
本文源自 1 月 19 日『高效开发运维』微信群的在线分享《Goldeneye 智能监控》,分享者为阿里巴巴开发专家马小鹏先生,转载请在文章开头注明来自『高效开发运维』公众号。加群学习请关注『高效开发运维』公众号,并点击菜单中的“加群学习”或直接回复“加群”。
背景介绍
该分享是阿里妈妈 Goldeneye 业务监控平台的智能监控解决方案。
这个分享主要包括智能监控的技术实现,以及大规模日志监测数据的自动化接入两部分。我先介绍一下智能监控部分,下一期分享中我的两位同事将给大家着重介绍日志分析处理的计算存储。智能监控现在其他一些公司也有在做,希望通过这次分享能够给大家带来一些新的启发,也欢迎大家能够提出问题和建议,互相切磋交流经验。——马小鹏
分享内容的提纲如下:Goldeneye 智能监控的业务背景、技术思想、技术实现细节、难点和今后的优化方向。
嘉宾介绍
马小鹏,阿里妈妈全景业务监控平台技术负责人。2013 起在阿里从事大规模系统日志分析及应用的研发,曾经主导了直通车广告主报表平台和实时报表存储选型。在加入阿里之前,曾负责网易电商 App 数据统计平台的研发。
一、Goldeneye 智能监控的背景
Goldeneye 作为阿里妈妈业务监控平台,主要在业务日志、数据的实时统计分析基础上做监控报警以及辅助定位。阿里集团内部也有很多优秀的监控平台,它们在开放性上做的很好,接入成本也不高,但是监控阈值也是开放给用户自己设定。这种情况下,对于业务监控人工维护阈值就比较复杂,需要有丰富的经验来拍定阈值,需要人工持续的维护不同监控项的监控阈值。所以,在业务快速发展的前提下,传统的静态阈值监控很容易出现了误报、漏报的问题,而且人工维护成本高,监控视野局限。Goldeneye 就是在这种基础上,我们试着从大数据应用的角度,去解决业务监控中的问题,由此诞生的。
1. 业务背景:
(1)体量大:Goldeneye 现在接入的业务线覆盖了阿里妈妈主体的 90% 业务,每天处理的日志量在 100T 以上,业务监控需要对各业务线的流量分层级实时监控,核心数据以 1 分钟为周期,一般监测数据以 5 分钟或 1 小时为周期,监控目标非常多,按人工维护这些监控的阈值、启停、生效实效等几乎是达不到的。
(2)变化多:业务监控的监测数据大都是业务指标,不同于系统运维指标,比如 RT/QPS/TPS 等一般是比较稳定的,业务指标具有周期性变化的特点,比如工作日和节假日的区别、业务营销策略调整的影响等,在这种情况下人工设定的静态报警阈值准确性就很难保障了。
(3)迭代快:随着阿里妈妈资源整合和业务的快速发展,监控目标也经常发生变化,比如流量监控资源位的调整、效果监控的产品类型划分等,曾经出现过新流量上线后的监控盲点。
2. 技术背景:
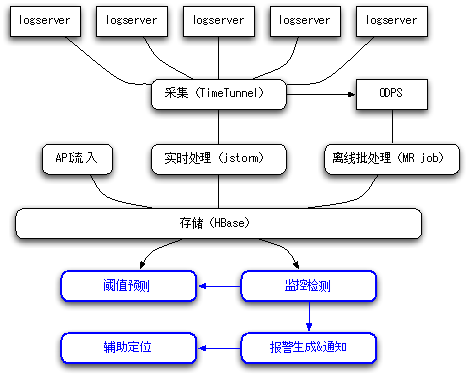
图 1 Goldeneye 技术背景
通常的业务监控系统或平台,都是由采集、数据处理、检测、报警等模块组成的,Goldeneye 也是如此,不过它的技术架构上用了阿里内部的一些技术中间件,比如采集我们使用 TimeTunnel(它有 agent 在各台日志服务器上拉日志到 Topic,并且负责将离线日志放到 ODPS 上),这部分我不再介绍了。
数据处理我们使用的 jstorm 和 ODPS MR job 分别对日志进行实时、离线批处理,主要包括日志解析、校验、时间周期归一化、聚合、写存储(HBase)等操作,这部分下一期分享中我的同事会详细介绍。今天的分享主要集中在阈值预测、监控检测、报警生成 & 通知、辅助定位这四部分。
二、技术思想
智能监控就是让系统在业务监控的某些环节上代替人工执行和判断的过程。人工维护监控目标和阈值是以经验为参考的,系统如何自动判断哪些目标需要监控、自动设定监控目标的阈值水位、不用人力维护,是基于对历史样本数据统计分析得出判断依据。
通过收集监测数据的样本,并使用智能检测算法模型,让程序自动对监控项指标的基准值、阈值做预测,在检测判断异常报警时使用规则组合和均值漂移算法,能精确地判断需要报警的异常点和变点。
1. 阈值水位自适应变化
以往我们添加监控有两种做法:
- 给指标 M1 设置一个水位线,低于(或高于)水位,触发报警;
- 给指标 M1 设置同比、环比波动幅度,比如同比波动 20%、环比波动 10% 触发报警;
以上两种方式,是平常大家常用的监控方式,但是效果确不理想,这种静态阈值长期来看没有适应变化的能力,需要人工维护,而且报警准确性也依赖于同环比数据的稳定性。
我们能否让系统具备自动适应变化的能力,自动调整阈值水位?就如同手动挡的汽车换成自动挡一样,可以根据速度自己调节档位。
2. 监控项自动发现
当我们的监控系统具备预测动态阈值的能力后,监控项的维护是否也可以交给系统去做?
可能大家也曾遇到过类似的情况,旧的监控项已经没有数据了,新的监控目标却因为各种原因被漏掉,人工维护监控项需要及时同步上下线变更,但是当我们需要监控的目标有一千个、一万个甚至更多的时候,人力是无法一直跟进这些监控项的维护工作的,或者说这种工作比较单调容易被忽视。
我们能否将判断如何筛选监控项的规则交给系统,让它去定期检查哪些监控项已经实效,哪些监控项需要新增,哪些监控项的阈值需要调节。这种发现规则是稳定的,仅仅是依据发现规则得出的监控项内容在不断变化而已。
3. 过滤误报时欲擒故纵
当我们的监控系统具备预测动态阈值、自动发现并维护监控项的能力后,如何达到不漏报和不误报之间的平衡?
对于监控而言,漏报是不可容忍的,但是误报过多也容易使人麻木。
通常的做法是为了不被误报干扰至麻木,会把阈值调节得宽松些,但是这种做法容易产生漏报,尤其是下跌不太明显的情况。
Goldeneye 采取的思路是对误报 case 欲擒故纵,在首先确保不漏报的基础上降低误报率。先监控产生疑似异常点,这一环节我们基于动态阈值去检测时相对严格一些(或者说这一环节不用考虑报警收敛的问题),然后对这些疑似异常点再做验证、过滤,最终生成报警通知,验证和过滤的依据是预先定义的规则,比如指标组合判断、报警收敛表达式等。
三、技术实现细节
下面介绍技术实现的一些细节,分为监控系统的架构、动态阈值、变点检测、智能全景、辅助定位五个点。
1、整体介绍
Goldeneye 监控系统的四个输入:实时监测数据、历史数据、预测策略、报警过滤规则。
其中,历史数据是实时监测数据的积累。
而预测策略主要包括:
(1)阈值参数:设置基于预测基准值的系数决定阈值上下限区间、分时段阈值预测系数、分报警灵敏度阈值预测系数;
(2)预测参数:样本数量、异常样本过滤的高斯函数水位或者过滤比例、基于均值漂移模型的样本分段选取置信度等。
关于报警过滤规则,主要是为了在充分捕捉疑似异常点的前提下,过滤不必要的报警。比如指标 M1 异常,但是组合规则是 M1 和 M2 同时异常才报警,这种就会过滤掉。再比如,按照报警收敛规则,一个监控项的第 1 次,第 2 次,第 10 次,第 50 次连续报警值得关注,可以设置收敛表达式为 1,2,10,50,那么在报警通知生成时对于第 3,4,…,9,11,12,…,49 次报警可以忽略,因为反复通知的意义不大,这个规则可以按需要达到自动收敛。也可以在同一监控项的多个实例同时发生异常报警的情况下,按规则合并成一条报警,这些规则可以按具体情况去实现,最终的目的是以最简洁的方式暴露最值得关注的报警。
(这里补充一句,我们最近在考虑新的收敛方式,对第 1 条和最后 1 条报警,并且自动计算出累积 gap,这样异常的起止和影响范围更明显)
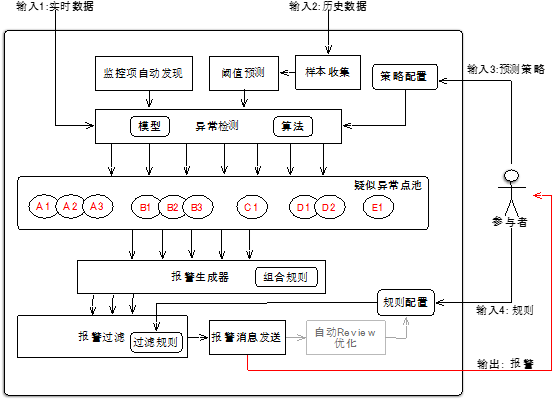
图 2 Goldeneye 报警系统架构
2、动态阈值
监控使用控制图,对监测指标的时间序列可视化,让人们可以清楚的看到指标的波动。基于控制图的监控,以往很多都是静态阈值方式,比如前面提到的静态水位线、同环比。动态阈值是为控制图的时间序列每个点,预估该点对应时刻这个指标的基准值、阈值上限、阈值下限,从而让程序可以自动判断是否有异常。因为这种预估基于过去几个月甚至更多的历史样本作为参考,所以比同环比两个数据作为参照的准确度要高。动态阈值预测的理论基础是高斯分布和均值漂移模型。
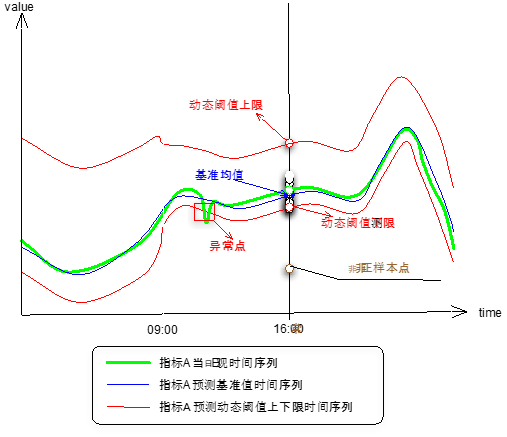
图 3 动态阈值原理
动态阈值预测的步骤主要是这样:
(1)样本选取:这个根据自己的需要,一般建议选取过去 50 天左右的样本。
(2)异常样本筛除:这个过程主要使用高斯分布函数过滤掉函数值小于 0.01,或者标准方差绝对值大于 1 的样本。
(3)样本截取:因为后来我们优化的版本,在(2)的基础上使用均值漂移模型对历史样本在时间序列上进行分段检验,如果有周期性变化、或者持续单调变化,则会反复迭代均值漂移模型寻找均值漂移点,然后截取离当前日期最近第一段(或者可以理解为最近一段时间最平稳的样本序列)。样本选取还有一个需要注意的问题,节假日和工作日的样本要分开选取,预测工作日的阈值要选择工作日的样本,节假日亦然,也就是对预测样本从日期、周末、平稳性三个维度拆分选取。
(4)预测基准值:经过(2)和(3)的筛选、截取,剩下的样本基本上是最理想的样本了,在此基础上,保持样本在日期上的顺序,按指数平滑法预测目标日期的基准值,得到基准值以后根据灵敏度或阈值系数,计算阈值上下限。
(补充说明:第四步预测基准值,有些人可能之前用过指数平滑法预测,跟第四步我们在样本权重加权时的做法很相近,但是他们预测的效果不理想,因为对样本整体没有充分的过滤选取最稳定的样本集合)
3、变点检测
动态阈值用数据统计分析的办法解决了静态阈值的误报漏报问题,节省了人工维护的成本,一定程度上降低了监控风险。不过在微量波动、持续阴跌的故障面前,动态阈值也有局限性,阈值区间收的太紧误报会增多,区间宽松就会漏报一些不太显著的故障。在 review 漏报 case 时,我们从控制图上发现这些微量波动肉眼可以观察到趋势,但是程序通过阈值区间击穿的判断方式很难控制,所以引入了均值漂移模型来寻找变点。所谓变点,就是持续微量下跌到一定时间,累积变化量到一定程度后,使得变点前后监测指标在一段时间内的均值发生漂移。
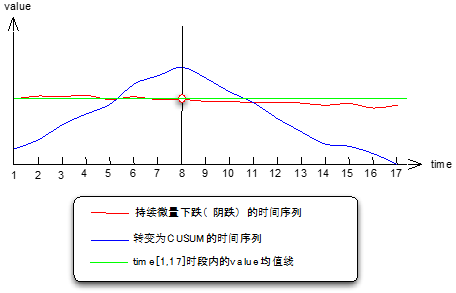
图 4 均值漂移原理
从上图可以看到,均值漂移模型的算法原理,实际上是把程序不容易识别的阴跌趋势,转换成 CUSUM 时间序列,它的趋势很明显,在变点左侧单调增、右侧单调减,CUSUM 时间序列描述了被监测时间序列每个点偏离均值的累积变化量,它的规律是从 S0=0 开始,到 Sn=0 结束,变点两侧单调变化。
CUSUM=Cumulative Sum。累积和用以在某个相对稳定的数据序列中,检测出开始发生异常的数据点。累积和最典型的应用是在“改变检测”(Change Detection) 中对参量变化的检测问题转化了以后,用程序求 CUSUM 序列上每个点的一阶导数,从持续增变为持续减即可判定为变点,至于持续增、减多少个点,由自己来设定。
关于变点检测使用的 mean-shift 模型,大家可以去网上找找 paper,我这台电脑上找不到了,上面主要说明了发现变点的原理,通俗地讲,就是把问题转化成程序容易解决的状态阴跌线程序不容易量化衡量、判断,那么就用 CUSUM 控制图里的“富士山”形状去寻找,这是我个人的通俗解释。
上面说到我们使用 CUSUM 序列上每个点的一阶导数来判断拐点(变点)是否到来,其实图上这个例子是比较理想的情况,在我应用 mean-shift 模型时,遇到了一些复杂情况,比如这个图上就一个“山头尖”,但是也时候会有多个,这种情况下就要再次转化问题,比如可以把 CUSUM 再差分,或者以我们的做法,记录一阶导数的状态值,从连续 N 个正值变为持续 N 个负值时可以判定。
另外,变点检测的算法实现我这里不方便详细说明,其中变点在反复迭代时自己可以根据实际情况设定迭代次数和置信度,有助于提高变点发现的准确性。
4、智能全景
变点检测弥补了动态阈值对细微波动的检测不足,这两种方式结合起来,基本可以达到不漏报和不误报的平衡,同时也不需要人工长期维护,这是智能全景监控的基础。当监控的人力成本节省了以后,理论上我们可以依赖智能监控无限制的开拓监控视野,并将这些监控报警连结起来分析。
监控项的自动发现规则,比如对维度 D 的指标 M 做实时监控,维度 D 下可能由 1000 种维度值,而且是不断变化的 1000 种,如何让程序自动维护监控项?你可以制定一个规则,比如指标 M>X 则认为需要监控(毕竟不是所有的都需要监控报警,至少在目前故障定位处理没有完全自动化的状况下,报警处理也是需要一定人力的)。在满足 M>X 的条件下,为了提高报警准确性,我们还需要根据重要性区分报警灵敏度,也就是对于宏观、核心的维度值我们希望能够非常灵敏的监控波动,而对于非重要的维度值我们预测阈值可以宽松一些,这些可以通过上面说的阈值参数来设定。
(说明:这个规则我这里只是举一个例子,各位同仁可以根据自己的实际场景去实现一些规则,比如系统运维层面的监控,有些是按照距离故障发生的速度或风险系数来判断,那么就可以围绕这种指标来制定,假如是对磁盘利用率的监控,就是容量增长速度与剩余资源比例作为参考等等)
以上条件都满足了之后,智能全景监控基本可以运行,不过我们也曾遇到一些其他的问题,比如业务方需要接入监控,但是不一定是必须要我们解析日志,他们有自己的数据,可能是数据库、接口返回、消息中间件里的消息等等。所以,我们在数据接入上采用分层接入,可以从日志标准输出格式、存储的时间序列 schema 约定、阈值预测的接口三个层次接入使用,这个内容将在下一次分享时由我的同事单独介绍。这里之所以提到,是因为全景监控接入的数据比较多,所以接入途径要有层次、灵活性。
5、辅助定位
报警的最终目的是减少损失,所以定位问题原因尤为重要。Goldeneye 尝试着用程序去执行人工定位原因时的套路,当然这些套路目前是通过配置生成的,还没有达到机器学习得出来的地步,不过当业务监控指标接入的越来越多,指标体系逐渐完善以后,通过统计学的相关性分析,这些套路的生成也有可能让程序去完成。这里我介绍一下,程序可以执行的人工总结处的几个套路。
(1)全链路分析
从技术架构、业务流程的角度,我们的监测指标是否正常,从外部因素分析,一般会受到它的上游影响。按照这个思路,逐一分析上游是否正常,就形成了一条链路。这种例子很多,比如系统架构的模块 A,B,C,D,E 的 QPS。
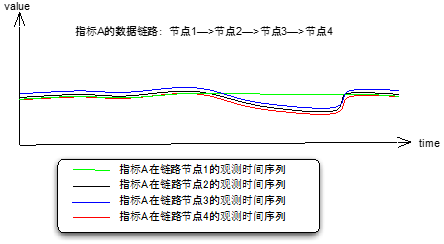
图 5 全链路 tracing
(插一句,全链路分析有两种数据记录方式,要么链路每个节点内部透传,拼接成完整链路处理信息记录到最终的节点日志;要么异步地每个节点各自将信息 push 到中间件)
(2)报警时间点上发生了什么?
这是收到监控报警后大多数人的反应,我们把运维事件、运营调整事件尽可能地收集起来,将这些事件地散点图和监测报警的控制图结合起来,就能看出问题。如果程序自动完成,就是将事件发生的时间点也按相同的方式归一化到固定周期的时间点,检查与报警时间点是否吻合。
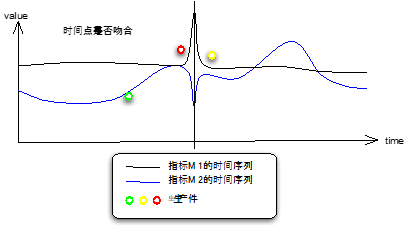
图 6 生产事件与时间序列
(3)A/B test 或 TopN
有些人定位问题,使用排除法缩小出问题的范围。比如在维度 D 上指标 M 有异常波动,可以将 D 拆分成 D1,D2,D3 来对比,常见的具体情况比如机房对照、分组对照、版本对照、终端类型对照等等,如果在监测数据层级清晰的基础上,我们可以一层一层的钻取数据做 A/B test,直到定位到具体原因。还有一种方式,不是通过枚举切分做 A/B test,而是直接以指标 M 为目标,列出维度 D 的子维度 D1,D2,D3,……中指标 M 的 TopN,找出最突出的几项重点排查。
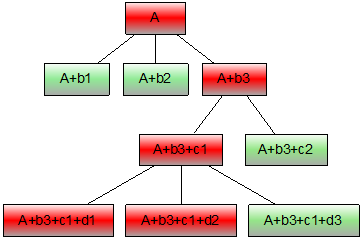
图 7 A/B test or TopN
topn 也是类似的。大家可以也能看出来,智能监控和辅助定位是需要一个清晰的数据层级和元数据管理系统来支撑的,这一点很基础。
(4)关联指标
不同的指标在监控中都是持续的时间序列,有些指标之间是函数关系,比如 ctr=click/pv,click 和 pv 的变化必然带来 ctr 的变化,这种联系是函数直接描述的。还有一些指标的关联,无法用函数公式描述,它们之间的相关性用统计学指标来衡量,比如皮尔逊系数。Goldeneye 的指标关联依据,目前还没有自动分析,暂时是人工根据经验设置的,只是视图让程序去完成追踪定位的过程,比如指标 M1 出现异常报警后能够触发相关指标 RMG1/RMG2/RMG3 的检测(因为这些指标可能平时不需要 7*24 小时监控报警,仅在需要的时候 check),以此类推逐级检测定位。
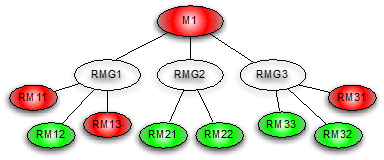
图 8 关联指标
这些方式或许大家平时也尝试着去做过一些程序化的处理,我个人认为关联指标的方式,基础在于构建指标体系,这个构建过程可以是人工经验和程序统计分析的结合,指标体系至少能够描述指标的分类、数据出处、具体含义、影响相关指标的权重等等,有了这些基础才能应用统计学的分析方法完成。
四、难点
1、时间序列平稳化
平稳化的时间序列,对预测准确性有非常重要的意义,可是我们的业务监测时间序列恰好大多数都不是平稳化的,以 5 分钟的监测周期为力,除了大盘及核心监测序列,其他的时间序列都是在一定范围内正常波动但总体趋势却是稳定的。我们目前采用的方法是:
(1)滑动平均,比如波动锯齿明显,容易造成误报干扰的化,则加大监控监测周期,将 5 分钟提高到 30 分钟,相当于拟合 6 个时间窗口的数据来平滑时间序列。
(2)持续报警判断,如果觉得 30 分钟发现问题会比较晚,可以按 5 分钟检测,锯齿波动容易发生报警,但可以连续 3 次报警再发通知,这样就避免了锯齿波动的误报。
(3)对于需要均值漂移来检测细微波动的情况,24 小时的时间序列本身有流量高峰和低谷,这种情况一般采用差分法做平滑处理,使用几阶差分自己掌握。Goldeneye 没有直接使用差分法,因为我们已经预测了基准值,所以我们使用实际监测值与基准值的 gap 序列作为变点监测的输入样本。
2、埋点代价
业务监控的监测数据来源主要是日志、业务系统模块吐出到中间件、采集接口被 push,从系统各模块吐出数据到中间件似乎比直接写入磁盘的 IO 开销小很多,不过对于请求压力比较大的系统,开旁路写出数据即使是内存级也是有一定开销的。
解决这个问题的办法是数据采样,对于在时间上分布均匀的监测数据,直接按百分比采样。
3、数据标准化
虽然数据接入是分层开放的,但是我们还是制定了标准的数据格式,比如时间序列数据存储 schema,可扩展的日志消息 proto 格式,在这些结构化数据的定义中,可以区分出业务线、产品、流量类型、机房、版本等一些标准的监控维度信息,这样做的目的是以后可以将这些监测数据和故障定位的指标相关性分析衔接起来。
但是,这些标准化的推进需要很多参与者的认可和支持,甚至需要他们在系统架构上的重构,看似是比较困难的。
目前可以想到的办法,就是在旁路吐出监测数据时,以标准化的消息格式封装,然后保证在 Goldeneye 的存储层有标准的 schema 和接口访问。
五、今后的优化方向
- 时间序列预测模型,目前的模型只考虑了日期、节假日 / 周末、时间段的因素,没有年同比趋势、大促活动影响、运营调整影响的因素,需要抽象出来。
- 指标相关性由统计分析程序来确定。
六、Q&A
Q1: 什么样的监控才能称之为智能?
马小鹏 : 这是个好问题!我也一直在考问自己,自从我开始做 Goldeneye 智能监控的那天起。截至目前,我的理解是如果一个监控系统能够具备不费人力、具备自动异常判断、有一定的辅助定位分析的特点,应该能称之为智能,这需要更多的数据去分析支持。不知道我这么解答是否可以。
Q2: 10 秒级别监控海量数据如何存储?
马小鹏 : 这个问题我想留给下一期我的两位同事,牧仁、一鸥,他们会分别从数据存储、大规模实时统计两个方面讲解。
Q3: 报警收敛中,监控项的取用报警次数怎样设定?依靠经验吗?为什么 1、2、10、50 这样的选择?
马小鹏 : 这个只是我举个例子,目前 Goldeneye 的报警收敛表达式是业务方自己配置的,可以根据检测周期的长短、监控项重要性,决定连续报警收敛跳跃的间隔。
Q4: 谢谢马老师的分享。你们所使用的的数学检测算法是否有调用比较成熟的整套的第三方的库函数?
马小鹏 : 没有用库函数,是我们自己实现的。我不了解 python 里是否实现了 mean-shift 模型,不过统计相关性的皮尔逊系数、高斯分布等基本的库,应该是有现成的。我建议你自己实现,因为可以根据实际场景,开放更多的参数去调优。
Q5: 所以说智能监控的基础是大数据处理能力?而对技术人的要求是怎样的,您当时的学习路径是怎样的?
马小鹏 : 你这是两个问题,第一智能监控的基础是大数据处理,但不完全是,因为智能的核心在于统计分析、模型抽象,对于阿里这样的公司我们不必担心计算环境以及资源,因为有人去解决,对于中小公司我觉得按照数据规模一般的计算资源还是有的,我分享的主要是智能监控的思想和技术方案。第二,大数据是当前比较热的词,它也分很多分之,比如数据处理有实时的流式计算、离线的批处理,这些都有很多开源的计算框架,还有就是数据的统计分析、ETL、机器学习等等,你主要先想清楚自己最感兴趣的是哪一方面。我个人最早接触大数据是 2012 年,离线 MR job,到后来的 storm,到现在的统计分析预测,其实没有什么固定的路线,只要找到自己的兴趣就好。希望这样讲对你有所帮助。
Q6: 你好,马老师。有个问题:阿里妈妈告警平台从问题发生到告警到问题定位,大概耗费多少时间?
马小鹏 : 你好,这个问题没有精确答案,我只能告诉你从我们使用了 A/B test 和 topn 自动对比,以及使用事件点的方式以后,比之前定位问题快了很多。但不是所有的问题都能立竿见影的提高定位效率,因为有些系统内部参数指标打埋点很难,无法全部自动化。
Q7: 你好,马老师,现在热门的 docker 容器的监控报警有什么好的解决方案,谢谢!
马小鹏 :Docker 容器我不太了解,今天分享的内容对于时间序列的监测数据,我觉得都是可以尝试的。后续我的同事波罗会介绍自动化运维有关 Docker 的分享,他们也有这方面的监控,你可以问他。
感谢木环对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论