
大家好,我是来自明略数据的邵蓥侠。今天我跟大家分享的主题是基于 RDF 的知识图谱管理。本次分享主要包括三部分内容,分别是 RDF 的基础概念、RDF 的查询技术和 RDF 的存储技术。
RDF 的基础概念
在具体介绍 RDF 相关的内容之间,我们先简单介绍下知识图谱与 RDF 之间的关系。从 2010 年 Google 利用知识图谱优化了其搜索服务以来,知识图谱得到了迅速发展。无论是工业界还是学术界,都出现了各种各样的知识库。

上图展示了多个典型的代表,例如 Yago,freebase,DBpedia,musicBrainz,pubMend 等。这些知识图谱为各类智能应用带来了大量结构化知识,像 Google 的 knowledge graph 包含 700 亿个事实 (facts)。
为了灵活共享上述知识图谱,使其具有一定的可读性,同时保证机器也能够方便理解知识,事实上,大部分的开放的知识图谱,都是以 RDF 形式对外开放。

以 DBpedia 为例,其官方文档里有这么一段话,“DBpedia 以 RDF 作为一个灵活的数据模型用来表示抽取的信息,并发布到网上”。下图展示了 DBPedia 知识库中以 RDF 表示的知识样例。
RDF 全称为 Resource Description Framework,即资源描述框架。它最初是在语义网背景下设计出来,以三元组形式描述资源的一种数据模型。简单地,可以把 RDF 数据模型与关系数据库中的 Entity-Relationship 模型,或者面向对象语言中的类图等概念进行类比,都是对数据的一种抽象描述。
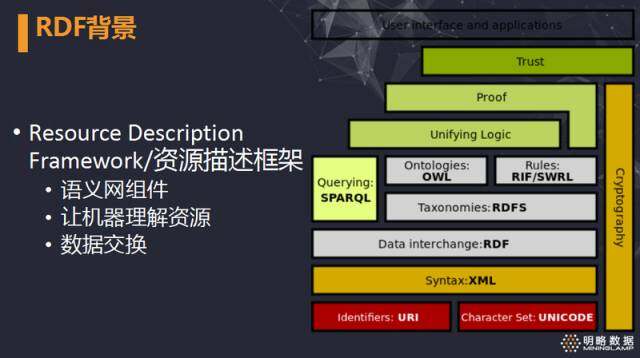
右图描绘出了 RDF 在整个语义网络技术栈中所处的位置,从中可以看出,RDF 主要负责数据交换,并通过 RDFS 能让机器理解网络中的数据真正的含义,而不仅仅是简单的字符串。
接下来介绍 RDF 相关的基础概念,也包括什么是 RDF,RDF 的结构和基于 RDF 的知识表示等三部分。
什么是 RDF?
首先,从 RDF 的命名我们可以清楚的理解 RDF 的内涵。
- R 代表 Resource,即资源,任何可以被唯一标识的对象,都可以称为资源。例如,网页、地点、人、事件、餐馆等;
- D 代表 Description,也就是说对资源的描述,包括资源属性的描述和资源间关系的描述;
- F 则是指 Framework,即 RDF 为资源描述提供了描述的语言和模型。
举个具体的例子,为了让机器知道“哈利波特的作者是 JK 罗琳”这个事实,RDF 则提供了一套语言和模型来描述哈利波特是一本书,JK 罗琳是一个人,两种之间是被创作关系等。综上,RDF 就是一套为描述资源属性和关系提供语法和模型的框架。

RDF 结构
RDF 为描述资源提供的基本元素有 IRI,字面值和空节点 (blank node)。IRI 就是一个符合特定语法的 UINICODE 字符串,如
http://www.w3.org/1999/02/22-rdf-syntax-ns#HTML ,
跟 URL 的形式比较类似。其实 URL 属于 IRI 的一种。
字面值可以理解为像时间、人名、数字等常量的表示,由字符串和表示数据类型的 IRI 构成。例如数字 1 的字面值可以表示为"1"^^xs:integer,其中 xs:integer 是表示整型数据类型的 IRI。
空节点是指没有 IRI 的匿名节点。一般是 RDF 内部使用的一个特殊结构,不可被引用。

RDF 中对资源的一个描述称为陈述 (statement),一般用 Subject-Predicate-Object(SPO) 三元组 (triple) 表示。
其中,subject 的取值可以为 IRI,blank node; predicate 取值为 IRI,object 的取值则是 IRI,blank node 和 predicate。
例如,“a person named Eric Miller”在 RDF 中基本形式为 (xs1:me, xs2:fullName, “Eric Miller”)。

一个 RDF 数据集由一组相关的三元组的组成。由于这个三元组集合可以抽象为一张 graph,因此也称为 RDF graph。
右图展示了一个简单的 RDF graph,记录了一个名叫 Bob 的人的出生年月、他的朋友和他喜欢的名画信息。对应的 RDF 三元组位于下方。

之前我们也看到了一些三元组的各种表示形式,下面具体介绍 RDF 几种重要的序列化表示形式,这些形式一来可以用于数据交换,二来也保证了可读性。
首先介绍 RDF 基于 XML 的表述语法,RDF/XML 语法是目前唯一个符合 W3C 标准的语法。
右图是一个简单的例子。为了避免数据中频繁出现冗余的字符串,一般可以定义一个简写的前缀表示形式,如这里的 xmlns:cd 表示 http://www.recshop.fake/cd#。
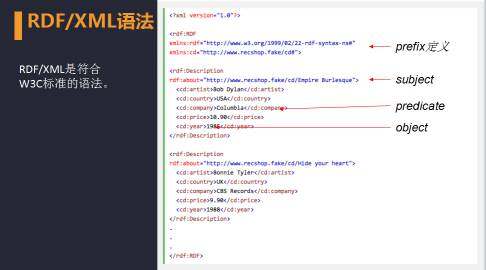
接下来每一个资源对应一个 < rdf:Description > 标签,其中 rdf:about 给出了该资源的 IRI,也是三元组中的 subject。
< rdf:Description > 标签里的其他子标签分别对应着 predicate 和 object. XML 形式紧凑,从图模型的角度分析,它是以顶点为基本单元进行 RDF graph 的描述。
另一种,流行且更常用的格式是 turtle 格式,它是 RDF 1.1 中的标准语法。Turtle 中直接以三元组形式进行表示,三元组中的 subject,predicate,object 之间用空格隔开,用”.”表示一个三元组的结束。

但是,为了对于同一个 subject 的三元组进行简化表示,允许 subject 的省略,同时三元组的结尾用”;”表示省略的 subject 同上一个三元组。
上一页中以 XML 表示的例子可以简化为如右图所示的 turtle 形式。相比与 XML 语法,省略了大量标签语言,使得文件内容更加简洁。
另外,还有两种表示形式,分别是 N-Triples 和 N-Quads。N-Triples 是 Turtle 的简化版,去掉了 Turtle 中的高级语法,一行就是一个 triple,没有简写的格式。因此,能够处理的 Turtle 的 parser 同样能够接受 N-Triples 的数据格式。
而 N-Quads 则是在三元组的基础上增加了一个维度,成为四元组。新增加的维度表示 graph name,即元组所属的 RDF graph 的名称,这就能够进一步区分 SPO,有利于进行数据融合和管理。

RDF 知识库构建
有了上述不同表示形式,那么接下来就是如何将文本数据或者是现实世界中的知识表示成 RDF 数据。这就需要 RDF 字典,即一般所说的数据的 schema。

例如,用 RDF 描述一本书,RDF 字典就需要定义一本书需要包含作者、书名、页数、出版时间、语言类型等。RDF 字典定义了数据建模的元数据项,这些元数据项主要包括两种类型 class 和 property。
Class 是指对象实例的集合,可以理解为面向对象编程里的 class;Property 还分为两种子类型:一个是表示 class 的属性 (attribute),另一个是表示多个 class 之间的关系 (relationship)。
另外,RDF 字典的定义自身也是一个 RDF graph。这也是说明 RDF 是自描述的数据模型,是一种 schema-free 的数据模型。
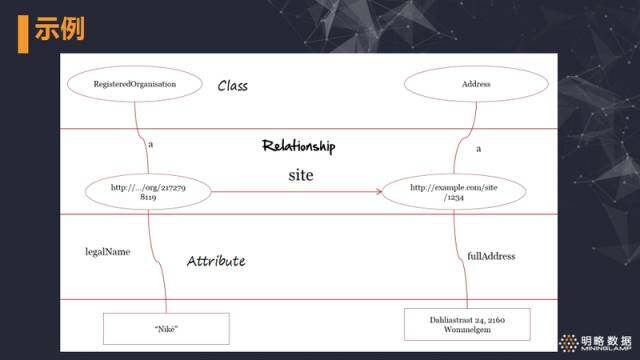
这张图清楚的展示了 class,attribute 和 relationship 三者之间的关系。第一层中的元素是 class,如 RegisteredOrganisation 和 Addrees;第二层则是 class 对应的实例,而实例之间的 site property 即为 relationship,地址实例 http://example.com/site/1234 的 fullAddress property 则是属性 (attribute) 类的 property. 简单的理解,一般情况下 attribute 类型的 property 的 object 是字面值;而 relationship 类型的 property 的 object 也是一个 IRI。
有了完整的 schema,用户可以方便的将现实中的知识映射成 RDF graph. 通过复用 RDF schema 有利于数据的开放共享,同时避免重复劳动。目前为止已经有许多定义好的 RDF 字典,不过英文的居多,例如 FOAF,schema.org 等。这个 http://lov.okfn.org/ 网站专门汇总了互联网上公开的 RDF 字典。

从去年开始,国内也开始关注这块内容的标准化,出现了 cnschema。Cnschema 主要针对 schema.org 进行翻译,同时结合中文特点进行定制和扩充,形成可复用的符合中文事实的知识图谱的数据字典。 通过复用 RDF 字典可以大大降低知识图谱构建的成本,同时也有利于形成数据的标准化。
当然,在现有的 RDF 字典无法满足我们的实际需求的时候,可以结合 RDF schema 和 OWL 两种语言进行字典的自定义。下图给出了一个样例,我们自定义了一个 PublicService 类。

RDF 的查询技术
目前,我们简单地介绍了 RDF 的基本概念、表示方法以及构建思路。接下来将介绍如何对构建好的 RDF 进行查询。本部分主要介绍 SPARQL 语言以及一些用户友好的查询思路,比如使用自然语言查询。
SPARQL 是针对 RDF 数据进行结构化查询的语言,类似于关系数据模型上的 SQL 语句,不同的是 SPARQL 查询中以 Triple Pattern 为基础构造查询条件,而不是针对行列的限制。自 2008 年 1 月起,SPARQL 也成为了 W3C 的标准。SPARQL 的提出一定程度上简化了 RDF 数据的访问,也为 RDF 的管理提供了一个统一的入口。

SPARQL 中查询类语句主要包括四种,分别是 SELECT,DESCRIBE,CONSTRUCT,AKS。

- SELECT 是从 RDF 中选择出满足条件的资源或者属性;
- CONSTRUCT 则是根据条件获取满足条件的 Triple 并以此生成一个新的 RDF 数据集;
- DESCRIBE 则是获取用户输入的资源的所有属性描述;
- ASK 则是 SELECT 的优化版本,它只检查是否存在满足条件的资源或者属性,但不需要全部找出。
另外,在构造查询的条件时,类似 SQL,可以使用常见的关键词对操作进行限制,比如 FILTER,OPTIONAL,LIMIT,ORDER BY 等。
这里我们展示了 SPARQL 查询的一个样例,“找出所有实体的 legalName”。

首先,与 RDF 序列化格式类似,为了简化书写,我们可以定义 IRI 的前缀,然后再书写具体的查询语句。
SPARQL 中查询的变量用“?< 字符串 >”的形式表示。
SELECT 关键词表示语句类型,其后跟着的事具体需要查询的变量,
WHERE 语句中则是具体的查询条件。
在 SPARQL 中,查询条件由 Triple pattern 定义。Triple Pattern 的书写格式类似 RDF 的 N-Triple 的格式,把未知的 SPO 用变量替代,其他元素即为 IRI,字面值和空节点。
接下来,我们来看看 SPARQL 查询的逻辑模型。

由前面关于 RDF 的介绍可以知道,RDF 数据集是一个 RDF Graph,即一个带标签的有向图。
WHERE 条件语句中的 Triple pattern 也对应了一个含有变量信息的 RDF graph,那么 SPARQL 查询问题就转化为了一个图模式匹配问题。
这里展示了一个具体的例子。左图是用 SPARQL 语句表示的“查询 card:i 认识的人的主页”,右图则是对应的一个模式图。
图模式匹配的算法根据不同的数据物理存储模型,具体的解决思路有两种。第一种是以图模型为基础的执行,就直接利用图操作解决图模式匹配问题;第二种则是以关系代数为基础的执行,利用 join 操作解决图模式匹配问题。具体的 RDF 存储思路再后续章节中介绍。

下面我们再来看看 SPARQL 的一些不足。

虽然 SPARQL 提供了一种结构化的查询接口,看似能够像 SQL 语句一样简洁,为 RDF 数据的管理带来真正灵活方便的接口。
然而,现实是残酷的。由于 RDF 是一种 schema-free 的数据组织方式,一个公开的 RDF 数据集涉及的数据字典往往规模庞大,命名复杂。
例如,Freebase 中就包含至少 7000 种关系。这直接提升了 SPARQL 的书写难度,是因为 SPARQL 在执行过程中,需要精确匹配这些字典和 IRI。
这里也有个例子,“查询 Godfather 这部电影的导演的其他作品”,左图是用户习惯书写的格式,而右图是在 dbpedia 上系统能够正确识别的查询。
两者虽然结构相似,但是使用的 IRI 的表述十分不同。实际要熟练快速的编写 SPARQL 语句,不仅要了解其语法,而且要对处理的 RDF 中使用的数据字典足够清楚。
为了解决这个问题,提升 SPARQL 的易用性,现在有不少研究工作期望提出用户友好的查询。让用户以更加简洁清晰的方式表达查询,系统自动的将其转化为标准的 SPARQL。这里举三个例子。

第一个是类 SPARQL 的查询。类似上一页 PPT 中图片所示,用户以 SPARQL 形式书写一个使用非标准数据字典的查询,系统通过匹配模型,自动的将相关表述映射到标准的数据字典上,这就避免了记忆大量数据字典的难题。
第二个工作则是基于 Example 的查询。很多时候,当查询 RDF 的知识图谱时,用户已经拥有几个预期的答案,想找到更加完整的答案集合。基于 Example 的查询则是通过收集用户预期的答案和不断的迭代最终推测出用户真正的查询,从而把其他满足条件的结果返回给用户。
第三个则是基于知识图谱问答系统常用的交互接口之一,即用户直接以自然语言形式输入查询条件,系统通过自然语言理解技术将非结构化的查询转化为 SPARQL 查询。上述三个工作都是对现有 RDF 查询技术的探索,期望能够找到更加用户友好的方式去使用 RDF 数据。
RDF 的存储技术
最后跟大家分享下,为了保证 RDF 的查询效率,如何设计相关的存储方案。

RDF 的存储方案主要有两大类:其一是基于 RDBMS 的存储方案,典型的系统有 Bhyper,Graphium RDF;另一个则是原生 (native) 的存储方案,根据 RDF 的数据访问特点而专门设计的存储方法。
第二类方案进一步可以分为以图数据模型为基础的存储方案和自定义数据存储格式的方案。前者的代表系统有 Trinity.RDF,Virtuoso.RDF;后者有 RDF3x,Hexastore,Jena TDB。

经典的基于 RDBMS 的存储方案其发展过程可以分为两个阶段:在早期,人们把 RDF 中的 Triples 当做一张完整的只有 SPO 三列的大关系表,并直接存储于像 MySQL,Postgresql 等 RDBMS 系统。

此法的优点是元组数据更新快,数据库 schema 简单,但不足是无法高效支持 join 操作,使得复杂的查询性能不佳。
后来,有研究人员将 RDF 中的 Triple 根据其 Predicate 值分类,将 predicate 一样的数据存储于同一个关系表,称为属性表。
此设计方案,在给定 predicate 值时,查询 subject 和 object 十分高效,但是数据库的 Schema 难以维护,数据库表的数目与 predicate 的种类成线性增长。

2008 年,Weiss 在前人的基础上,对上述方法进一步优化,主要是通过建立索引的方式来加速不同查询的效率。
作者根据 RDF 三元组的限制,对 SPO 的排列组合进行枚举,建立了 6 个索引,同时为每个索引中存储部分元组的统计信息加速查找。
此法的优点是 6 个不同的索引使得不同的查询模式可以选在不同的查询策略进行优化,缺点是直接利用 RDBMS 中的索引机制失去了针对 RDF 数据访问特性的细粒度优化的机会。

针对这些问题,Weikum 在 08 年提出了基于原生的数据存储格式的 RDF 管理系统,RDF3x。
作者根据 RISC 架构的设计思想,重新设计 RDF 管理系统,并开发了多个针对 RDF 的优化技巧,使得 RDF3x 成为当时单机性能最好的 RDF 管理系统。
RDF3x 沿用了传统数据库的查询优化思路,对用户的查询先通过优化器找到一个合适的执行计划,具体的 join 的顺序,然后再执行查询获得结果。
另外,RDF3x 采用了精心设计的多种索引结构来减少外存的 IO 操作,提升查询性能。

首先,RDF3x 将 RDF 中的一个 Triple 视为基础元素,把它作为一行数据进行存储。
其次,为了降低存储空间,提高访问效率,将 RDF 中的字符串统一映射为数字 ID,形成字典表。
最后,设计了 15 个压缩的聚集 B±tree 索引。其中,6 个 SPO 排列组合的索引,支持完整的三元组的查找;6 个 2 维度的索引,支持部分元组信息和统计信息的快速查找,以及 3 个 1 维度的索引。Triple 在索引中以字典序进行管理,利用 merged join 可以进一步减少 IO 操作。
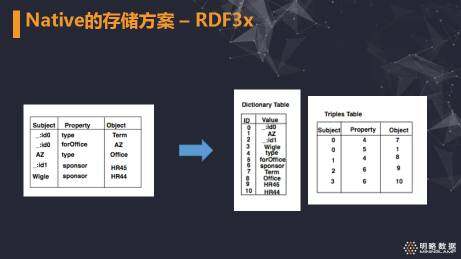
此图展示了 RDF3x 中对三元组的存储样例。一个原始的 RDF 数据集转化了一张字典表和一个 Triple 表。
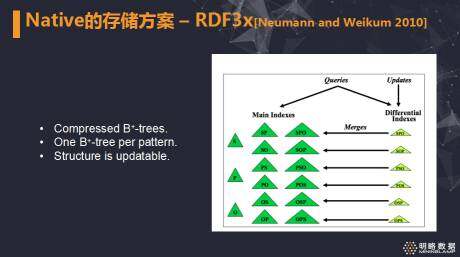
此图展示了 RDF3x 中的 15 个索引 (左侧绿色的三角形)。每一个都是对一个特定模型的进行索引的压缩的 B+ 树。另外,为了实现数据集的更新,利用差分的方式对索引进行更新。
最后,介绍一个以图模型为基础的进行管理的分布式 RDF 存储系统,Trinity.RDF。
此系统是 MSRA 基于其内部的图数据库 Trinity 开发的一个分布式 RDF 存储引擎。
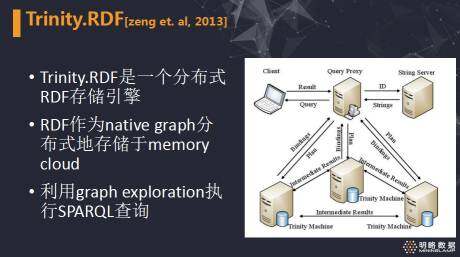
它把 RDF 作为带标签的有向图利用图划分技术分布式地存储于内存云中,具体的管理方式可以参考 Trinity 的技术文档。
在执行 SPARQL 查询,为了避免 join 操作,利用图的节点扩展的操作进行图模式匹配。
本系统主要通过减少中间结果规模及降低通信量来保证系统的查询效率。
右图展示了该系统中具体的分布式查询流程,当用户提交查询时,首先通过 String 服务器,将查询涉及的 IRI 映射为数字 ID,然后结合 RDF 的划分情况,利用代价模型,对 SPARQL 中的查询模式图进行合理切分,生成分布式的执行计划,交给 Trinity 的 worker 进行分布式的查询。

本次分享主要介绍了 RDF 在管理知识图谱方面的基本概念和技术。RDF 是目前开发知识图谱的常用序列化形式;SPARQL 作为 RDF 的标准查询语言,对于用户而言仍然不够十分友好,需要探索更加简洁方便的查询方式;针对 RDF 的存储,基本思路有基于 RDBMS 和基于 native 等两种存储方案。每一种方式都有各自的优缺点,需要根据实际情况进行选择。
问答环节
想问一下邵老师,现在开源的 RDF 存储数据库和 SPARQL 查询引擎都有哪些?有什么可以推荐的吗?
答:开源的单机 RDF 数据库推荐使用 Virtuoso.RDF 和 Jena,分布式的话,推荐北大 zou lei 老师团队开发的分布式 RDF 存储系统。
感谢分享,使用自然语言进行友好查询的优化方法同样适用于 neo4j 吗?
答:同样适用于 neo4j,但是 neo4j 的 cypher 查询语言没有 SPARQL 那么标准。对于自然语言转化出来的结构化信息到 cypher 的转换的方法需要重新设计。NLU 这块的工作是相同的。
RDF 现在存储的数据库通过今天的讲座听来是比较有限的,除了刚提到的还有其他的数据库么?
答:RDF 数据库其实很多,但是多数确实是学术界的产物。公开的成熟的不像 RDBMS 那么多。目前推荐尝试使用的是 virtuoso。
索引的问题,索引占据的空间是原数据的数倍,索引的查询有没有可能使用 ElasticSearch 而不是自己搭建 native 的系统?
答:RDF3x 从研究成果来看,通过压缩以后,索引空间与实际数据相当。使用 ES 肯定是一种方式,现在有集群资源的情况下,通过优化 ES 也可以获得不错的查询性能。
RDF 的数据库系统的数据灌入感觉是一个巨大的工程,这方面有什么解决方案没?
答: 数据灌入确实是个问题,目前我了解的并没有特别好的通用的方法。
明略采用 RDF 的 entity 和 edge 的数量级是多少?有一些问题:为什么不考虑类似 neo4j,OrientDB,Titan 这类的图库,而要采用 SparQL,是因为数据量很大?
答:为了更好的支持智能化应用,在明略关于 RDF 的存储管理是处于探索阶段。目前我们实际的 SCOPA 系统是采用了自研的蜂巢知识图谱数据库,并对外提供的是 native 的 API。
感觉 rdf 存储不如图数据库,那么用 rdf 的理由是因为通用,为了能更好的做进一步的处理与挖掘么?
答:对于行业领域,在没有复用数据字典的情况下,要取开发一个全新的 rdf 数据集确实代价比较高。采用 rdf 的好处是开放共享,有标准的访问接口,进而能够支持像推理和挖掘分析这样的应用。
中文的非结构化 Web 数据抽取成知识图谱相比于英语,达到同样的质量水平,是否需要更加复杂的算法设计或更大量级的数据 ?
答:结合我个人的实践体验来说,关键在于积累。中文 NLP 的积累比英文弱很多,从开源的组件和数据集就可以发现。开源的中文 RDF 数据几乎为 0,那就很难有复用或者扩充的机会。像英文的知识图谱也不是从 0 开始,RDF 中的 RDF Schema 是基于 OWL 扩充,同时开源的 RDF 数据集,如 dbpedia,在抽取的时候都会依赖 wordnet 这样的 ontology. 我个人的观点还是,积累上,导致现在想做一个不错的知识图谱成本太高。
“对于自然语言转化出来的结构化信息到 cypher 的转换的方法需要重新设计”,这个能举个例子?或者再详细解释一下?
答:这个我想表达的意思是虽然 NLU 的输出是一样的,但是转化为 cpyher 和 SPARQL,是两种不同的形式。因此在转化过程中,需要根据具体的语言表达特性进行特定的转化。目前,我个人是没看到比较好的通用的转化方法。
作者介绍
邵蓥侠,明略数据 SCOPA 技术顾问。北京大学博士后,主要研究方向包括大规模图计算优化、图挖掘应用以及复杂网络分析等,并在相关领域发表学术论文 10 余篇,包括 SIGMOD,VLDB,TKDE 等国际一流学术会议和期刊。曾获 2014 年 Google 博士奖学金、微软学者等称号。目前作为明略数据 SCOPA 技术顾问,主要参与图挖掘、图分析、知识工程等相关工作。
公众号推荐:
AIGC 技术正以惊人的速度重塑着创新的边界,InfoQ 首期《大模型领航者AIGC实践案例集锦》电子书,深度对话 30 位国内顶尖大模型专家,洞悉大模型技术前沿与未来趋势,精选 10 余个行业一线实践案例,全面展示大模型在多个垂直行业的应用成果,同时,揭秘全球热门大模型效果,为创业者、开发者提供决策支持和选型参考。关注「AI前线」,回复「领航者」免费获取电子书。


中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...







评论 1 条评论