
介绍
今天,大多数 SOA 设计技术 1 , 2 , 3 都是以定义服务为中心的。它们使用面向服务的分解原则,以业务流程为基础、企业业务 / 功能模型,要求的长期架构性目标和现有企业功能的重用。这种方法通常将现代企业最重要的资产之一——企业数据事后整合。本文中我们将重顾一个典型的 SOA 架构,概述处理企业数据的复杂性,并讨论几种将数据整合进入 SOA 实现的设计模式。
典型 SOA 实现
一个典型的 SOA 设计方法导致以一种专用层的形式实现企业服务,这个层次基于“理想的”企业业务模型 3 对现有企业功能(应用)进行了合理化处理。
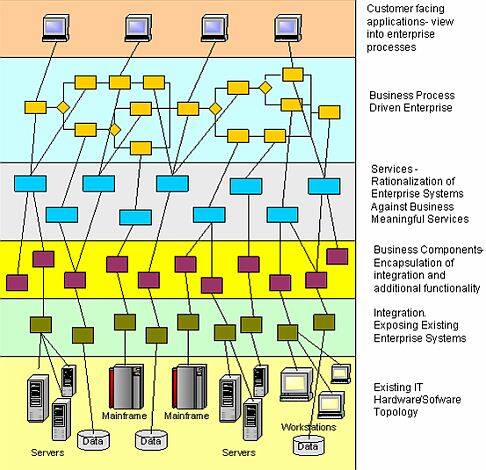
图 1 典型 SOA 实现 这样的架构(图 1)定义了 SOA 架构中的多个层次 4 :
- 企业资源和操作系统层。这一层描述了现有应用系统的业务职责。(即,遗留系统,COTS 和用户自己构建的系统)。
- 集成层。这一层使用不同的技术暴露现有企业资源和操作系统,这样它们就可以被业务组件使用。
- 业务组件层。企业业务组件是可部署的软件单元,它提供业务服务需要的功能。这些组件可以是刚刚被开发出来的,或是使用集成层去访问现有企业资源“包装器”。
- 业务服务层。业务服务提供整个企业的高级业务功能。这一层有效地嫁接了“理想”业务模型和现有企业 IT 资产——应用系统和业务组件。
- 业务流程层。业务流程允许通过编制业务服务来创建业务解决方案。
- 客户体验层。客户体验提供对客户(包括企业内部和外部)的支持,客户可以浏览和控制企业业务流程和 / 或服务的执行。这些客户可以是使用 WEB 或富客户端的人,或者是支持企业内部业务流程的 B2B 连接。
为了加强服务的跨平台的互操作性,这样的架构通常定义语义消息模型——企业范畴的业务对象,它们被服务接口定义使用。这些语义消息模型一般从相同的企业业务模型(被业务定义使用)中派生出来,因而确保所有的服务调用使用一个“通用语言”。结果是,典型的 SOA 实现有效地引入了两种不同的数据模型 5 ——被服务接口暴露的“外部数据”和被服务实现使用的企业数据——“内部数据”。
企业数据存取问题
尽管典型的 SOA 实现在服务接口后面隐藏了企业数据,它仍然需要解决下面的数据存取问题:
- 统一多应用系统间的数据。今天的企业数据一般分散在多个应用“竖井”中。每个应用系统仅仅包含企业数据的一个子集(仅限于应用要解决的问题),这些数据在应用系统之间常常存在重复。这种应用间的数据冗余造成了不准确的企业数据描述,以及应用间需要的定期数据同步,这些应用的每一个都是特殊功能 / 单元的“主”数据存储。此外,数据描述自身也因应用的不同而不同。这导致通常很难去调和单个应用系统的数据描述。随着单个应用的独立发展和进化,问题变得更加复杂。在一个 SOA 实现试图去表述企业范围的功能时,它需要操作基于一个定义良好的企业数据模型去进行操作。这意味来自服务实现企业数据存取,需要正确地调整和统一来自多个现有应用的数据,并且确保将数据变化传播到所有使用这个数据的应用系统中。
- 服务对企业数据的所有权。现代服务定义技术的基础——功能分解不能方便地映射到企业数据上。例如,客户(以及对应的数据)的概念通常被多个功能性服务共享。问题在于功能和数据的分解完全由不同的规则驱动。功能分解是基于企业业务流程——企业功能;然而,数据分解基于企业数据的分类法——企业数据模型的基础。这导致将企业数据向企业服务调整变成一项令人怯步的任务。
- 接口定义。因为服务调用总是远程的,服务设计倾向于大粒度接口,旨在最小化服务消费者和提供者间的服务流量(对话)。另一方面,依照数据存取的需求,需要高和细颗粒度的接口。最后,数据存取一般实现纯的 CRUD(创建、读取、更新、删除) a 功能,作为对企业服务实现业务有意义的接口,比如费率策略等。
SOA 实现整合企业数据的模式
有好几种设计模式旨在使 SOA 实现支持企业数据,其中一些是已经广为认知,另一些则是刚刚兴起。下面我会描述三种最重要的。
使用业务服务协调企业数据支持
这是今天 SOA 实现的主流模式,与所有的 SOA 实现都合作得很好,如前面所示(图 1)。在这个模式里,企业数据存取已经合并到业务服务实现中。数据通过集成层存取,服务实现自身负责定义和支持对特殊数据集的验证、存储、检索规则。这个设计模式的优点是能与所有的服务实现方法合作得很好。这个模式的缺点是:
- 服务实现不得不除了支持服务的业务功能之外,还需要支持所有的数据验证、存取和协调逻辑。这导致业务实现经常和数据存取以及转换的代码纠缠在一起。
- 在多个企业业务服务间共享业务数据需要额外的设计考虑,而且一般导致额外的企业服务间耦合。如果多个服务需要对企业数据的相同部分进行存取,可能使用下面的解决办法:
- 在多个服务间复制数据存取逻辑。这允许每个服务独立存取数据,但是需要在多个服务实现间复制数据存取、转换、同步逻辑。尽管,理论上在有可能在一个单独的组件上封装这些逻辑,以便被多个服务重用,但是实际上几乎不起作用。多个服务实现平台,比如 J2EE VS. .Net VS 主机,需要这些组件的不同实现。此外,因为组件不是独立可部署的,该组件的每次变更都需要将依赖它的所有服务重新部署。
- 扩展一个服务的接口来包含操纵由服务控制的数据的 CRUD 方法。这个方法导致服务方法粒度的下降,抹杀了服务方法的业务意义。它还额外造成了企业服务间多余依赖,破坏了它们自治的本质。
事实上许多 SOA 实现都混合使用了上述两种方法。尽管这种模式一般适合小规模初级的 SOA 实现,但是对于企业级别的实现,它的扩展性不是很好。
将企业数据存取封装为业务服务
克服上一个模式缺点的一种方法就是将企业数据存取当作第一级的业务服务。在这种方式下,业务服务的一种特殊类型——数据服务——封装了所有企业数据存取、同步、验证、转换需要的逻辑。这个模式的优点是:
- 服务功能(业务逻辑)的实现和企业数据支持逻辑的实现在关系上的明确分离。企业数据服务有效地创建了一个抽象层,使业务功能避开数据存取细节。
- 通过将非常稳定的数据存取代码从服务实现中分解出来,获得更佳的实现划分。
- 类似其他业务服务,数据服务的接口通常也基于企业语义模型。通过业务服务大大简化了企业数据的消费。
这个模式的缺点是:
- 因为企业数据大多数来自于企业应用系统,数据服务的实现将一般类似业务服务的实现——它由实现数据存取逻辑的组件和使用集成层来存取存在于现有应用系统的数据的组件一起构建。这使得常常很难区分以功能重用为目的的集成和以企业数据存取为目的的集成。企业数据存取集成,一般不会直接依靠企业数据存储——在数据存取和验证时,它们通常利用已有的遗留实现。这导致通常不容易把一部分实现归为单纯的数据服务或者业务服务。
- 正如我们上面提到的,一个典型的数据服务接口设计是 CRUD,它被认为是服务接口设计的反模式 6 。此外,因为数据服务需要支持一个范围广泛的企业数据存取选项(被业务服务所需求的),它们必须具备高度的灵活性。这些需求通常反映在数据服务接口的低粒度上。
- 通过专门的数据服务集中化所有企业数据的存取要求业务服务的所有数据存取也通过这些数据服务完成。这样的实现导致完全的“聊天式(chatty)”实现,造成在数据服务上业务服务的强依赖性,这会一定程度上破坏服务的自主权。最小化这些依赖的一个方法是创建服务流程(组合服务),它管理基础服务需要的所有企业数据,将所有需要的企业数据当作一个参数集传给业务服务。尽管这个方法改善了业务服务的自主权,它通常导致流程状态和服务消息的“膨胀(bloating)”,对业务流程的伸缩性和服务调用性能有负面影响。
企业数据总线
今天 SOA 实现最流行的方法之一是使用企业服务总线模式 7 ,它允许“虚拟化”企业服务存取 b 。 同样,企业数据总线允许虚拟化企业数据存取。从大多数方面来说,这个模式类似上面描述的企业数据存取服务。与将数据存取提升为第一级的业务服务不同的是,在这个方法中,这个模式作用在集成层上,它提供了任意服务直接访问企业数据任意部分的功能,如图 2。
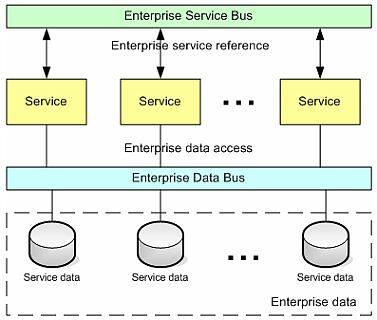
图 2 企业数据总线 企业数据总线的起源可以追溯到数据库联邦技术——虚拟化存取企业中的异种数据库。不幸的是,这个技术对于 SOA 实现几乎不具有可应用性。这儿的问题是现有应用通过实现数据存取和验证逻辑有效控制了企业数据的访问。绕过这些应用系统直接访问数据库,需要重新实现这些逻辑,一般说来这很不划算。结果是,数据总线一般由集成层(图 1)实现。市场上的新产品,例如 IBM Information Server 8 就支持直接数据库存取和集成两种方法。这种产品通过“搭配”集成解决方案和直接数据库存取 c ,扩展了企业数据总线实现的灵活性。有效地实现这种模式,需要将提供企业数据存取的集成和提供企业功能能力的集成进行分离。考虑到数据和功能集成两者都获取 / 返回企业数据 d ,最直接的方法是考虑所有的集成都作为数据存取集成 e 。这导致 SOA 实现的全面修改。(图 3)
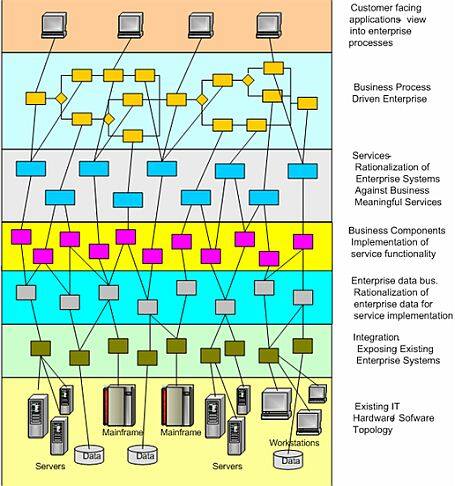 图 3 有数据总线的典型 SOA 实现 这种实现(图 3)增加了额外的一层——企业数据总线,它提供对包含于企业应用或是应用下属数据库中的企业数据的存取。这也修改了企业组件层的实现;在这种实现中它不再包含“包装器”组件。这种情况下,业务组件将仅仅由基于现有功能实现的服务功能组件和使用企业数据总线的数据存取组件组成。这种模式的优点是:
图 3 有数据总线的典型 SOA 实现 这种实现(图 3)增加了额外的一层——企业数据总线,它提供对包含于企业应用或是应用下属数据库中的企业数据的存取。这也修改了企业组件层的实现;在这种实现中它不再包含“包装器”组件。这种情况下,业务组件将仅仅由基于现有功能实现的服务功能组件和使用企业数据总线的数据存取组件组成。这种模式的优点是:
- 服务功能(业务逻辑)和企业数据支持逻辑的实现在关系上的明确分离(和上一个模式相似)。企业数据总线有效的创建了抽象层,使业务功能避开企业数据 / 功能存取的细节。
- 通过封装对企业数据 / 功能的所有访问,企业数据总线给所有的企业语义数据模型和企业应用系统的数据模型间的转换提供了一个单一位置。
- 这种情况下,因为任何服务实现能访问它需要的任意企业数据,这样的实现允许显著地减少服务间的耦合——服务调用仅仅包含极少变化的数据引用(键),而实际的数据存取由使用企业数据总线的服务自身来实现。这意味着如果服务实现需要用于它的流程的额外数据,它可以在不影响它的消费者的情况下直接存取到数据。
这种模式的缺点是:
- 由于大量的存取(同步),性能成为企业数据总线最重要的指标之一。总线上任何的一个性能下降,都会大大破坏 SOA 实现。
结论
随着 SOA 实现的范围从局部部门级实现扩展到企业范围,企业数据存取迅速成为最重要的实现问题之一。 如果每次一开始都不能正确的架构,企业数据存取将成为一个主要拦路虎。本文中展示的设计模式定义了在 SOA 环境中处理企业数据的不同方法,以及每个方法优缺点。
关于作者
Boris Lublinsky 在软件工程和技术架构上有超过 25 年经验。近些年来,他关注于企业架构、SOA 和流程管理。在他的整个职业生涯中,Lublinsky 博士都是一个积极的技术演说者和作者。他在不同的期刊上发表了超过 40 篇技术文章,包括 Avtomatika i telemechanica, IEEE Transactions on Automatic Control, Distributed Computing, Nuclear Instruments and Methods, Java Developer’s Journal, XML Journal, Web Services Journal, JavaPro Journal, Enterprise Architect Journal and EAI Journal。现在 Lublinsky 博士为大型保险公司工作,他负责开发和维护 SOA 策略和框架。可以通过 blublinsky@hotmail.com 联系他。
参考文献:
活动推荐:
2023年9月3-5日,「QCon全球软件开发大会·北京站」 将在北京•富力万丽酒店举办。此次大会以「启航·AIGC软件工程变革」为主题,策划了大前端融合提效、大模型应用落地、面向 AI 的存储、AIGC 浪潮下的研发效能提升、LLMOps、异构算力、微服务架构治理、业务安全技术、构建未来软件的编程语言、FinOps 等近30个精彩专题。咨询购票可联系票务经理 18514549229(微信同手机号)。

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论