
本文要点
- 学习图数据处理和分析
- 用 Apache Spark GraphX 库进行图数据分析
- 图类算法,如 PageRank、Connected Components 和 Triangle Counting
- Spark GraphX 组件和 API
- Spark GraphX 应用举例
这是“用 Apache Spark 进行大数据处理”系列文章的第六篇。其他文章请参考:第一部分:介绍,第二部分:Spark SQL ,第三部分:Spark Streaming ,第四部分:Spark Machine Learning ,第五部分:Spark ML Data Pipelines 。
大数据呈现出不同的形态和大小。它可以是批处理数据,也可以是实时数据流;对前者需要离线处理,需要较多的时间来处理大量的数据行,产生结果和有洞察力的见解,而对后者需要实时处理并几乎同时生成对数据的见解。
我们已经了解了如何将Apache Spark 应用于处理批数据(Spark Core)以及处理实时数据(Spark Streaming)。
有时候,所需处理的数据是很自然地联系在一起的。譬如,在社交媒体应用中,有Users、Articles 和Likes 等实体,需要把它们当作一个单独的数据逻辑单元来管理和处理。这类数据被称为图数据( Graph data )。与传统的数据处理相比,对图数据进行分析要用到不同类型的技术和方法。
在该系列文章的前几篇文章中,我们从第一篇文章“ Spark 介绍”开始,学习了 Apache Spark 框架和用于大数据处理的多种库;然后了解了 Spark SQL 库、 Spark Streaming ,以及两个机器学习包: Spark MLlib 和 Spark ML 。
在这最后一部分,我们将聚焦于如何处理图数据和学习 Spark 中的图数据分析库 GraphX 。
首先,让我们来看看什么是图数据,并了解在企业大数据应用中处理这类数据为何如此关键。
图数据
当我们讨论图数据相关的技术时,涵盖了三种不同的主题:
- 图数据库
- 图数据分析
- 图数据可视化
下面我们简单地讨论一下这些主题,了解它们之间的区别、以及它们如何相互补充以帮助大家开发一个完整的基于图的大数据处理分析软件架构。
图数据库
与传统的数据模型相比,在图数据模型中,数据实体以及实体之间的关系是核心元素。当使用图数据时,我们对实体和实体之间的联系更感兴趣。
举一个例子,如果我们有一个社交网络应用程序,我们会对某个特定用户(譬如 John)的细节感兴趣,但我们也会想对这个用户与网络中其他用户之间的关联进行建模、提取和存储。这种关联的例子有“John 是 Mike 的朋友” 或者 “John 读过 Bob 写的一本书”。
要记住的很重要的一点是,我们在实际应用中所用到的图数据是随着时间动态变化的。
图数据库的优点在于,它能揭示一些模式,而传统的数据模型和分析方法通常很难找出这些模式。
如果没有图数据库,实现一个像“找出共同的朋友”这样的用户案例,如这篇网文所描述的那样,用复杂的join 和查询条件从所有数据表的数据中进行查询是很耗费资源的。
图数据库的例子有 Neo4j 、 DataStax Enterprise Graph 、 AllegroGraph 、 InfiniteGraph 和 OrientDB 。
图数据建模
图数据建模包括定义节点(也被称作顶点)、关系(也被称作边)以及这些节点和关系的标签。
图数据库是基于 Jim Webber 的查询驱动建模( Query-driven Modelling )而构建的,数据模型不仅仅对数据库技术人员开放,也对领域专家开放,它能支持团队在建模和模型演化上的合作。
图数据库产品通常包括一个查询语言(如 Cypher 是 Neo4j 中的查询语言)来管理存储在数据库中的图数据。
图数据处理
图数据处理主要包括:先通过图的遍历来找到匹配特定模式的节点,然后定位相关节点和关系,这样我们可以看到不同实体之间的关系的模式。
数据处理管道通常包括以下步骤:
- 数据预处理 (包括导入、变换和过滤)
- 图的创建
- 分析
- 后处理
一个典型的图分析工具应该可以灵活地处理图数据和集合数据,如此,我们就可以将不同的数据分析工作(如 ETL,探索式分析和迭代的图计算)结合在一个单独的系统中,而不必使用不同的框架和工具。
有好几种框架可以处理图数据和在数据上运行预测分析,包括 Spark GraphX 、Apache Flink 的 Gelly 和 GraphLab 。
在该文中,我们将聚焦于用 Spark GraphX 来分析图数据。
Gelly 的框架文档中也提到了几种不同的图生成器,譬如Cycle Graph、Grid Graph、ypercube Graph、Path Graph 和Star Graph。
图数据可视化
一旦我们开始将相连接的数据保存到图数据库并在图数据上运行分析,我们需要一些工具来可视化在这些数据实体之间的关系模式。
图数据可视化工具包括 D3.js 、 Linkurious 和 GraphLab Canvas 。没有数据可视化工具,图数据分析就不完整。
图案例
在很多情况下,图数据库比关系型数据库或其他 NoSQL 数据存储更加适合用于管理数据。下面给出了一些使用场景。
- 推荐和个性化(Recommendations and Personalization):图分析可以用于生成客户推荐和个性化模型,从数据分析中发现有洞察力的见解并用于作出关键的决策。这有助于企业有效地影响客户去购买它们的产品。这种分析也有助于制定市场策略和改进客户服务行为。
- 欺诈检测(Fraud Detection):在支付处理应用中,基于包括用户(users)、产品(products)、交易(transactions)和事件(events)等实体的连接数据,图数据解决方案可以帮助找出欺诈性的交易。这里有一篇文章描述了一个如何用 Spark GraphX 进行欺诈分析的测试应用,它将 PageRank 算法应用在电话通信的元数据上。
- 主题建模(Topic Modeling):它包括对文档聚类和从文档数据中提取主题描述的技术。
- 社区检测(Community Detection):阿里巴巴网站使用图分析技术,如社区检测,来解决电子商务问题。
- 飞行性能(Flight Performance):其他用户案例包括如这篇文章所讨论的准点飞行性能,分析以图结构所表示的飞行性能数据,找出统计数据,如机场排名和城市间的最短路径。
- 最短路径(Shortest Distance):最短距离和道路在社交网络应用中也很有用。它们可被用于衡量网络中一个特定用户的相关度。最短路径越小,用户越相关。
Spark GraphX
GraphX 是 Apache Spark 用于图和图并行计算的 API。它扩展了 Spark RDD,引入了一个新的图抽象:有向多图(directed multigraph),每个节点和边都有自己的属性。
GraphX 库提供了图算子(operator)来转换图数据,如 subgraph、joinVertices 和 aggregateMessages。它提供了几种方法来从 RDD 或硬盘上的一堆节点和边中来构建一个图。它也提供了许多图算法和构造方法来进行图分析。我们将在后面讨论图算法。
图 1 展示了 Apache Spark 生态系统以及 GraphX 与其他库在整个框架中的关系。
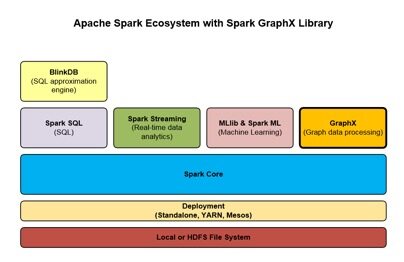
图 1. Spark 生态系统和 GraphX 库
通过内嵌的算子和算法,GraphX 使得在图数据上运行分析变得更加容易。它还允许用户 cache 和 uncache 图数据,以在多次调用图的时候避免出现重复计算。
表 1 中列出了 GraphX 中的一些图算子。
算子类型 算子 描述 基本算子
-
numEdges
-
numVertices
-
inDegrees
-
outDegrees
-
degrees
属性算子
- mapVertices
-
mapEdges
-
mapTriplets
结构算子
- reverse
-
subgraph
-
mask
-
groupEdges
关联算子 - joinVertices
-
outerJoinVertices
表 1:Spark GraphX 的图算子
在应用样例章节,当我们在不同的社交网络数据集上运行 GraphX 算法时,我们将详细讨论这些算子。
GraphFrames
GraphFrames 是 Spark 图数据处理工具集的一个新工具,它将模式匹配和图算法等特征与 Spark SQL 整合在一起。节点和边被表示为 DataFrames,而不是 RDD 对象。
GraphFrames 简化了图数据分析管道,优化了对图数据和关系数据的查询。与基于 RDD 的图处理相比,GraphFrames 有下列优势:
- 在 Scala API 之外,还支持 Python 和 Java。我们现在可以在这三门语言中使用 GraphX 算法。
- 用 Spark SQL 和 DataFrames 获得更高级的查询能力。Graph-aware query planner 使用物化视图来提高查询性能。我们也可以用 Parquet、JSON 和 CSV 等格式来存储和导入图。
网站 spark-apache.org 以 GraphX 插件的形式提供了可用的 GraphFrames。这里有一篇文章展示了如何使用 GraphFrames 来计算图数据集中每个节点的 PageRank。
图分析算法
图算法能帮助在图数据集上执行分析,而不用自己实现这些算法。下面给出了一些算法,来帮助找出图中的模式。
- PageRank
- Connected components
- Label propagation
- SVD++
- Strongly connected components
- Triangle count
- Single-Source-Shortest-Paths
- Community Detection
Spark GraphX 中已经包含了一些预构造的图算法来进行图数据处理和分析工作。这些算法在 org.apache.spark.graphx.lib 包中。调用这些算法很简单,就像从 Graph 类中调用一个方法一样简单。
图 2 展示了如何在 GraphX API 之上构建不同的图算法。
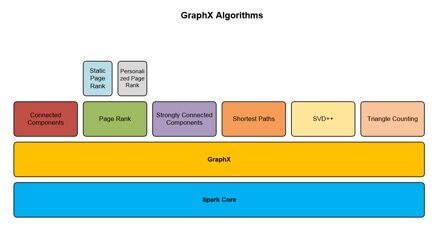
图 2. Spark GraphX 库中的图算法
在此文中,我们将详细地介绍 PageRank、Connected Components 和 Triangle Count 等算法。
PageRank
PageRank 算法被用于确定图数据集中的一个对象的相关重要程度。它衡量图中每个节点的重要性,假设从其他节点到该节点的边代表着认可(endorsement)。
PageRank 的一个经典例子就是 Google 的搜索引擎。基于有多少网页引用某个网页,Google 使用 PageRank 来计算该网页的重要程度。
另一个例子是社交网络网站,如 Twitter。如果一个 Twitter 用户被许多其他用户关注,那么该用户在网络中有较高的影响力。这种度量指标可被用于对关注者进行广告投放(100,000 个用户关注一个厨师 => 很可能是食物爱好者)。
GraphX 提供了两种 Pageank 的实现方法:静态的和动态的。
静态 PageRank:该算法迭代运行固定的次数,对图数据中的某给定节点集生成 PageRank 值。
动态 PageRank:该算法运行直至 PageRank 值收敛到一个预定义的误差容忍值。
Connected Components
图中的一个 Connected Component 就是一个连接的子图,其中,两个节点由边互相连接,并且子图中没有其他节点。也就是说,当两个节点之间存在关系时,这两个节点属于同一个 Connected Component。子图中具有最低数值节点的 ID 被用于标记 Connected Component。在社交网络例子中,可用 Connected Component 来创建图中的类(cluster)。
计算 connected components 时,有两种图遍历方法:
图数据处理中还有另外一个算法叫做 Strongly Connected Components (SCC)。如果图中每个节点都可到达所有的节点,那么这个图是强连接的。
Triangle Counting
Triangle counting 是一种社区分析算法,它被用于确定经过图中每个节点的三角形的数量。如果一个节点有两个相邻节点而且这两个相邻节点之间有一条边,那么该节点是三角形的一部分。三角形是一个三节点的子图,其中每两个节点是相连的。Triangle counting 算法返回一个图对象,我们可以从它上面提取节点。
Triangle counting 被大量地用于社交网络分析中。它提供了衡量图数据聚类分析的方法,这对在社交网站(如 LinkedIn 或 Facebook)中寻找社区和度量区域群落的粘度很有用。 Clustering Coefficient 是社交网络中的一个重要的度量标准,它显示了一个节点周围的社区之间的紧密程度。
Triangle Counting 算法的其他用户案例有垃圾邮件检测和连接推荐。
与其他图算法相比,Triangle counting 涉及大量的信息和复杂耗时的计算。因此,当你测试该算法时,确保你在性能较好的机器上运行 Spark 程序。需要注意的是,PageRank 衡量相关度,而 Triangle counting 衡量聚类结果。
应用样例
在此文中,目前我们已经了解了什么是图数据,以及为什么对不同的结构而言图分析是数据处理项目的一个重要部分。现在我们来看看使用图算法的应用例子。
我们用到的数据集来自于不同的社交网络网站,如 Facebook、LiveJournal 和 YouTube。这些应用都含有连接数据,是很好的数据分析资源。
有篇文章中讨论了一些 GraphX 样例来比较几种图处理工具,我们在这里所用到的案例正是基于那些例子。
用户案例
在我们的应用样例中用到一些用户案例,它们的主要目标在于确定图数据的统计数据,譬如:
- 在社交网络中,不同用户的受欢迎程度如何(PageRank)
- 基于网络中的用户连接来对用户分群(Connected Components)
- 社区发现和对社交网络中的用户社区的粘度分析(Triangle Counting)
数据集
在我们的代码例子中,我们将用到四种不同的数据集来运行 Spark GraphX 程序。这些数据集可以从斯坦福大学的 SNAP (Stanford Network Analysis Project)网站找到。如果你想下载这些数据集,将它们拷贝到应用样例主目录的数据文件夹中。
算法
在应用样例中,我们将用到以下三种算法。
- PageRank on YouTube
- Connected Components on LiveJournal
- Triangle Counting on Facebook
下面这张表格中展示了用户案例以及图数据处理程序中所用到的数据集和算法。
表 2:Spark GraphX 用例中所用到的数据集和算法
如果你重命名了这些文件,将它们拷贝到项目主目录下的“data”子目录中。
技术
在图分析代码示例中,我们将会用到下列技术:
技术
版本
Apache Spark
2.1.0
Scala
2.11
JDK
1.8
Maven
3.3
表 3:用例中所用到的技术和其版本
代码示例
我们将用 Scala 编程语言来写 Spark GraphX 代码,用 Spark Shell 命令行工具来运行这些程序。这是验证程序结果的最快的方式。不需要额外的代码编译和构建步骤。
在查看这些代码之前,这些程序以 zip 文件的形式与此文一起提供,你可以下载并在你自己的开发环境中尝试。
现在我们来仔细看看每一个 GraphX 程序例子。
首先,我们在 YouTube 在线社交网络数据上运行 PageRank。该数据集包括了真实的社区信息,基本上是用户所定义的其他用户可加入的群组。
PageRank:
import org.apache.spark._ import org.apache.spark.graphx._ import org.apache.spark.rdd.RDD import java.util.Calendar // 先导入边 val graph = GraphLoader.edgeListFile(sc, "data/page-rank-yt-data.txt") // 计算图中边和节点等信息 val vertexCount = graph.numVertices val vertices = graph.vertices vertices.count() val edgeCount = graph.numEdges val edges = graph.edges edges.count() // // 现在来看看某些 Spark GraphX API,如 triplets、indegrees 和 outdegrees。 // val triplets = graph.triplets triplets.count() triplets.take(5) val inDegrees = graph.inDegrees inDegrees.collect() val outDegrees = graph.outDegrees outDegrees.collect() val degrees = graph.degrees degrees.collect() // 用迭代次数作为参数 val staticPageRank = graph.staticPageRank(10) staticPageRank.vertices.collect() Calendar.getInstance().getTime() val pageRank = graph.pageRank(0.001).vertices Calendar.getInstance().getTime() // 输出结果中前 5 个元素 println(pageRank.top(5).mkString("\n"))
上述代码中,变量“sc”是 SparkContext,当你从 Spark Shell 运行程序时该变量已经可用了。
下面我们来看看在 LiveJournal 的社交网络数据上运行 Connected Components 的代码。该数据集包括在网站上注册并有个人和群组博客帖子的用户。该网站还允许用户识别朋友用户。
Connected Components:
import org.apache.spark._ import org.apache.spark.graphx._ import org.apache.spark.rdd.RDD import java.util.Calendar // Connected Components val graph = GraphLoader.edgeListFile(sc, "data/connected-components-lj-data.txt") Calendar.getInstance().getTime() val cc = graph.connectedComponents() Calendar.getInstance().getTime() cc.vertices.collect() // 输出结果中前 5 个元素 println(cc.vertices.take(5).mkString("\n")) val scc = graph.stronglyConnectedComponents() scc.vertices.collect()
最后是在 Facebook 的社交圈数据上计算 Triangle Counting 的 Spark 程序,依旧用的 Scala。该数据集包括 Facebook 上的朋友列表,信息包括 user profiles,circles 和 ego networks。
Triangle Counting:
import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark.graphx._ import org.apache.spark.rdd.RDD val graph = GraphLoader.edgeListFile(sc,"data/triangle-count-fb-data.txt") println("Number of vertices : " + graph.vertices.count()) println("Number of edges : " + graph.edges.count()) graph.vertices.foreach(v => println(v)) val tc = graph.triangleCount() tc.vertices.collect println("tc: " + tc.vertices.take(5).mkString("\n")); // println("Triangle counts: " + graph.connectedComponents.triangleCount().vertices.collect().mkString("\n")); println("Triangle counts: " + graph.connectedComponents.triangleCount().vertices.top(5).mkString("\n")); val sum = tc.vertices.map(a => a._2).reduce((a, b) => a + b)
结论
图数据处理和分析在预测分析和推荐引擎解决方案中能获取有洞察力的见解,并对员工、客户和用户提供服务。随着连接数据在商业组织、政府部门和社交媒体网络公司的逐渐增长,图数据处理和分析在这些应用中只会变得更加关键。
这篇文章表明, Spark GraphX 是满足图数据处理需求的很好的选择。它提供了一种统一的数据处理算法和解决方案工具集,对企业内不同业务过程所产生的相互联系的数据,生成有价值的见解和预测模型。
下一步
如同我们在该系列文章中所见到的, Apache Spark 框架为统一的大数据处理应用软件系统架构提供了必要的库、设施和工具。无论数据是否需要实时处理或者批处理,或者数据集是否有连接和关系,Spark 使得与不同类型的数据打交道变得更加容易。当处理和分析由不同机构所创建和管理的不同类型的数据时,我们不再需要依赖于使用几种不同的框架。
如果你正在为公司寻找大数据解决方案,或者你有兴趣转型到大数据和数据科学领域,Apache Spark 是一个绝佳的选择。
参考文献
- Big Data Processing using Apache Spark - Part 1: Introduction
- Big Data Processing using Apache Spark - Part 2: Spark SQL
- Big Data Processing using Apache Spark - Part 3: Spark Streaming
- Big Data Processing using Apache Spark - Part 4: Spark Machine Learning
- Big Data Processing with Apache Spark - Part 5: Spark ML Data Pipelines
- Apache Spark Main Website
- Spark GraphX Main Website
- GraphX Programming Guide
- Spark GraphX in Action , Manning Publications
- Facebook’s Comparison of Apache Giraph and Spark GraphX for Graph Data Processing
- Databricks blog article on GraphFrames
关于作者
 Srini Penchikala 目前是位于德州奥斯汀的一名高级软件架构师。他在软件系统架构、设计和开发方面有超过 22 年的经验。Penchikala 目前正在撰写一本关于 Apache Spark 的书。他还是曼宁出版社出版的“ Spring Roo in Action ”一书的合著者。他曾出席多个会议,如 JavaOne、SEI Architecture Technology Conference (SATURN)、IT Architect Conference (ITARC)、No Fluff Just Stuff、NoSQL Now、Enterprise Data World、OWASP AppSec 和 Project World Conference。Penchikala 还在 InfoQ、The ServerSide、OReilly Network (ONJava)、DevX Java、java.net 和 JavaWorld 等网站上发表过关于软件架构、安全和风险管理以及 NoSQL 和大数据等主题的文章。他是 InfoQ 数据科学社区的主编。
Srini Penchikala 目前是位于德州奥斯汀的一名高级软件架构师。他在软件系统架构、设计和开发方面有超过 22 年的经验。Penchikala 目前正在撰写一本关于 Apache Spark 的书。他还是曼宁出版社出版的“ Spring Roo in Action ”一书的合著者。他曾出席多个会议,如 JavaOne、SEI Architecture Technology Conference (SATURN)、IT Architect Conference (ITARC)、No Fluff Just Stuff、NoSQL Now、Enterprise Data World、OWASP AppSec 和 Project World Conference。Penchikala 还在 InfoQ、The ServerSide、OReilly Network (ONJava)、DevX Java、java.net 和 JavaWorld 等网站上发表过关于软件架构、安全和风险管理以及 NoSQL 和大数据等主题的文章。他是 InfoQ 数据科学社区的主编。
该文是系列文章“用 Apache Spark 进行大数据处理”的第六篇。请参看:第一部分: 介绍,第二部分: Spark SQL,第三部分: Spark Streaming,第四部分: Spark Machine Learning,第五部分: Spark ML Data Pipelines。
查看英文原文: Big Data Processing Using Apache Spark - Part 6: Graph Data Analytics with Spark GraphX
感谢薛命灯对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论