近年来,我国快递行业随着互联网和电子商务的发展而成长起来,其发展势头迅猛,国家邮政局统计数据显示,2016 年全国快递业务量达 312.8 亿件,同比增长 51.7%,中国快递业已经连续六年每年增长超过 50%,中国已成全球第一快递大国。随着快递量的持续增长,快递在给我们每个人生活带来很大便利的同时,也带来了快递企业包装成本的上升和严重的快递包裹材料浪费污染问题,2016 年全国快递共消耗编织袋约 32 亿条、塑料袋约 68 亿个、37 亿个包装箱以及 3.3 亿卷胶带。包装过度,大材小用,回收使用率低造成了包装成本的上升、用户体验的降低和资源的极大浪费,包装耗材的低碳化、环保化亟待加强。
苏宁物流研发大数据团队,利用历史数据分析和大数据算法技术,推出“智能包装解决方案”,结合客户订单信息、商品主数据,包装耗材数据等相关数据进行大数据算法模型优化,自动为顾客商品确认包装材料类型、包装应用、确定装箱顺序和装箱位置,实现包装的智能化应用。通过智能包装解决方案在仓库包装的应用,每年可为苏宁物流节约包装成本近千万。同时,通过新包装材料(可回收利用“漂流箱”)的推广使用,促进了包装减量化和循环利用,不仅仅节约包装成本,提升用户体验,更重要的是能够保护环境和节约资源。每个漂流箱循环使用 2000 次,大约可节约 1 棵 10 年树龄的树木。漂流箱在全国范围投放,每年节省下来的快递盒可绕地球一圈。
苏宁智能包装解决方案技术
合单与拆包
合单与拆包可以理解为两个“相反”的操作,简而言之,合单是将同一时间窗口内的相同收货地址的订单合并化零为整,拆包则是再将一个订单根据业务逻辑拆成多个包裹进行派送。两个操作的目的都是为了提高客户收货体验。
为了保证合单的效率,我们只考虑同一个时间窗口内产生的订单进行合并而不是对全天的订单进行合并。在同一时间窗口内,每个订单将会与其他订单做匹配,如果发现多个订单共用一个收货地址,系统将自动将这些订单合并到一起,化零为整。由于商品有不同的属性以及包装材料大小的限制,同一订单需要拆分成多个包裹进行打包。例如,客户在大促时买了大量厕所清洁产品和食品两类商品,如果将两类商品混合打包到一个包裹中,将大大降低客户体验,因此我们将两类商品分开,分别打包到不同的包裹中进行派送。同时,如果两个包裹装不下客户的所有商品,那我们再将商品分装到多个包裹中。
完成合单与拆包并确定包装材料的数量与种类后,下一步系统将会调用包装推荐算法推荐合适大小的包装材料。
包装推荐
装箱问题在物流与生产系统中是一个经典并且非常重要的优化问题。系统通过包装推荐功能找到合适大小的包装材料推荐给业务操作人员来包装客户的商品,而包装推荐就是装箱问题的一个典型应用,其本质就是如何合理的放置商品以达到包装箱的装填率最大化。2 维装箱问题已被证明是个 NP-hard(Coffman et al., 1980)问题,NP 是指非确定性多项式(non-deterministic polynomial,缩写 NP)。所谓的非确定性是指,可用一定数量的运算去解决多项式时间内可解决的问题。NP-hard 问题通俗来说是其解的正确性能够被“很容易检查”的问题,这里“很容易检查”指的是存在一个多项式检查算法。相应的,若 NP 中所有问题到某一个问题是图灵可归约的,则该问题为 NP 困难问题。同理可得,3 维装箱问题也是个 NP-hard 问题。
3 维装箱数学模型

约束条件(1),(2),(3)和(4)一起用来确保放置商品时,不会存在不同商品位置重叠的情况。约束条件(5),(6)和(7)确保商品不会被放置到包装材料外面。对于同个商品,不同的放置方式,将会有不一样的长、宽、高。,约束条件(8),(9)和(10)用来重定义商品i 长、宽、高。在本段开头,我们已经假设所有商品为规则的长方体,而一个长方体商品一共有三个不同的面,每个面为底有两种摆法,所以一个商品一共有6 种不同的放置方式。6 种放置方式如下图所示。
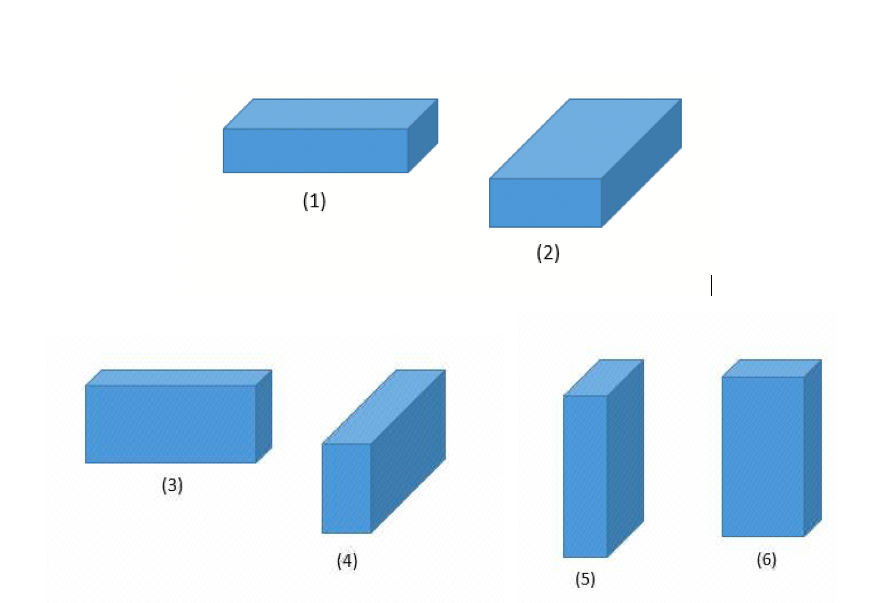
6 种放置方式

由模型可见该问题为一个混合整数非线性规划问题,由于该类问题的复杂性,其不可能在合理时间内获得精确解。简而言之,该问题很难在合理的时间内被求解出来,不能满足我们业务实时计算反馈推荐的需求,因此我们开发了自己的包装推荐算法去寻找较好的可行解。
包装推荐算法
对于装箱问题,直接影响到装填率的因素有两个,分别是商品装箱顺序和商品装箱位置。针对这两个因素,我们分别使用了不同的优化算法进行求解。首先,我们使用了遗传算法对商品装箱顺序进行优化计算,然后我们使用了 3 维装箱算法对商品装箱位置进行优化计算。
整体流程
整个包装推荐算法流程如下图所示。我们首先将包装箱按最长边降序排列,筛选出符合最长边和体积要求的包装材料。
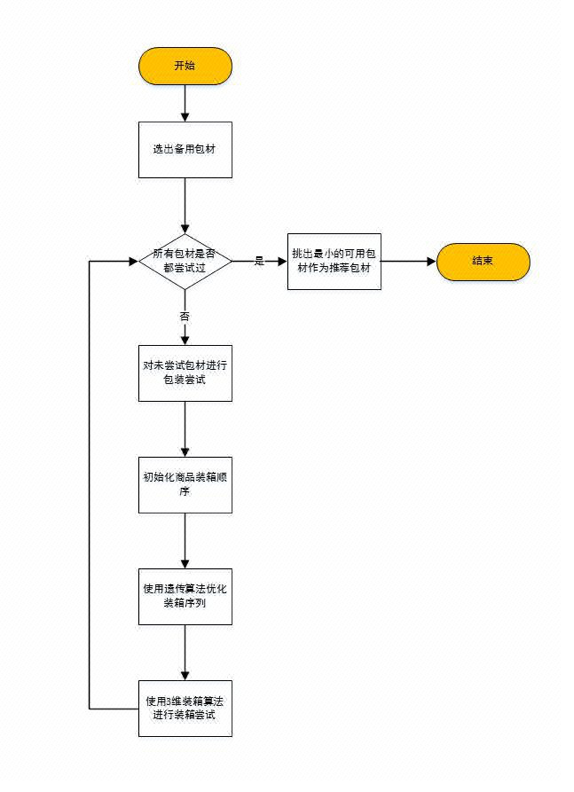
包装推荐算法流程图
然后我们初始化商品装箱序列,并使用遗传算法对商品装箱序列进行调整。在评估当前顺序的适应度时,我们调用3D 装箱算法对商品进行放置,若装箱算法依照当前装箱顺序能将所有商品打包进包装材料,则停止计算。否则,继续遗传算法对装箱顺序进行调整,再评估新顺序的适应度。在往同一个包裹放置多于一件商品的情况下,由于只依靠最长边与体积无法确定商品是否都能装下,因此我们需要用遍历的方式把所有的包材依照上面的逻辑全部计算一遍,然后找出装填率最高的一种包材。
前面我们大致介绍了下包装推荐算法的整体计算流程,接下来我们将深入到细节,给大家详细介绍下算法每个模块的实现逻辑。
装箱顺序优化
在打包多件商品的情况下,通过改变商品的装箱顺序能获得不同的装箱效果。如下图所示先放置小件商品和先放置大件商品会得到不同的装箱结果。
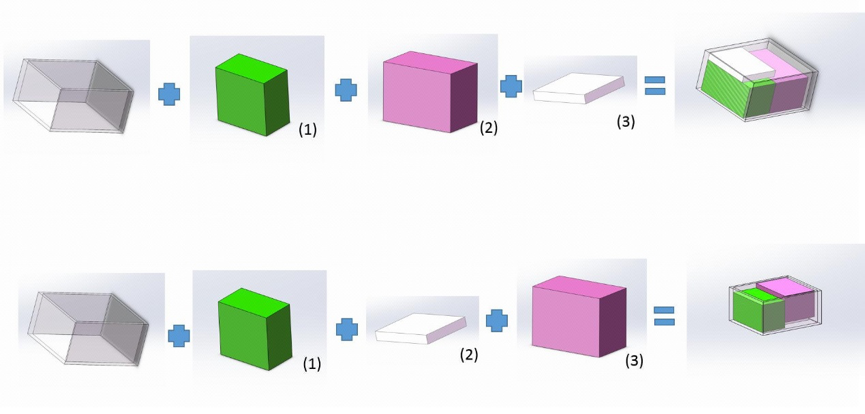
装箱顺序对比图
遗传算法具有很好的全局寻优能力,因此我们选择了该算法去优化装箱顺序。遗传算法(Genetic Algorithm)是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。我们使用了实数编码方式生成代表装箱顺序的基因种群。然后在进化的过程中,我们对选中的父代基因进行交叉(Crossover)与变异(Mutation)操作。如下图所示,基因的交叉就是对选中的两条基因进行元素交换以生成新的子代。交叉的方式有很多种,在此我们罗列出比较常用的几种方式。
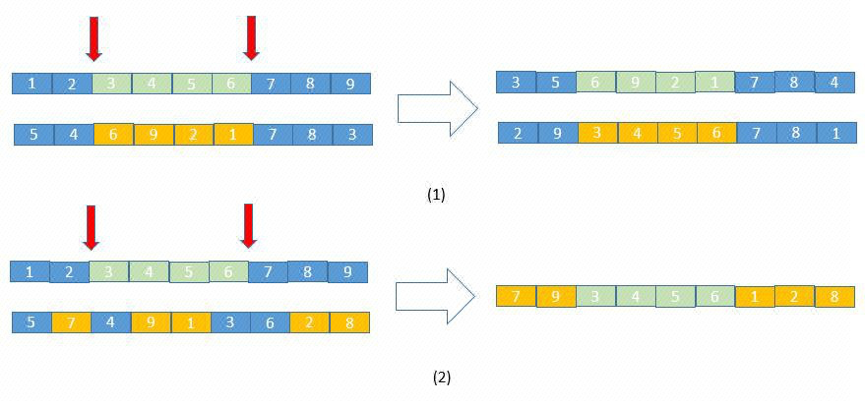
基因交叉示例图
交叉操作主要是使种群内的信息能够进行局部交换获得新的子代,而变异操作是为了使种群内能够加入新的随机信息。由于这个随机的新信息有可能是有利于向最优解收敛的有益信息,也有可能是使搜索偏离最优解的误导信息,因此我们需要慎重地使用变异操作。我们使用了概率值来控制变异操作,当达到一定概率时,变异操作才会被激活从而获取新的随机信息。相对于交叉操作,变异操作是针对于单条基因进行变换操作。变异的方式也有很多,下图中展示了最常用的几种变异方式。
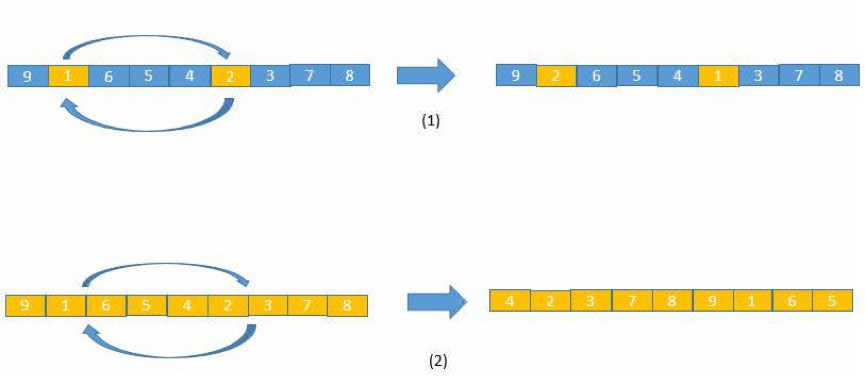
基因变异示例图
完成交叉与变异操作后,我们需要对新获得的基因组进行评估。我们依据新获得的基因即装箱顺序,调用3 维装箱算法去尝试装箱。
装箱位置优化
除了装箱顺序外,在打包商品时,商品的放置位置也直接影响到最终的装箱效果。装箱位置包含了商品在包装箱内的放置位置与放置方式两个子问题。下面两个对比图分别展现了商品不同放置位置与不同放置方式最终对装箱结果的影响。
不同放置位置与不同放置方式对比图
在已知装箱顺序后,3 维装箱算法决定如何寻找合适的商品放置位置与放置方式。每次放置一个商品时,我们会尝试6 种不同的商品放置方式,看哪种能在箱子里放得下。每放置一个商品到一个长方形空间里时,我们称未被商品占去位置的空闲空间为残存空间(residual space)。算法对残存空间进行切割,保留能留下最大残存空间的切割方式。因为留下的残存空间越大,那之后更有可能装下剩下的商品。算法将贪婪得采用6 种商品放置方式当中能生成最大残存空间的放置方式,以保证剩下的商品能顺利装箱。
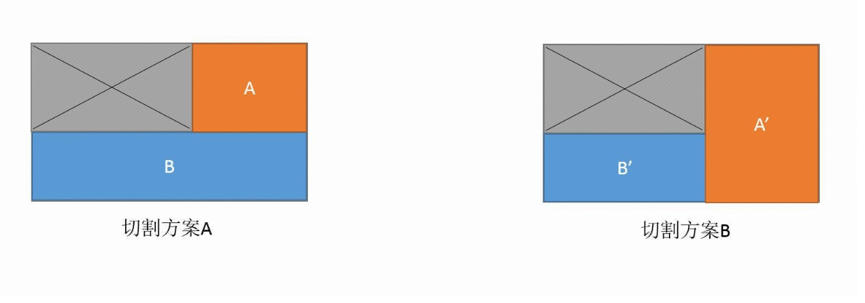
切割方案对比图
上图为两种不同的切割方式对比图。灰色区域为前一个商品放置位置,A、B、A’和B’为两种不同切割方式所产生的不同的残存空间,由于A’的面积大于B,所以我们倾向保留切割方案B。
在放置商品的过程中,完整的空间被不断得切割成更小的残存空间,当剩余的商品在所有的残存空间里放不下时,算法就考虑调整一些残存空间以获得更合适的空间来放置商品。调整的方式可以千变万化,但是计算时间有限,因此我们人为缩小了搜索空间:只有两个在同一水平面并共享一个顶点和一条边的残存空间算法才尝试调整。算法从所有的残存空间里挑出满足条件的两个残存空间尝试进行调整,即在同一水平面并且共享一个顶点及一条边。如下图所示,调整前的残存空间分别为A 和B,两个空间共享一个顶点及一条边。算法将会尝试将残存空间进行调整,生成新的残存空间A’ 和B’来尝试装箱。若新产生的残存空间可以放置一个商品,那我们保留该调整方案,否则我们尝试调整其余残存空间。通过对残存空间的调整,我们更有效的利用了包装箱的空间。
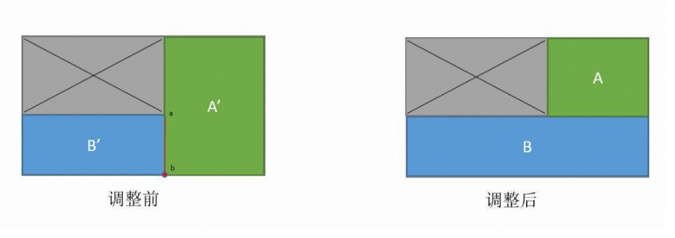
残存空间调整前后对比图
如上图所示调整前,残存空间A’ 和B’共享边(a, b)和顶点b 并在同一水平面上。经过调整后我们获得新的空间A 和B,其中B 能装入之前A’和B’无法装入的狭长型商品。
Spark 并行计算
苏宁全国拥有 47 个仓库,每天有大量包裹需要实时推荐包材,单机版的算法并不能满足业务要求。因此我们使用 Spark Streaming 实现算法并行化。如下图所示,上游系统实时将批次数据写入 Kafka。Spark Streaming 从 Kafka 不同分区实时获取数据生成 RDD 存放在内存中,然后根据包裹号对内存里的 RDD 进行拆分,分发到不同的 Executor (执行器)。在各个单独的 Executor 中,调用实时推荐包材算法对分配到的相应数据进行计算。完成计算后,每个 Executor 将计算结果即推荐结果写入 Kafka 不同分区中。下游系统再从 Kafka 中实时取走推荐结果。
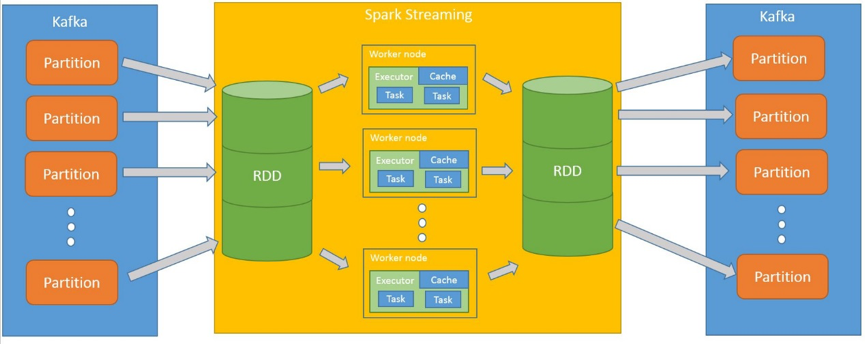
算法并行执行架构图
苏宁智能包装解决方案已经在苏宁仓库运行,通过统一包装耗材标准,将包装耗材种类从 30 种缩减到 14 种,在提高包装效率的基础上包装填充率总体提高 59%。同时,可循环的塑料箱—“漂流箱”已经在北京、上海、广州、南京、深圳、杭州、武汉、成都八大城市上线投入 10000 余个,长约 0.3 米,宽 0.2 米的“漂流箱”,用它代替普通纸箱装载消费者购买的产品,由快递员进行“最后一公里”投递。用户可以在苏宁自提点、社区代收点自提快递,取出商品后将“漂流箱”放回自提点回收。此外,用户还可以选择送货上门,当面拆箱验货签收后,将漂流箱交由快递员带回作循环使用。为了增强用户体验,这些漂流箱还特意设计了牢固的“封箱扣”,保证商品安全,保障用户隐私。苏宁智能包装解决方案的推行,每年可节约 1000 万元的包装成本,同时,“漂流箱”及各种隐私包装的应用,保障客户的购物隐私,增强了客户的购物体验。
作者介绍
叶梦贤,运筹学与定量物流硕士研究生,苏宁物流研发中心算法工程师,主要负责物流优化,运筹学、优化算法在苏宁物流的应用。曾任埃森哲资深分析师,负责与物流相关算法设计与开发。专注于物流优化,运筹学,优化算法研究与应用,希望借助运筹学、优化算法,把握技术变革,助推智慧零售。




