
有网友在 Twitter 上评价道:“这就是中国大模型研发现状?”
李开复的 Yi-34B 被指是对 LLaMA 的重构
近日,国外开发者 ehartford 在开源大模型 Yi-34B 的 Hugging Face 主页上评论称,除了对两个张量做重命名之外,Yi 团队完全使用了 LLaMA 架构(input_layernorm, post_attention_layernorm) https://github.com/turboderp/exllamav2/commit/6d24e1ad40d89f64b1bd3ae36e639c74c9f730b2 由于 LLaMA 架构涉及大量投资和工具,因此保留全部张量的原名称显然更好。开源社区肯定会重新发布 Yi 模型并调整张量名称,制作出符合 LLaMA 架构的新版本。我们希望贵团队能在模型被广泛部署之前也能官方采取这项调整,确保成果最终得到妥善使用。
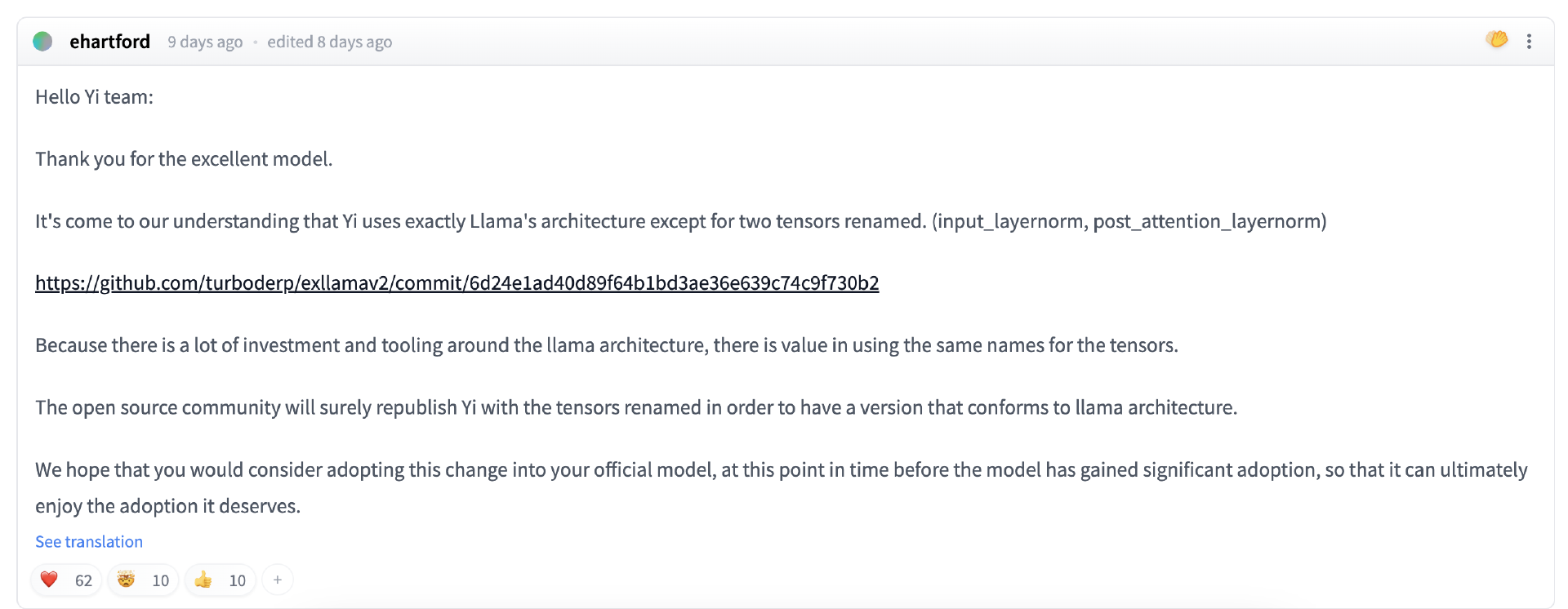
ehartford 补充道,他只是提醒 Yi 团队调整张量名称来匹配相关资源,直接套用 LLaMA 架构没有任何问题,训练才是重点。
网友 brucethemoose 认为,不仅如此,Yi-34B 还是对 LLaMA 代码的重构,而且似乎没有做任何改动。这显然就是在原始 Apache 2.0 llama 文件的基础上稍做调整,却没有提及 LLaMA:https://www.diffchecker.com/bJTqkvmQ/
brucethemoose 提到:
这些调整并没有 PR 到 Transformer 当中,只是作为外部代码被添加了进来,这样可能引发安全风险、或者与框架发生冲突。HuggingFace 排行榜甚至不打算对其 200K 版本做基准测试,因为该模型根本没有自定义代码政策。他们宣称这是套 32K 模型,但实际配置为 4K 模型,没有 RoPE 拉伸配置,也没有解释应该如何拉伸。目前,关于其如何调校数据的信息完全为零。他们并未提供重现基准测试结果的说明,包括高到可疑的 MMLU 得分。
任何对 AI 稍有了解的朋友都会意识到其中的问题。这是纯粹在吹牛?吹完了就跑?违反许可证要求?在基准测试里作弊?都有可能,但却没人在乎。反正他们可以继续发论文,或者是骗走死而一大笔风险投资。至少在这个圈子里,Yi 还算是高于平均水平,毕竟它总归是套基础模型、而且性能似乎的确不错。
有不少网友与 brucethemoose 观点相同,认为 Yi-34B 纯粹就是 LLaMA 的复制粘贴,再对部分张量重新命名,“太丢人了”。网友 JosephusCheung 表示,如果 Yi 团队用的就是 Meta LLaMA 原架构、代码库还有相关资源,那就必须得遵守 LLaMA 所规定的许可协议。换句话说,如果直接按照 LLaMA 的形式发布 Yi 模型,那么 Yi 许可中的很多条款也就无法成立。我认为这种行为非常粗鲁,Yi 团队明显对许可证制度缺乏应有的尊重。有些事情开源社区可以做,但商业实体绝对不行。
网友 turboderp 认为,提交当中涉及一些重构,但也有一项用来对 RMSNorm 模块的键进行重命名的变更:如果模型的 config 文件识别到模型为“YiForCausalLM”,则“input_layernorm”为“In1”且“post_attention_layernorm”为“In2”。“据我所知,除此之外 Yi-34B 的架构与 LLaMA 没有任何区别。其实 OpenLLaMA 也是类似的情况。虽然 Yi-34B 的词库有两倍大,但它仍然是个 SentencePiece 模型而且能够正常运行。所以我们很难说 Yi-34B 算不算新成果。其架构在 modeling_yi.py 中布局,而且除了张量名称的调整之外,看起来跟 LLaMA 一模一样。当然,可能还有其他被我忽略掉的差异。”
值得一提的是,前几日,阿里前技术副总裁、大模型行业创业者贾扬清曾在朋友圈中提到,有个“大厂新模型 exactly 就是 LLaMA 的架构,但是为了表示不一样,把代码里面的名字从 LLaMA 改成了他们的名字,然后换了几个变量名。然后,海外有工程师直接指了这一点出来... 还有人在 HF 上面放了个把名字改回去的 checkpoint,说好了,现在你们可以直接用 LLaMA 的代码来 load 这个 checkpoint 了”。
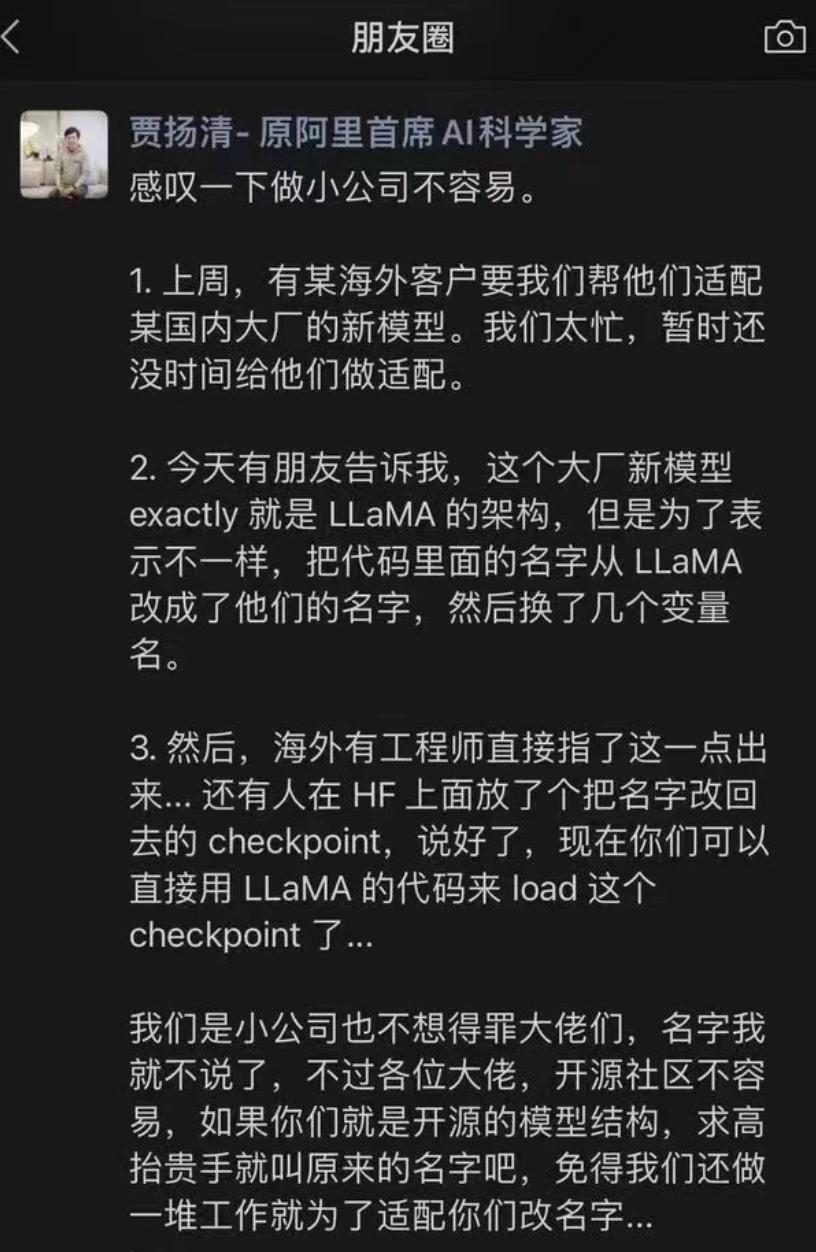
贾扬清虽然没有指明具体的大模型名字,但有观点怀疑其指的很可能就是零一万物旗下的 Yi-34B。
零一万物回应争议:基于 GPT 研发,将进行代码更新
对于本次争议,零一万物回应称:GPT 是一个业内公认的成熟架构,LLaMA 在 GPT 上做了总结。零一万物研发大模型的结构设计基于 GPT 成熟结构,借鉴了行业顶尖水平的公开成果,由于大模型技术发展还在非常初期,与行业主流保持一致的结构,更有利于整体的适配与未来的迭代。同时零一万物团队对模型和训练的理解做了大量工作,也在持续探索模型结构层面本质上的突破。
零一万物团队开源总监 richardllin 回应 ehartford 称:
非常感谢您在讨论中指出了这一点,也感谢您以良好的耐心等待我们做出回复。
您对张量名称的看法是正确的,我们会按照您的建议将其从 Yi 重命名为 LLaMA。我们也一直强调以准确、透明的方式完成工作。
您在前面的帖子中提到,“开源社区肯定会重新发布 Yi 模型并调整张量名称,制作出符合 LLaMA 架构的新版本。”这让我们不禁好奇:您是希望提交一条包含这些变更的 PR 吗?或者说,如果您希望由我们处理更新,我们也可以按要求操作并在本 repo 中发布新版本——这样可能更省时间。
这个命名问题是我们的疏忽。在大量训练实验中,我们对代码进行了多次重命名以满足实验要求。但在发布正式版本之前,我们显然没能将它们全部正确调整回来。我们对此深感抱歉,对于由此造成的混乱也感到遗憾。
我们正在努力加强工作流程,力争未来不出现类似的失误。您的反馈给了我们很大帮助,接下来我们将再次核查所有代码,确保其余部分准确无误。也希望您还有整个社区持续关注我们的工作进展。
再次感谢您的提醒,期待您的更多支持和宝贵建议。
11 月 15 日,零一万物发布了最新的详细说明:
就零一万物的观察和分析,大模型社区在技术架构方面现在是一个处于接近往通用化逐步收拢的阶段,基本上国际主流大模型都是基于 Tranformer 的架构,做 attention,activation,normalization,positional embedding 等部分的改动,LLaMA、Chinchilla、Gopher 等模型的架构和 GPT 架构大同小异,全球开源社区基于主流架构的模型变化非常之多,生态呈现欣欣向荣,国内已发布的开源模型也绝大多数采用渐成行业标准的 GPT/LLaMA 的架构。然而,大模型持续发展与寻求突破口的核心点不仅在于架构,而是在于训练得到的参数。
模型训练过程好比做一道菜,架构只是决定了做菜的原材料和大致步骤,这在大多数人的认知中也逐步形成共识。要训练出好的模型,还需要更好的“原材料”(数据)和对每一个步骤细节的把控(训练方法和具体参数)。由于大模型技术发展还在非常初期,从技术观点来说,行业共识是与主流模型保持一致的模型结构,更有利于整体的适配与未来的迭代。
零一万物在训练模型过程中,沿用了 GPT/LLaMA 的基本架构,由于 LLaMA 社区的开源贡献,让零一万物可以快速起步。零一万物从零开始训练了 Yi-34B 和 Yi-6B 模型,并根据实际的训练框架重新实现了训练代码,用自建的数据管线构建了高质量配比的训练数据集(从 3PB 原始数据精选到 3T token 高质量数据)。除此以外,在 Infra 部分进行算法、硬件、软件联合端到端优化,实现训练效率倍级提升和极强的容错能力等原创性突破。这些科学训模的系统性工作,往往比起基本模型结构能起到巨大的作用跟价值。
零一万物团队在训练前的实验中,尝试了不同的数据配比科学地选取了最优的数据配比方案,投注大部分精力调整训练方法、数据配比、数据工程、细节参数、baby sitting(训练过程监测)技巧等。这一系列超越模型架构之外,研究与工程并进且具有前沿突破性的研发任务,才是真正属于模型训练内核最为关键、能够形成大模型技术护城河 know-how 积累。在模型训练同时,零一万物也针对模型结构中的若干关键节点进行了大量的实验和对比验证。举例来说,我们实验了 Group Query Attention(GQA)、Multi-Head Attention(MHA)、Vanilla Attention 并选择了 GQA,实验了 Pre-Norm 和 Post-Norm 在不同网络宽度和深度上的变化,并选择了 Pre-Norm,使用了 RoPE ABF 作为 positional embedding 等。也正是在这些实验与探索过程中,为了执行对比实验的需要,模型对部分推理参数进行了重新命名。
在零一万物初次开源过程中,我们发现用和开源社区普遍使用的 LLaMA 架构会对开发者更为友好,对于沿用 LLaMA 部分推理代码经实验更名后的疏忽,原始出发点是为了充分测试模型,并非刻意隐瞒来源。零一万物对此提出说明,并表达诚挚的歉意,我们正在各开源平台重新提交模型及代码并补充 LLaMA 协议副本的流程中,承诺尽速完成各开源社区的版本更新。
我们非常感谢社区的反馈,零一万物在开源社区刚刚起步,希望和大家携手共创社区繁荣,在近期发布 Chat Model 之后,我们将择期发布技术报告,Yi Open-source 会尽最大努力虚心学习,持续进步。
开源社区讨论参考:
https://huggingface.co/01-ai/Yi-34B/discussions/11#6553145873a5a6f938658491
340 亿参数开源大模型 Yi-34B
据悉,开源大模型 Yi-34B 来自李开复旗下 AI 大模型创业公司“零一万物”,该模型发布于 2023 年 11 月 6 日。今年 7 月,李开复博士正式官宣并上线了其筹组的“AI 2.0”新公司:零一万物。此前李开复曾表示,AI 大语言模型是中国不能错过的历史机遇,零一万物就是在今年 3 月下旬,由他亲自带队孵化的新品牌。
Yi-34B 是一个双语(英语和中文)基础模型,经过 340 亿个参数训练,明显小于 Falcon-180B 和 Meta LlaMa2-70B 等其他开放模型。零一万物团队对其进行了一系列打榜测试,具体成绩包括:
Hugging Face 英文测试榜单,以 70.72 分数位列全球第一;
以小博大,作为国产大模型碾压 Llama-2 70B 和 Falcon-180B 等一众大模型(参数量仅为后两者的 1/2、1/5);
C-Eval 中文能力排行榜位居第一,超越了全球所有开源模型;
MMLU、BBH 等八大综合能力表现全部胜出,Yi-34B 在通用能力、知识推理、阅读理解等多项指标评比中“击败全球玩家”;
......
对于模型尺寸的选择,零一万物团队认为,34B 是一个黄金尺寸。虽然 6B 也能在某些领域,比如客服上可用,但模型毕竟越大越好,但随之而来的就是推理成本和后续训练的系列资源问题。
“34B 不会小到没有涌现或者涌现不够,完全达到了涌现的门槛。同时它又没有太大,还是允许高效率地单卡推理,而且不一定需要 H 和 A 级别的卡,只要内存足够,4090 或 3090 都是可以使用的。”李开复解释道,“既满足了精度的要求,训练推理成本友好,达到涌现的门槛,是属于非常多的商业应用都可以做的。”
另外,李开复提到,通用模型决定了行业模型的天花板。虽然行业大模型有相当大的价值,但是底座如果不好,也无法完成超过底座的事情,所以选底座就要选表现最好的底座。李开复自信地表示,“今天我们在中英文上就是最好的底座,没有之一,也希望更多人选择 Yi-34B。”
参考链接:
https://huggingface.co/01-ai/Yi-34B/discussions/11
https://news.ycombinator.com/item?id=38258015




