最近的 4 到 5 年以来,微软首次尝试重写在 1998 年发布的 SQL Server 版本 7 所确立的查询执行引擎。重写的目标是在不牺牲关系型数据库特色的前提下,提供类似于 NoSQL 的高速度。
这一次尝试的核心是 Hekaton 项目,即内存优化表。虽然依然能够通过传统的 T-SQL 操作对其进行访问,但其内部已经是基于完全不同的技术所实现。这一技术是有意与当今服务器硬件的三大趋势保持一致的。
内存价格不断下降
早期的 SQL Server 可以通过某些方式将表驻留在内存中,但这一特性后来被证明会造成对性能的损害,随后就被废弃了接近 10 年的时间。在当时来看,将整张表的内容驻留在容量有限的内存系统中是完全不合理的做法。而现如今,64 位处理器已经得到了广泛的应用,而且内存的价格也在不断下降,选择将庞大的数据库保存在内存中就显得更为合理了。

CPU 速度停滞不前
虽然 CPU 的复杂度还在保持上升,但近 10 年来,它的时钟速度的增加几乎已经停滞不前了。因此要看到线性性能的提升,除了利用缓存的能力之外,也要求所运行的代码具有更高的效率。
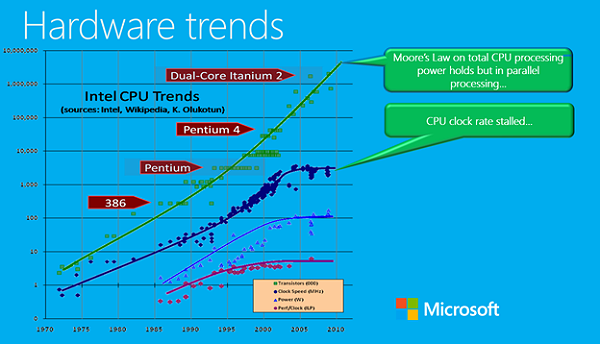
在这里,T-SQL 曾经的设计决策就能够起到作用了。在目前的设计中,无论是即时的查询或是基于存储过程的查询,都仅仅会被编译为一种中间语言,并且之后会通过解释的方式进行执行,而不是通过即时编译的方式转变为机器代码。虽然这种方式能够接受较高的复杂性,但也付出了降低性能的代价。
这一点在过去还是可以接受的,因为虽然数据加载量在增大,但 CPU 处理连续数据量的能力也在随之上升。但这一点在如今已经不可行了,微软已经决定要打造一个新的执行引擎,它的实现依赖于完全经过编译的机器代码。
正如我们在之前的一份报告中所指出的一样,新的执行引擎仅支持存储过程。你付出了放弃动态查询的代码,所得到的是经过高度优化的 C 代码,这些代码是为你所使用的表而专门生成的。
多核处理器
现如今,即使是在智能手机上,也难以找到仅仅是单核的设备了。而在企业级服务器上,48 核或者更多的核也变得常见了。虽然多核处理确实是应对未来需求的正确方式,但还有很重要的一点,即对热表(hot tables)进行优化,让其良好支持并发访问。
这就意味着 SQL Server 需要放弃使用锁(lock)和闩锁(latch)的方式,闩锁通常被认为是一种相对轻量级的操作,但它也会占用 1 至 2 千个 CPU 周期。而锁就更加糟糕,它大概会占用约 1 万个周期。
作为替代,内存表中的数据结构会使用 interlocked 交换锁,它的 CPU 占用会降至仅仅 10 至 20 个周期。当然,这种方式也是有一定代价的,因为缺少锁的支持,对内存表的查询更有可能被取消,并且需要你手动地重试当前操作。
管理与应用程序设计
对于多数 NoSQL 产品来说,最大的成本往往并不在于获取数据库,而在于部署过程。微软希望能够提供一种平缓的迁移过程来逐步迁移至这些替代产品,以此减少总体成本。
迁移至 NoSQL 数据数据库的第一项成本,就是找到那些应该迁移的热表。一些性能分析工具虽然能够指出对哪些表的数据加载量最高,但它无法告诉你将所有这些热表进行迁移的难度有多大。
找到应当迁移的表之后,下一项成本是对现有的应用程序进行重写,以遵守 NoSQL 的编程约定。这一步往往更加令人生畏,因为它往往意味着对底层的数据访问代码进行根本性的重写。
如果使用 SQL Server 的内存优化表,那么多数的改动对应用程序来说都是不可见的。只要表中不包含任何不支持的数据类型,那整个迁移过程可以大量应用自动化。
下一项性能提升是来自于使用完全编译过的存储过程,许多企业级系统依然依赖于存储过程实现大部分甚至是全部的数据访问功能,这些系统的大多数都不会遇到很大的困难。而且,应用程序本身很可能不需要进行任何改动。
微软同时指出,许多倾向于支持多种数据库的独立软件开发商,往往会更依赖于 ORM 框架。因此在迁移时会遇到较多的麻烦,所幸目前多数 ORM 已经开始支持存储过程了,因此随着时间的推移,这些系统也能够慢慢进行迁移。
文件系统的改变
传统的表和索引都是保存在文件页当中的,通过随机访问的方式对它们进行获取和保存。如果数据中出现了碎片,这种方式就可能导致性能问题。为了应对这个问题,许多公司都选择将它们访问量最大的数据保持在昂贵的固态硬盘上。
由于内存优化表并没有使用文件页的结构,因此微软就能够借此机会重新设计数据存储在磁盘上的方式,使所有的 I/O 操作都成为连续的。这样一来,即使是传统的硬盘也有可能实现良好的访问性能。
而能够实现这一点的原因在于,在内存优化表中,记录的数据部分是永远不会被更新的。反之,被更新的这一行的头部会传递一个指针,指向一个新的行,这个新行包含了新的时间戳和更新后的值。
在磁盘上,数据行是组织在一对对文件中的,而这些文件则是按照时间戳范围进行分组的。通常将这一对对文件称为“数据文件”和“差异文件”。在进行插入和更新操作时,新的记录会写入数据文件,而在进行更新和删除操作时,则会将旧行的 ID 写入差异文件中。
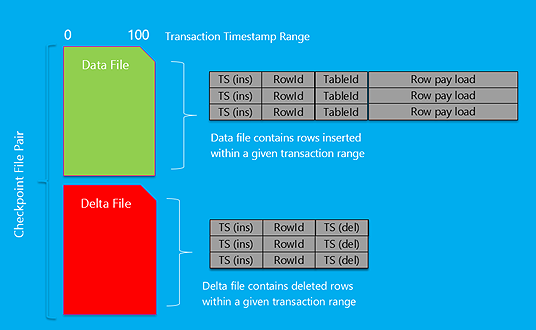
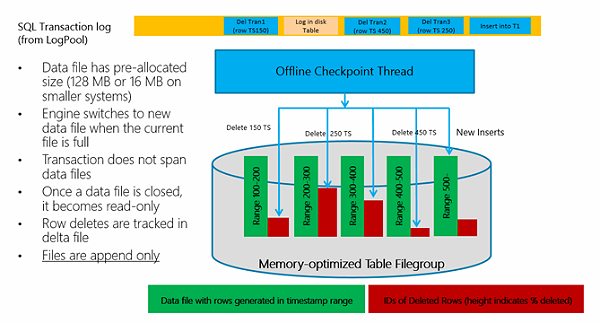
在 SQL Server 重启之后,这些文件对会被同时读取,所有存在于数据文件、但不存在于差异文件的行会被写入内存中。按照这种方式,内存优化表每读取 1GB 的数据大约只花费 1 秒钟左右。
要注意的是,只有在所有的内存优化表都加载之后,SQL Server 才会成为可用的状态。
内存问题
内存优化表有一个很大的限制,那就是它们必须驻留在内存中。在任何情况下,内存优化表都不可能部分或全部写入磁盘的文件页中。那么一旦内存优化表的大小超过了可用内存的最大容量,又会发生什么事呢?
一个简短的回答是:“这很糟糕”,内存优化表会占用通常分配给缓冲池的那部分内存。最终会导致缓冲池没有足够的内存进行正常的运行,而 SQL Server 也会因此变得不稳定。
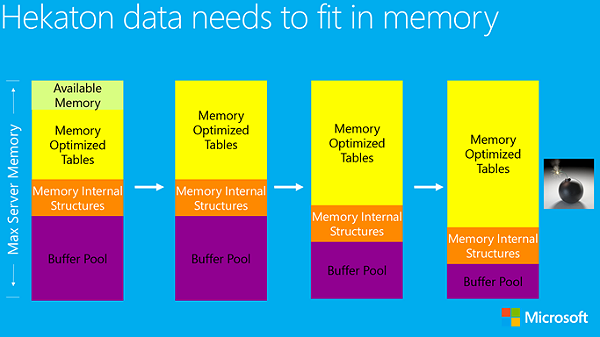
解决此问题的一种临时方案是建立一个资源调节器,对内存优化表能够使用的最大内存进行限制。在每个 SQL Server 实例中只能建立一个这样的资源调节器,而且它所分配的空间对该实例上的所有数据库都是共享的。
对于内存优化表来说,只有大约 80% 左右的内存可用于实际的数据存储,剩下的部分是预留的空间。因此在计算数据最大尺寸时,最好加上个 25% 左右。
未来的计划
内存优化表只是代表了 SQL Server 正在进行的转变的第一步,除此之外还有大量的工作要完成。在第一个版本中的许多限制,例如缺乏外键及检查约束等等,都将在未来的版本中完成。另外在传输层也还有一些工作尚未完成,它还没有利用到内存优化表的布局,以及编译后的存储过程的优点。
关于作者
 Jonathan Allen从 2006 年开始就一直在为 InfoQ 撰写新闻,他现在是.NET 专栏的责任编辑。如果你想为 InfoQ 撰写新闻或者教育性的文章,可以联系他:jonathan@infoq.com。
Jonathan Allen从 2006 年开始就一直在为 InfoQ 撰写新闻,他现在是.NET 专栏的责任编辑。如果你想为 InfoQ 撰写新闻或者教育性的文章,可以联系他:jonathan@infoq.com。
查看英文原文: SQL Server 2014: NoSQL Speeds with Relational Capabilities




