
英伟达发布PrefixRL,一种基于强化学习(RL)的方法,用它设计的并行前缀电路比用最先进的电子设计自动化(EDA)工具设计的并行前缀电路更小、更快。
GPU 中各种重要的电路,如加算器、递增器和编码器被称为并行前缀电路。这些电路是高性能数字设计的基础,可以在更高的级别上被定义为前缀图。PrefixRL 专注于这类运算电路,其主要目标是了解 AI 代理是否可以设计出一个好的前缀图,因为这个问题的状态空间是 O(2^n^n),所以不能使用暴力破解的方法解决。
理想的电路应该体积小、速度快、耗电少。英伟达发现,功耗与电路的面积密切相关,但电路面积和延迟往往是相互竞争的特性。PrefixRL 的目标是找到面积和延迟之间的有效权衡:在更小的面积上安装更多的电路,减少芯片的延迟,以提高性能和减少功耗。
Hopper GPU是英伟达最新的架构,有近 13000 个电路是由 AI 设计的。
PrefixRL 代理是用全卷积神经网络(Q-learning 代理)进行训练的。Q 网络的输入和输出都有一个前缀图的网格表示,网格中的每一个元素都唯一地映射到一个前缀节点。输入网格中的每一个元素表示节点是否存在。在输出端,每个元素表示用于添加或删除节点的 Q 值。PrefixRL 代理分别预测面积和延迟的值,因为这些属性在训练时是分开观察的。
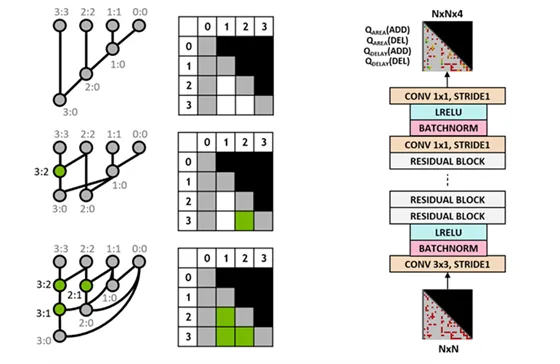
前缀图表示(左)和完全卷积 Q-learning 代理架构(右)
RL 代理可以在前缀图中添加或删除节点,在强化学习任务的每一个步骤中,代理都会收到相应电路面积的改进和延迟作为奖励。在其他步骤中,设计过程是这样的:合法化前缀图,始终保持正确的前缀和计算,然后根据合法化前缀图生成一个电路。最后,用物理合成工具对电路进行优化,设计过程的最后一步是测量电路的面积和延迟特性。
面积和延迟之间的最佳权衡,即设计的帕累托边界,是通过训练大量不同权重(从 0 到 1)的代理来获得的。因此,在 RL 环境下的物理综合优化可以产生各种各样的解决方案。这个合成过程很慢(64 位加算器大约需要 35 秒),计算量也很高,物理模拟每个 GPU 对应 256 个 CPU,64 位的训练需要超过 32000 个 GPU 小时。
对于这种 RL 任务,英伟达开发了 Raptor,一个内部分布式强化学习平台,利用了英伟达的硬件优势。提高这类 RL 任务可伸缩性和训练速度的核心特性是:作业调度、GPU 感知的数据结构和自定义网络。为了提高网络性能,Raptor 能够在NCCL(用于点对点传输,直接从学习 GPU 传输模型参数到推断 GPU)、Redis(用于异步操作和较小的消息传输,如奖励或统计)和 JIT 编译的 RPC(用于处理高容量和低延迟的请求,如上传经验数据)之间切换。
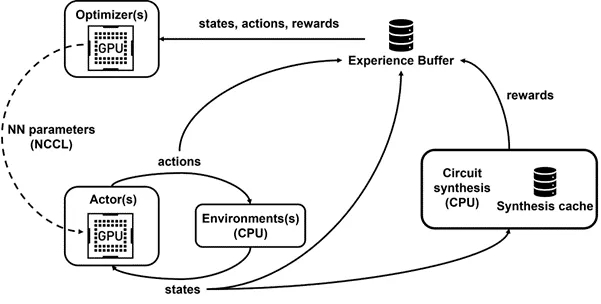
英伟达的框架支持并行训练和数据收集
Raptor 提高了训练速度,让代理无需等待通过环境的步骤,这要归功于 CPU Worker 池并行执行物理合成。为了避免相同状态下的冗余计算,当 CPU Worker 返回奖励时,转换被插入到重放缓冲区中,奖励被缓存下来。
在相同的延迟条件下,RL 加算器比 EDA 加算器面积小 25%,而且结构不规则。这一成绩是通过 RL 代理学习利用合成电路特性的反馈从头设计电路来实现的。
原文链接:
PrefixRL: Nvidia's Deep-Reinforcement-Learning Approach to Design Better Circuits




