剖析 Elasticsearch 集群系列涵盖了当今最流行的分布式搜索引擎 Elasticsearch 的底层架构和原型实例。
本文是这个系列的第一篇,在本文中,我们将讨论的 Elasticsearch 的底层存储模型及 CRUD(创建、读取、更新和删除)操作的工作原理。
本系列已经得到原文著者 Ronak Nathani 的授权
Elasticsearch 是当今最流行的分布式搜索引擎,GitHub、 SalesforceIQ、Netflix 等公司将其用于全文检索和分析应用。在 Insight,我们用到了 Elasticsearch 的诸多不同功能,比如:
- 全文检索
- 比如找到与搜索词项 (term) 最相关的维基百科文章。
- 聚合
- 比如在广告网络中,可视化的搜索词项的竞价直方图。
- 地理空间 API
- 比如在顺风车平台,匹配最近的司机和乘客。
正是因为 Elasticsearch 如此流行并且就在我们身边,我决定深入研究一下。本文,我将分享 Elasticsearch 的存储模型和 CRUD 操作的工作原理。
当我在思考分布式系统是如何工作时,我脑海里的图案是这样的:
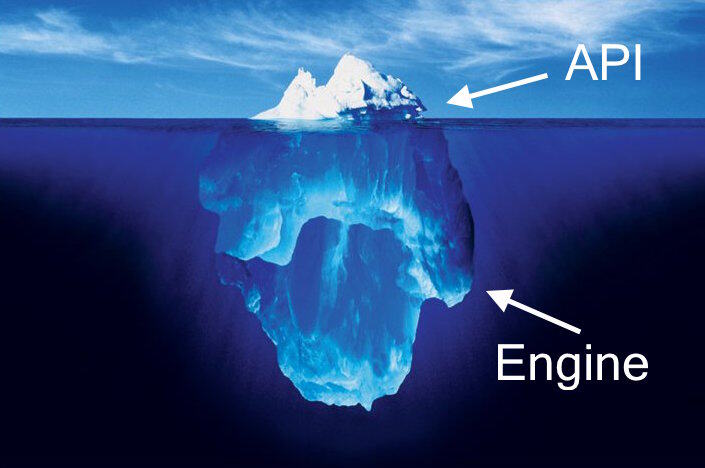
水面以上的是 API,以下的才是真正的引擎,一切魔幻般的事件都发生在水下。本文所关注的就是水下的部分,我们将关注:
- Elasticsearch 是主从架构还是无主架构
- Elasticsearch 的存储模型是什么样的
- Elasticsearch 是怎么执行写操作的
- Elasticsearch 是怎么执行读操作的
- 如何定义搜索结果的相关性
在我们深入这些概念之前,让我们熟悉下相关的术语。
1 辨析 Elasticsearch 的索引与 Lucene 的索引
Elasticsearch 中的索引是组织数据的逻辑空间 (就好比数据库)。1 个 Elasticsearch 的索引有 1 个或者多个分片 (默认是 5 个)。分片对应实际存储数据的 Lucene 的索引,分片自身就是一个搜索引擎。每个分片有 0 或者多个副本 (默认是 1 个)。Elasticsearch 的索引还包含"type"(就像数据库中的表),用于逻辑上隔离索引中的数据。在 Elasticsearch 的索引中,给定一个 type,它的所有文档会拥有相同的属性 (就像表的 schema)。
(点击放大图像)

图 a 展示了一个包含 3 个分片的 Elasticsearch 索引,每个分片拥有 1 个副本。这些分片组成了一个 Elasticsearch 索引,每个分片自身是一个 Lucene 索引。图 b 展示了 Elasticsearch 索引、分片、Lucene 索引和文档之间的逻辑关系。
对应于关系数据库术语
Elasticsearch Index == Database
Types == Tables
Properties == Schema
现在我们熟悉了 Elasticsearch 世界的术语,接下来让我们看一下节点有哪些不同的角色。
2 节点类型
一个 Elasticsearch 实例是一个节点,一组节点组成了集群。Elasticsearch 集群中的节点可以配置为 3 种不同的角色:
-
主节点:控制 Elasticsearch 集群,负责集群中的操作,比如创建 / 删除一个索引,跟踪集群中的节点,分配分片到节点。主节点处理集群的状态并广播到其他节点,并接收其他节点的确认响应。
每个节点都可以通过设定配置文件 elasticsearch.yml 中的node.master属性为true(默认) 成为主节点。
对于大型的生产集群来说,推荐使用一个专门的主节点来控制集群,该节点将不处理任何用户请求。
-
数据节点:持有数据和倒排索引。默认情况下,每个节点都可以通过设定配置文件 elasticsearch.yml 中的node.data属性为true(默认) 成为数据节点。如果我们要使用一个专门的主节点,应将其node.data属性设置为false。
-
客户端节点:如果我们将node.master属性和node.data属性都设置为false,那么该节点就是一个客户端节点,扮演一个负载均衡的角色,将到来的请求路由到集群中的各个节点。
Elasticsearch 集群中作为客户端接入的节点叫协调节点。协调节点会将客户端请求路由到集群中合适的分片上。对于读请求来说,协调节点每次会选择不同的分片处理请求,以实现负载均衡。
在我们开始研究发送给协调节点的 CRUD 请求是如何在集群中传播并被引擎执行之前,让我们先来看一下 Elasticsearch 内部是如何存储数据,以支持全文检索结果的低延迟服务的。
存储模型
Elasticsearch 使用了 Apache Lucene ,后者是 Doug Cutting( Apache Hadoop 之父) 使用 Java 开发的全文检索工具库,其内部使用的是被称为倒排索引的数据结构,其设计是为全文检索结果的低延迟提供服务。文档是 Elasticsearch 的数据单位,对文档中的词项进行分词,并创建去重词项的有序列表,将词项与其在文档中出现的位置列表关联,便形成了倒排索引。
这和一本书后面的索引非常类似,即书中包含的词汇与其出现的页码列表关联。当我们说文档被索引了,我们指的是倒排索引。我们来看下如下 2 个文档是如何被倒排索引的:
文档 1(Doc 1): Insight Data Engineering Fellows Program
文档 2(Doc 2): Insight Data Science Fellows Program
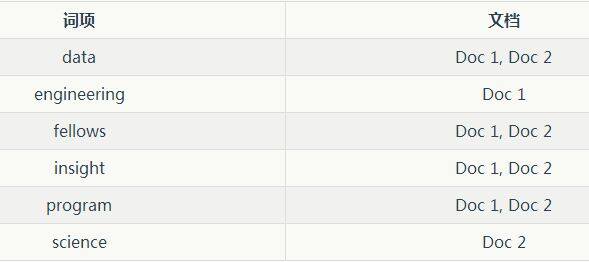
如果我们想找包含词项"insight"的文档,我们可以扫描这个 (单词有序的) 倒排索引,找到"insight"并返回包含改词的文档 ID,示例中是 Doc 1 和 Doc 2。
为了提高可检索性 (比如希望大小写单词都返回),我们应当先分析文档再对其索引。分析包括 2 个部分:
- 将句子词条化为独立的单词
- 将单词规范化为标准形式
默认情况下,Elasticsearch 使用标准分析器,它使用了:
- 标准分词器以单词为界来切词
- 小写词条 (token) 过滤器来转换单词
还有很多可用的分析器在此不列举,请参考相关文档。
为了实现查询时能得到对应的结果,查询时应使用与索引时一致的分析器,对文档进行分析。
注意:标准分析器包含了停用词过滤器,但默认情况下没有启用。
现在,倒排索引的概念已经清楚,让我们开始 CRUD 操作的研究吧。我们从写操作开始。
剖析写操作
创建 (©reate)
当我们发送索引一个新文档的请求到协调节点后,将发生如下一组操作:
-
Elasticsearch 集群中的每个节点都包含了改节点上分片的元数据信息。协调节点 (默认) 使用文档 ID 参与计算,以便为路由提供合适的分片。Elasticsearch 使用 MurMurHash3 函数对文档 ID 进行哈希,其结果再对分片数量取模,得到的结果即是索引文档的分片。
shard = hash(document_id) % (num_of_primary_shards) -
当分片所在的节点接收到来自协调节点的请求后,会将该请求写入 translog(我们将在本系列接下来的文章中讲到),并将文档加入内存缓冲。如果请求在主分片上成功处理,该请求会并行发送到该分片的副本上。当translog 被同步( fsync ) 到全部的主分片及其副本上后,客户端才会收到确认通知。
-
内存缓冲会被周期性刷新 (默认是 1 秒),内容将被写到文件系统缓存的一个新段上。虽然这个段并没有被同步 (fsync),但它是开放的,内容可以被搜索到。
-
每 30 分钟,或者当 translog 很大的时候,translog 会被清空,文件系统缓存会被同步。这个过程在 Elasticsearch 中称为冲洗 (flush)。在冲洗过程中,内存中的缓冲将被清除,内容被写入一个新段。段的 fsync 将创建一个新的提交点,并将内容刷新到磁盘。旧的 translog 将被删除并开始一个新的 translog。
下图展示了写请求及其数据流。
(点击放大图像)

更新 ((U)pdate) 和删除 ((D)elete)
删除和更新也都是写操作。但是 Elasticsearch 中的文档是不可变的,因此不能被删除或者改动以展示其变更。那么,该如何删除和更新文档呢?
磁盘上的每个段都有一个相应的 **.del文件。当删除请求发送后,文档并没有真的被删除,而是在.del文件中被标记为删除。该文档依然能匹配查询,但是会在结果中被过滤掉。当段合并 (我们将在本系列接下来的文章中讲到) 时,在.del** 文件中被标记为删除的文档将不会被写入新段。
接下来我们看更新是如何工作的。在新的文档被创建时,Elasticsearch 会为该文档指定一个版本号。当执行更新时,旧版本的文档在.del文件中被标记为删除,新版本的文档被索引到一个新段。旧版本的文档依然能匹配查询,但是会在结果中被过滤掉。
文档被索引或者更新后,我们就可以执行查询操作了。让我们看看在 Elasticsearch 中是如何处理查询请求的。
剖析读操作 (®ead)
读操作包含 2 部分内容:
- 查询阶段
- 提取阶段
我们来看下每个阶段是如何工作的。
查询阶段
在这个阶段,协调节点会将查询请求路由到索引的全部分片 (主分片或者其副本) 上。每个分片独立执行查询,并为查询结果创建一个优先队列,以相关性得分排序 (我们将在本系列的后续文章中讲到)。全部分片都将匹配文档的 ID 及其相关性得分返回给协调节点。协调节点创建一个优先队列并对结果进行全局排序。会有很多文档匹配结果,但是,默认情况下,每个分片只发送前 10 个结果给协调节点,协调节点为全部分片上的这些结果创建优先队列并返回前 10 个作为 hit。
提取阶段
当协调节点在生成的全局有序的文档列表中,为全部结果排好序后,它将向包含原始文档的分片发起请求。全部分片填充文档信息并将其返回给协调节点。
下图展示了读请求及其数据流。
(点击放大图像)

如上所述,查询结果是按相关性排序的。接下来,让我们看看相关性是如何定义的。
搜索相关性
相关性是由搜索结果中 Elasticsearch 打给每个文档的得分决定的。默认使用的排序算法是 tf/idf(词频 / 逆文档频率)。词频衡量了一个词项在文档中出现的次数 (频率越高 == 相关性越高),逆文档频率衡量了词项在全部索引中出现的频率,是一个索引中文档总数的百分比 (频率越高 == 相关性越低)。最后的得分是 tf-idf 得分与其他因子比如 (短语查询中的) 词项接近度、(模糊查询中的) 词项相似度等的组合。
接下来有什么?
这些 CRUD 操作由 Elasticsearch 内部的一些数据结构所支持,这对于理解 Elasticsearch 的工作机制非常重要。在接下来的系列文章中,我将带大家走进类似的那些概念并告诉大家在使用 Elasticsearch 中有哪些坑。
- Elasticsearch 中的脑裂问题及防治措施
- 事务日志
- Lucene 的段
- 为什么搜索时使用深层分页很危险
- 计算搜索相关性中困难及权衡
- 并发控制
- 为什么 Elasticsearch 是准实时的
- 如何确保读和写的一致性
查看原文地址: http://insightdataengineering.com/blog/elasticsearch-crud
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




