需要高容量、高质量的训练数据。我们将上述系统视为一个粗分类器,它将每个可能的{app,topic}对(编号为数十亿)删除到更易于管理的{app,topic}对的列表中。我们建立了一个管道,让人类评估者来评估分类器的输出,并将共识结果作为训练数据。这个过程允许我们从现有系统中引导,提供稳定地提高分类器性能的途径。
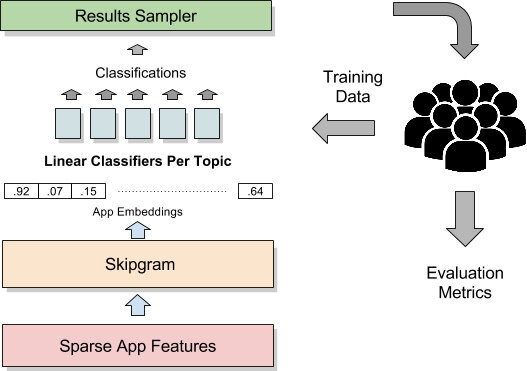
要评估{app,topic}对,我们问问题的形式是:“主题 X 与应用程序 Y 有多大程度的关联性?”多个评估者接收相同的问题,对每个 App 在评定量表上独立选择答案,标识出“重要的”、“有些关系”、或者完全“无关”。我们初步的评估显示了评估者之间存在极大的分歧。随着深入挖掘,我们发现了引起分歧的几个原因:答案不够明确;评估者培训不足;评估应用于大多数 App 或游戏的宽泛主题,像“计算机文件”、“游戏物理”那样的。解决这些问题导致评估者一致性的重要利益。要求评估者从策划列表中选择明确的答案,进一步提高可靠性。尽管有所改进,但我们有时仍然必须“同意歧见”,评估者在未能达成共识的情况下放弃作答。
这些 App 主题分类在Google Play 应用商店中启用搜索和发现功能。当前的系统帮助用户提供相关结果,但我们正在不断探索新的方法来改进系统,通过额外的标识、架构的改进和新的算法。在本系列的第2 部分中,我们将讨论如何为用户个性化应用发现体验。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




