本文最初发布于 Murat Demirbas 教授的个人博客,原作者 Murat Demirbas 教授供职于 University at Buffalo,SUNY 的计算机科学与技术系。本文经授权由 InfoQ 中文站翻译并分享。
我们的论文综述了分布式机器学习平台所使用的设计方法,并给出了一些对未来研究方向的建议。文中的工作是与我的研究生Kuo Zhang 和Salem Alqahtani 共同完成的,论文的撰写完成于2016 年秋季,成果将在ICCCN’17 会议(温哥华)上展示。
机器学习,特别是深度学习,已在语音识别、图像识别和自然语言处理以及近期在推荐及搜索引擎等领域上取得了革命性的成功。这些技术在无人驾驶、数字医疗系统、CRM、广告、物联网等领域具有很好的应用前景。当然,是资金引领和驱动了技术的加速推进,使得我们在近期看到了一些机器学习平台的推出。
考虑到训练中所涉及的数据集和模型的规模十分庞大,机器学习平台通常是分布式平台,部署了数十个乃至数百个并行运行的计算节点对模型做训练。据估计在不远的将来,数据中心的大多数任务都会是机器学习任务。
我来自于分布式系统研究领域,因此我们考虑从分布式系统的角度开展针对这些机器学习平台的研究,分析这些平台在通信和控制上的瓶颈。我们还考虑了这些平台的容错性和易编程性。
我们从设计方法上将机器学习平台划分为三个基本类别,分别是:基本数据流、参数- 服务器模型和高级数据流。
下面我们将对每类方法做简要介绍,以Apache Spark 为例介绍基本数据流,以PMLS(Petuum)为例介绍参数服务器模型,而高级数据流则使用TensorFlow 和MXNet 为例。我们对比了上述各平台的性能并给出了一系列的评估结果。要了解详细的评估结果,可参考我们的论文。遗憾的是,作为一个小型研究团队,我们无法开展大规模的评估。
在本篇博文的最后,我给出了一些结论性要点,并对分布式机器学习平台的未来研究工作提出了一些建议。对这些分布式机器学习平台已有一定了解的读者,可以直接跳到本文结尾。
Spark
在 Spark 中,计算被建模为一种有向无环图(DAG),图中的每个顶点表示一个 RDD,每条边表示了 RDD 上的一个操作。RDD 由一系列被切分的对象(Partition)组成,这些被切分的对象在内存中存储并完成计算,也会在 Shuffle 过程中溢出(Overflow)到磁盘上
在 DAG 中,一条从顶点 A 到 B 的有向边 E,表示了 RDD B 是在 RDD A 上执行操作 E 的结果。操作分为"转换"(Transformation)和"动作(Action)"两类。转换操作(例如 map、filter 和 join)应用于某个 RDD 上,转换操作的输出是一个新的 RDD。
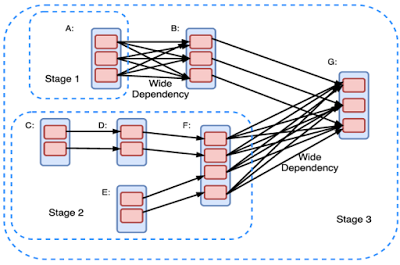
Spark 用户将计算建模为 DAG,该 DAG 表示了在 RDD 上执行的转换和动作。DAG 进而被编译为多个 Stage。每个 Stage 执行为一系列并行运行的任务(Task),每个分区(Partition)对应于一个任务。这里,有限(Narrow)的依赖关系将有利于计算的高效执行,而宽泛(Wide)的依赖关系则会引入瓶颈,因为这样的依赖关系引入了通信密集的 Shuffle 操作,这打断了操作流 。
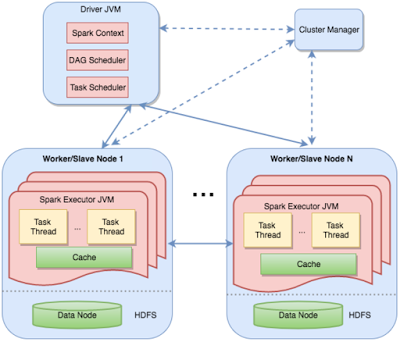
Spark 的分布式执行是通过将 DAG Stage 划分到不同的计算节点实现的。上图清晰地展示了这种"主机(master)- 工作者(worker)"架构。驱动器(Driver)包含有两个调度器(Scheduler)组件,即 DAG 调度器和任务调度器。调度器对工作者分配任务,并协调工作者。
Spark 是为通用数据处理而设计的,并非专用于机器学习任务。要在 Spark 上运行机器学习任务,可以使用 MLlib for Spark。如果采用基本设置的 Spark,那么模型参数存储在驱动器节点上,在每次迭代后通过工作者和驱动器间的通信更新参数。如果是大规模部署机器学习任务,那么驱动器可能无法存储所有的模型参数,这时就需要使用 RDD 去容纳所有的参数。这将引入大量的额外开销,因为为了容纳更新的模型参数,需要在每次迭代中创建新的 RDD。更新模型会涉及在机器和磁盘间的数据 Shuffle,进而限制了 Spark 的扩展性。这正是基本数据流模型(即 DAG)的短板所在。Spark 并不能很好地支持机器学习中的迭代运算。
PMLS
PMLS 是专门为机器学习任务而设计的。它引入了称为"参数 - 服务器"(Parameter-Server,PS)的抽象,这种抽象是为了支持迭代密集的训练过程。
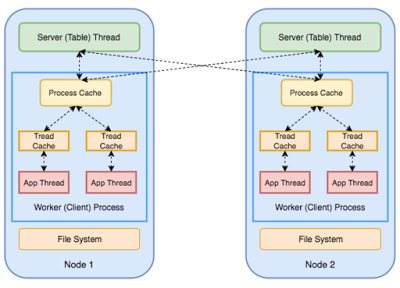
PS(在图中以绿色方框所示)以分布式 key-value 数据表形式存在于内存中,它是可复制和分片的。每个节点(node)都是模型中某个分片的主节点(参数空间),并作为其它分片的二级节点或复制节点。这样 PS 在节点数量上的扩展性很好。
PS 节点存储并更新模型参数,并响应来自于工作者的请求。工作者从自己的本地 PS 拷贝上请求最新的模型参数,并在分配给它们的数据集分区上执行计算。
PMLS 也采用了 SSP(Stale Synchronous Parallelism)模型。相比于 BSP(Bulk Synchronous Parellelism)模型 ,SSP 放宽了每一次迭代结束时各个机器需做同步的要求。为实现同步,SSP 允许工作者间存在一定程度上的不同步,并确保了最快的工作者不会领先最慢的工作者 s 轮迭代以上。由于处理过程处于误差所允许的范围内,这种非严格的一致性模型依然适用于机器学习。我曾经发表过一篇博文专门介绍这一机制。
TensorFlow
Google 给出了一个基于分布式机器学习平台的参数服务器模型,称为"DistBelief"(此处是我对DistBelief 论文的综述)。就我所知,大家对DistBelief 的不满意之处主要在于,它在编写机器学习应用时需要混合一些底层代码。Google 想使其任一雇员都可以在无需精通分布式执行的情况下编写机器学习代码。正是出于同一原因,Google 对大数据处理编写了MapReduce 框架。
TensorFlow 是一种设计用于实现这一目标的平台。它采用了一种更高级的数据流处理范式,其中表示计算的图不再需要是 DAG,图中可以包括环,并支持可变状态。我认为 TensorFlow 的设计在一定程度上受到了 Naiad 设计理念的影响。
TensorFlow 将计算表示为一个由节点和边组成的有向图。节点表示计算操作或可变状态(例如 Variable),边表示节点间通信的多维数组,这种多维数据称为"Tensor"。TensorFlow 需要用户静态地声明逻辑计算图,并通过将图重写和划分到机器上实现分布式计算。需说明的是,MXNet,特别是 DyNet,使用了一种动态定义的图。这简化了编程,并提高了编程的灵活性。
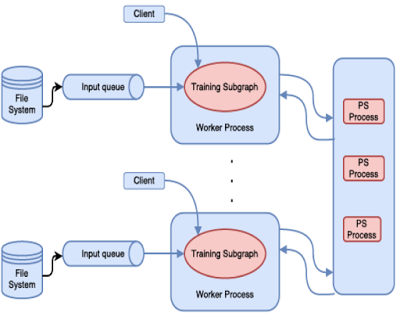
如上图所示,在 TensorFlow 中,分布式机器学习训练使用了参数 - 服务器方法。当在 TensorFlow 中使用 PS 抽象时,就使用了参数 - 服务器和数据并行。TensorFlow 声称可以完成更复杂的任务,但是这需要用户编写代码以通向那些未探索的领域。
MXNet
MXNet 是一个协同开源项目,源自于在 2015 年出现的 CXXNet、Minverva 和 Purines 等深度学习项目。类似于 TensorFlow,MXNet 也是一种数据流系统,支持具有可变状态的有环计算图,并支持使用参数 - 服务器模型的训练计算。同样,MXNet 也对多个 CPU/GPU 上的数据并行提供了很好的支持,并可实现模型并行。MXNet 支持同步的和异步的训练计算。下图显示了 MXNet 的主要组件。其中,运行时依赖引擎分析计算过程中的依赖关系,对不存在相互依赖关系的计算做并行处理。MXNet 在运行时依赖引擎之上提供了一个中间层,用于计算图和内存的优化。
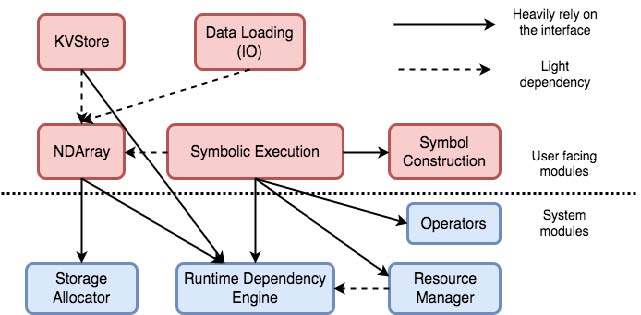
MXNet 使用检查点机制支持基本的容错,提供了对模型的 save 和 load 操作。save 操作将模型参数写入到检查点文件,load 操作从检查点文件中读取模型参数。
MXNet 使用描述式编程语言表述计算为一个有向图,也支持使用一些指令式编程去定义 tensor 的计算和控制流。MXNet 提供了多种语言(例如 C++、Python、R 和 Scala 等)编写的客户端 API。与 TensorFlow 一样,MXNet 的后台核心引擎库同样是使用 C++ 编写的。
部分评估结果
在我们的实验中,使用了 Amazon EC2 m4.xlarge 实例。每个实例具有 4 个由 Intel Xeon E5-2676 v3 实现的 vCPU,及 16GB 的内存,EBS 带宽是 750Mbps。我们对两种常见的机器学习任务进行了实验,它们分别是二分类逻辑斯蒂回归和使用多层神经网络的图像分类。本文中只给出了部分结果图,更多的实验结果可参见我们的论文。需指出的是,我们的实验具有一些局限性。首先,我们使用机器数量不大,不能测试扩展性。其次,我们也只使用了 CPU 计算,并未测试 GPU 的使用情况。
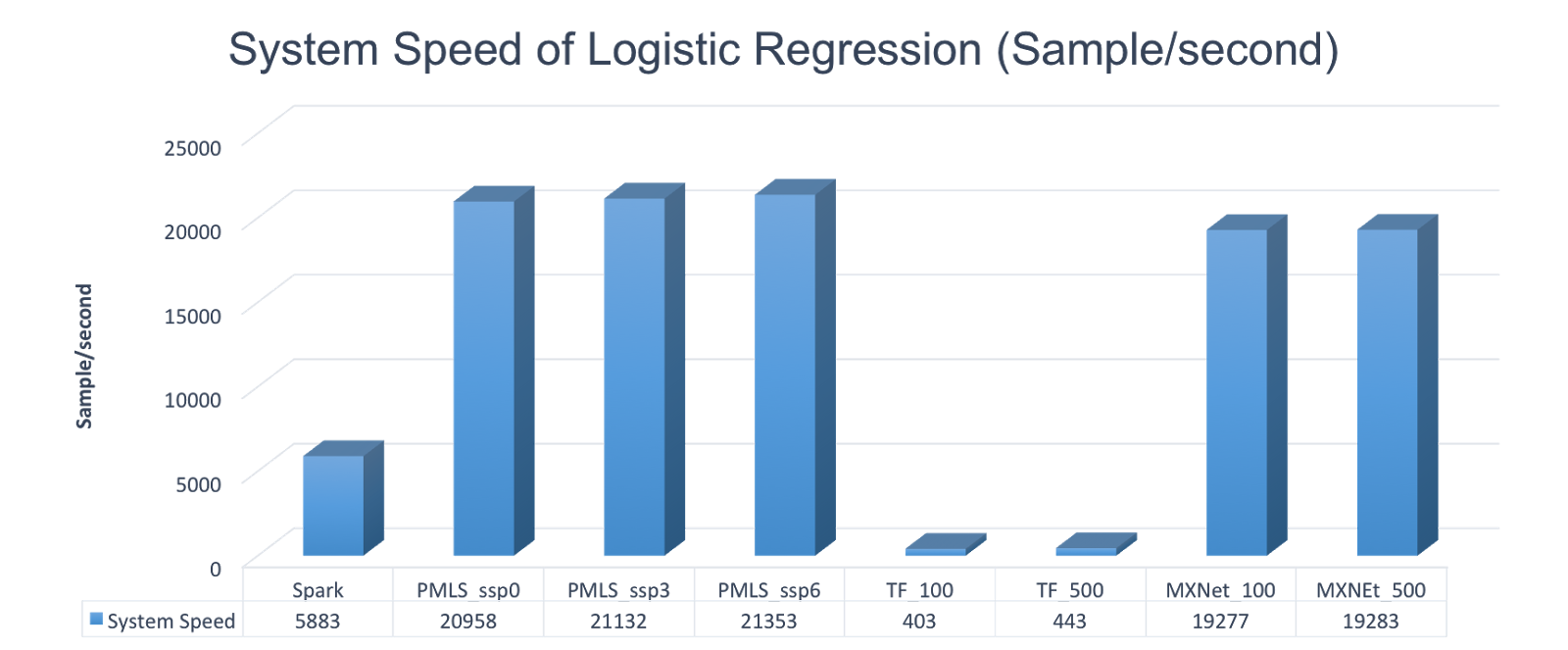
该图展示了各个平台对逻辑斯蒂回归的计算速度。PMLS 和 MXNet 是最快的两个系统,TensorFlow 速度最慢,而 Spark 介于两者之间。对此,我们分析有多个导致原因。首先,相比于 Spark 和 TensorFlow,PMLS 是一个轻量级系统,它是采用高性能 C++ 编程语言实现的,而 Spark 是使用运行在 JVM 上的 Scala 语言编写的。其次,PMLS 中包含的抽象较少,而 TensorFlow 中则具有过多的抽象。抽象增加了系统的复杂度,并导致运行时开销。
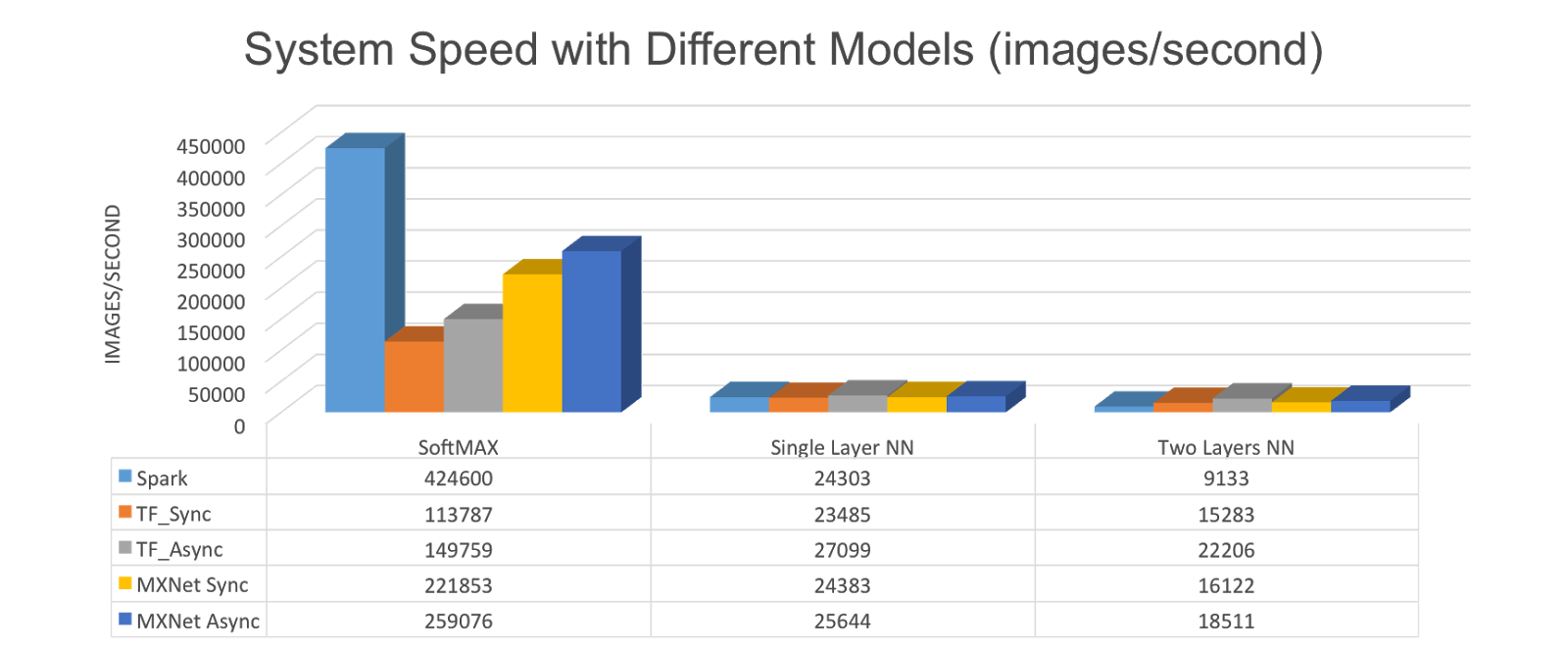
该图展示了 DNN 在各个平台上的速度。相比于单层神经网络,当发展到两层神经网络时,由于需要更多的迭代计算,Spark 的性能下降。我们将模型参数存储在 Spark 的驱动器中,因为驱动器可以容纳这些参数。但是如果我们使用 RDD 保持参数,并在每次迭代后做更新,结果可能会更差。
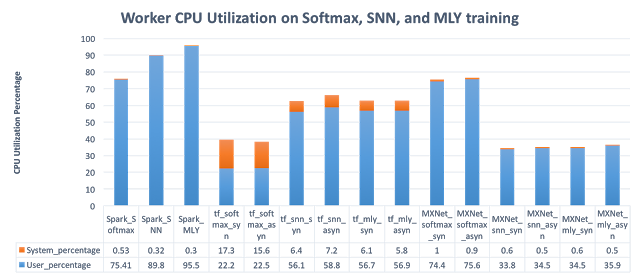
该图展示了平台的 CPU 使用率。Spark 应用看上去具有偏高的 CPU 占用率,这主要来自于序列化的开销。有些前期工作也指出了同一问题。
结论及未来的研究方向
机器学习和深度学习应用是高度可并行的,但是从并发算法角度看,要做到并不那么容易。可以说,参数- 服务器方法最适合于分布式机器学习平台的训练任务。
考虑到瓶颈,网络依然是分布式机器学习应用的瓶颈。相比于更高级的通用数据流平台,更重要的是要提出对数据和模型的更好组织和参与机制。应将数据和模型视作一等公民。
此外,还有其它一些因素对平台具有微妙的影响。对于Spark,CPU 开销成为比网络局限更严重的瓶颈问题。Spark 使用的编程语言是Scala 等JVM 语言,这对Spark 的性能具有显著的影响。因此存在着对更好的监控工具以及对分布式机器学习平台性能预测的需求。近期已经出现了一些工具,例如 Ernest 和 CherryPick ,它们解决了一些 Spark 数据处理应用上的问题。
对于支持机器学习的运行时分布式系统,依然存在着一些开放问题,例如资源调度和运行时性能改进。考虑到应用的运行时监控和性能分析,下一代的分布式机器学习平台应提供对运行于平台上任务的计算、内存、网络资源的运行时弹性配置和调度等能力。
在编程和软件工程的支持上,也同样有一些开放问题。什么是适合机器学习应用的分布式编程抽象?这些问题还需要做进一步的研究,并对分布式机器学习应用进行检验和验证,例如使用特定问题输入测试 DNN。
阅读英文原文: A Comparison of Distributed Machine Learning Platforms 。
感谢 蔡芳芳 对本文的审校。




