
去年 9 月,微软宣布获得了 OpenAI 的 GPT-3 语言模型的独家授权。而在近日举办的 Build 2021 开发者大会上,微软正式公布了收购之后的第一个商业用例:在 Microsoft Power Apps 中集成 GPT-3 的能力,可将自然语言直接转换为现成代码。
虽然目前这项功能使用范围有限,只支持在微软 Power Fx 中生成公式(Power Fx 是一种由微软 Excel 公式衍生而来的低代码编程语言),但却已经显示出机器学习作为代码自动生成工具、帮助新手程序员快速投入生产的巨大潜力。
微软公司低代码应用平台集团副总裁查尔斯·拉玛纳(Charles Lamanna)在采访中表示,“目前市场对于数字解决方案的需求量很大,但程序员数量却无法及时跟上。因此,除了在世界范围内推广编程学习之外,我们为什么不直接在开发环境里说大白话呢?”
开发门槛大幅降低
GPT-3 是全球最大的自然语言模型。据微软官方介绍,在 GPT-3 的驱动下,现在 Power Fx 可以让任何人完全不借助任何编程知识,仅仅用自然语言就能完成应用程序的搭建。Power Fx 的这项升级带来了 AI 辅助的完全直觉式的编程体验,让开发者或者其他任何人都能更快速地开发应用。
介绍很华丽,实际使用如何呢?举个例子,用户想实现一个“找到所有订阅过期的美国用户”的指令,只需要把需求以正常的语言表达输入进去,就可以直接翻译成 Power Fx 的代码语句,比如像下面图片显示的一样。

输入自然语言。截图源自演示视频

自然语言被翻译成相应的代码
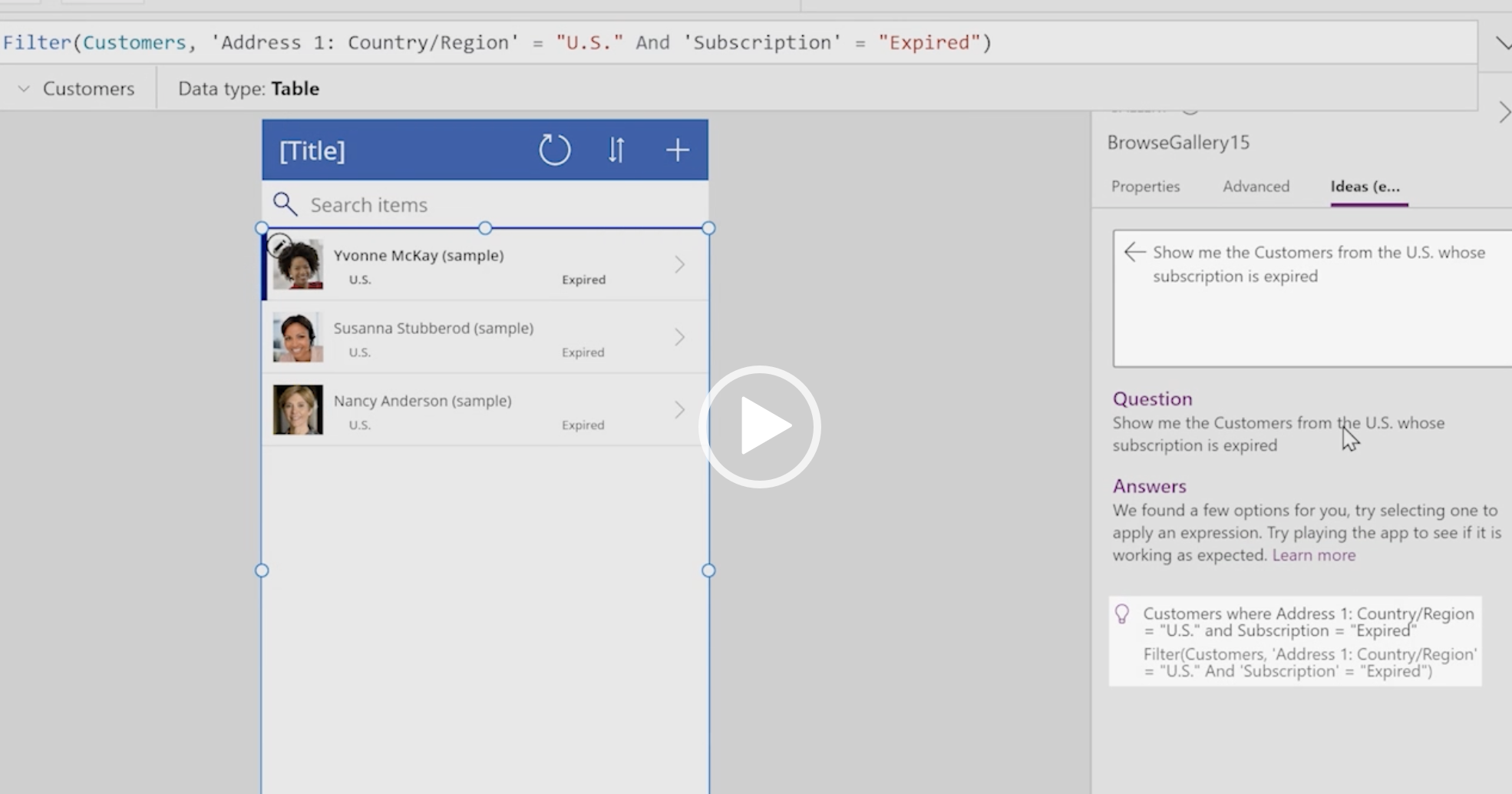
执行所选的代码
拉玛纳表示,“整个时代正朝着低代码乃至无代码迈进。拖放、单击、单击、再单击,就能编写出有效的公式。但如果复杂度再高,用户就很难快速适应了,这时候就需要由机器学习伸出援手。”
微软并不打算让用户额外学习如何在 Power Fx 中执行数据库查询,反而更新了 PowerApps,帮助他们使用简单的自然语言编写出查询,而后由 GPT-3 将其翻译为可用代码。如此一来,如果用户希望通过“FirstN(Sort(Search(‘BC Orders’, “Super_Fizzy”, “aib_productname”), ‘Purchase Date’, Descending), 10),”搜索数据库,他们完全可以直接写下“在产品名称中,显示出 10 个包含 Super Fizzy 的订单,并按购买日期由晚到早排序”,之后 GPT-3 就能生成正确的代码。
“我记得我们在周五晚上拿到了第一套原型方案。用过之后,我有种毛骨悚然的感觉。这么多年以来,技术产品从来没给过我这样的感觉。”对于新的升级,拉玛纳如此感慨道。
微软并不是在这方面做出尝试的第一人。近年来,市场上已经出现众多 AI 辅助开发相关程序,包括 Deep TabNine 等也在使用 GPT 系列模型提供支持。但由于可靠性较差,这些程序并没能得到广泛应用。
众所周知,编程语言多变复杂,极微小的错误也有可能令整个系统陷入崩溃。此外,AI 语言模型的输出往往比较随意,可能将单词跟短语搞混,不同句子之间相互矛盾更是司空见惯。结果就是,常常需要经验丰富的程序员去人工检查 AI 自动生成的输出结果。这自然会影响到新手们使用此类工具的意愿。在这种情况下,Power Fx 的简单性反而成了最大优势。
Power Fx 语言非常简单,它源自微软 Excel 公式,而且在功能方面也有较大的限制。“Power Fx 只是数据绑定的单行表达式,没有构建与编译等概念。用户编写的内容可以立即计算得出。”拉玛纳说道。
换句话说,它虽然没有 Python 或 JavaScript 这类成熟编程语言的强大功能或灵活性,但同时也回避了 AI 生成代码可能遭遇的大部分错误空间。作为一项附加保护措施,Power Apps 界面会要求用户确认由 AI 生成的 Power Fx 公式。
并非毫无风险
新功能将从今年 6 月起开放预览,它大大展现出了微软探索“低代码、无代码”的野心。但作为 GPT-3 的主要商业用例,这也只是当代 AI 领域中占主导地位的 AI 语言模型的其中一个实际应用。这些系统功能强大,几乎能够生成我们所能想象的任何文本类型,并通过多种方式操纵语言。与此同时,不少其他大型科技企业也正在探索其中蕴藏的无限可能性。谷歌已经将自己的语言 AI 模型 BERT 集成到搜索产品当中,而 Facebook 也将类似的系统引入到机器翻译等场景之下。
但这些模型也有自己的问题。其核心往往来自研究人员从网络上爬取到的大量文本数据中的语言模式。就像微软的聊天机器人 Tay 会很快学会 Twitter 用户发布的侮辱性言论一样,这类模型也很可能在编码当中重现各种形式的性别歧视与种族主义表达。由此生成的输出,也可能带来意料之外的负面影响。例如,某个基于 GPT-3 的实验性聊天机器人本应发布医疗建议,却规劝模拟病患最好自行了断。
拉玛纳强调,对于微软来说,使用 GPT-3 创建代码的风险虽小,但也仍然存在。该公司已经对 GPT-3 进行了微调,希望通过 Power Fx 公式示例进行训练以掌握代码转换的能力。但从根本上讲,这款程序的核心仍然基于从网络上学习到的语言模式,这意味着其中或多或少残留着某些负面元素与偏见。
拉玛纳举了使用该程序查找“所有优秀求职者”的示例。程序会怎么理解这条命令?GPT-3 可以发明新的标准来回答问题,也有可能自行假设“好”跟“白人”是一回事,毕竟网上的不少言论就是这么暗示的。
微软公司表示将通过多种方式解决这类问题。首先就是设定系统不会响应的违禁单词及短语列表。拉玛纳强调,“我们不会推出任何可能输出有毒言论的 AI 系统。”而如果这套系统生成了其自认为有问题的内容,还会提醒用户将结果上报给技术支持团队。之后,会有员工介入并努力解决问题。
但拉玛纳也指出,要想在程序安全与功能灵活性之间求得平衡性显然非常困难。按种族、宗教或性别进行筛选既可能代表歧视,也有可能对应某些合法应用。微软似乎在努力找到这两类应用场景的区别。
The Verge 认为,尽管这款程序还面临着种种未能解决的问题,但这只是微软大规模试验的第一步。不难想象,将类似功能集成至微软 Excel 中之后,相关服务将覆盖全球数亿用户、极大扩展其可访问性乃至社会影响力。
不过拉玛纳否认了这种大规模应用的可能性,表示这不是他的职责所在,但他坦言新项目可以在任何能够支持 Power Fx 的场景下实现 GPT-3 辅助编码,而且 Power Fx 广泛存在于微软产品的各个层面。因此,相信用户在未来使用微软产品时,会越来越多地享受到 AI 代码生成带来的便利与收益。
参考链接:




