编者按:InfoQ 开设新栏目“品味书香”,精选技术书籍的精彩章节,以及分享看完书留下的思考和收获,欢迎大家关注。本文节选自李浩著《 PostgreSQL 查询引擎源码技术探析》中的第4 章“查询逻辑优化”的第4 节“查询优化分析”。
4.4 查询优化分析
一棵完成 transform 和 rewrite 操作的查询树是否是一棵最优的查询树?如果不是,那么又该如何对该查询树进行优化?而优化所使用的策略正是本节要讨论的重点内容,而且优化部分也是整个查询引擎的难点。
子链接(SubLink)如何优化?子查询(SubQuery)又如何处理?对表达式(Expression)如何进行优化?如何寻找最优的查询计划(Cheapest Plan)?哪些因素会影响 JOIN 策略(Join Strategies)的选择,而这些策略又是什么?查询代价(Cost)又是如何估算的?何时需对查询计划进行物化(Plan Materialization)处理等一系列的问题。
在查询计划的优化过程中,对不同的语句类型有着不同的处理策略:
(1)对工具类语句(例如,DML、DDL 语句),不进行更进一步的优化处理。
(2)当语句为非工具语句时,PostgreSQL 使用 pg_plan_queries 对语句进行优化。
与前面一样,PostreSQL 也提供定制化优化引擎接口,我们可以使用自定义优化器 planner_hook,或者使用标准化优化器 standard_planner。
Pg_plan_queries 的函数原型如程序片段 4-15 所示。
程序片段 4-15 pg_plan_queries 的函数原型
List *
pg_plan_queries(List *querytrees, int cursorOptions, ParamListInfo boundParams)
{
List *stmt_list = NIL;
ListCell *query_list;
foreach(query_list, querytrees)
{
Query query = (Query ) lfirst(query_list);
Node *stmt;
if (query->commandType == CMD_UTILITY) // 工具类语句
{
/* Utility commands have no plans. */
stmt = query->utilityStmt;
}
else // 非工具类语句,使用 pg_plan_query 完成优化工作
{
stmt = (Node *) pg_plan_query(query, cursorOptions, boundParams);
}
stmt_list = lappend(stmt_list, stmt);
}
return stmt_list;
}
PlannedStmt *
planner(Query *parse, int cursorOptions, ParamListInfo boundParams)
{
PlannedStmt *result;
if (planner_hook)
result = (*planner_hook) (parse, cursorOptions, boundParams);
else
result = standard_planner(parse, cursorOptions, boundParams);
return result;
}
4.4.1 逻辑优化——整体架构介绍
在未使用第三方提供的优化器时,PostgreSQL 将 planner 函数作为优化的入口函数,并由函数 subquery_planner 来完成具体的优化操作。从图 4-1 中的 Call Stack 我们可以看出 planner 与 subquery_planner 之间的调用关系。
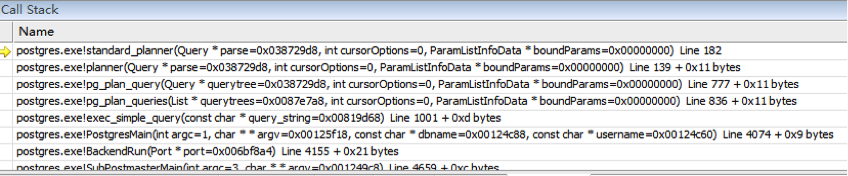
图 4-1 优化调用栈
函数以查询树作为输入参数,并以优化后语句作为返回值。
在 standard_planner 中,首先处理“DECLARE CURSOR stmt”形式的语句,即游标语句,并设置 tuple_fraction 值。那么 tuple_fraction 又是什么呢?
tuple_fraction 描述我们期望获取的元组的比例,0 代表我们需要获取所有的元组;当 tuple_faction∈(0,1) 时,表明我们需要从满足条件的元组中取出 tuple_faction 这么多比例的元组;当 tuple_faction∈[1,+∞) 时,表明我们将按照所指定的元组数进行检索,例如,LIMIT 语句中所指定的元组数。
完成对 tuple_faction 的设置后,进入后续优化流程,subquery_planner 的函数原型如程序片段 4-16 所示。
程序片段 4-16 standard_planner 的函数原型
PlannedStmt *
standard_planner(Query *parse, int cursorOptions, ParamListInfo boundParams)
{
PlannedStmt *result;
PlannerGlobal *glob;
double tuple_fraction;
PlannerInfo *root;
Plan *top_plan;
ListCell *lp, *lr;
/* Cursor options may come from caller or from DECLARE CURSOR stmt */
if (parse->utilityStmt &&
IsA(parse->utilityStmt, DeclareCursorStmt))
cursorOptions |= ((DeclareCursorStmt *) parse->utilityStmt)->options;
...
// 设置相关的 fraction 值
/* Determine what fraction of the plan is likely to be scanned */
if (cursorOptions & CURSOR_OPT_FAST_PLAN)
{
tuple_fraction = cursor_tuple_fraction;
if (tuple_fraction >= 1.0)
tuple_fraction = 0.0;
else if (tuple_fraction <= 0.0)
tuple_fraction = 1e-10;
}
else
{
/* Default assumption is we need all the tuples */
tuple_fraction = 0.0;
}
/* primary planning entry point (may recurse for subqueries) */
// 优化入口点
top_plan = subquery_planner(glob, parse, NULL,
false, tuple_fraction, &root);
if (cursorOptions & CURSOR_OPT_SCROLL)
{
if (!ExecSupportsBackwardScan(top_plan))
top_plan = materialize_finished_plan(top_plan);
}
...
Click and drag to move
}
这里也许读者会迷惑,为什么是 subquery_planner 呢?从名字上看该函数像是用来处理子查询,那么为什么用来作为整个查询语句优化的入口呢(Primary Entry Point)?
子查询语句作为查询语句的一部分,很大程度上与父查询具有相似的结构,同时两者在处理方式和方法上也存在着一定的相似性:子查询的处理流程可以在对其父查询的过程中使用。例如,本例中的子查询语句 SELECT sno FROM student WHERE student.classno = sub.classno,其处理方式与整个查询语句一样。因此,使用 subquery_planner 作为我们查询优化的入口,虽然从函数名上来看其似乎是用于子查询语句的处理。
由 gram.y 中给出的 SelectStmt 的定义可以看出,其中包括了诸如 WINDOWS、HAVING、ORDER BY、GROUP BY 等子句。那么 subquery_planner 函数似乎也应该有相应于这些语句的优化处理。就这点而言,subquery_planner 与原始语法树到查询树的转换所采取的处理方式相似。根据上述分析,我们可给出如程序片段 4-17 所示的 subquery_planner 的函数原型。
程序片段 4-17 subquery_planner 的函数原型
Plan* subquery_planner (PlannerGlobal* global, Query* query, …)
{
…
process_cte (global, query);
…
process_sublink(global, query);
…
process_subqueries(global, query) ;
…
process_expression (query->targetlist, TARGET,…) ;
…
process_expression (query->returning, RETURNING,…) ;
…
process_quals_codition(query->jointree,…) ;
…
}
按照上述给出的原型,只要完成假定的 process_xxx 函数,就可以实现对查询语法树的优化工作。是不是觉得很简单?当然不是,原理很简单,但是理论与实际还有一定的距离。例如,如何处理查询中大量出现的子链接?如何对δ算子执行“下推”?如何选择索引?如何选择 JOIN 策略?这些都需要我们仔细处理。
PostgreSQL 给出的 subquery_planner 如程序片段 4-18 所示。
程序片段 4-18 subquery_planner 函数的实现代码
Plan *
subquery_planner(PlannerGlobal *glob, Query *parse,
PlannerInfo *parent_root, bool hasRecursion,
double tuple_fraction, PlannerInfo **subroot)
{
int num_old_subplans = list_length(glob->subplans);
PlannerInfo *root;
…
/* Create a PlannerInfo data structure for this subquery */
root = makeNode(PlannerInfo);
…
root->hasRecursion = hasRecursion;
if (hasRecursion)
root->wt_param_id = SS_assign_special_param(root);
else
root->wt_param_id = -1;
root->non_recursive_plan = NULL;
if (parse->cteList)
SS_process_ctes(root);
if (parse->hasSubLinks)
pull_up_sublinks(root); // 子连接上提操作
inline_set_returning_functions(root);
parse->jointree = (FromExpr *)
pull_up_subqueries(root,(Node *) parse->jointree); // 子查询处理
if (parse->setOperations)
flatten_simple_union_all(root);
...
parse->targetList = (List *)
preprocess_expression(root,(Node *) parse->targetList,
EXPRKIND_TARGET);// 目标列处理
...
parse->returningList = (List *)
preprocess_expression(root,(Node *) parse->returningList,
EXPRKIND_TARGET);//returning 语句处理
preprocess_qual_conditions(root,(Node *) parse->jointree);// 处理条件语句
parse->havingQual = preprocess_expression(root, parse->havingQual,
EXPRKIND_QUAL);
foreach(l, parse->windowClause)
{
WindowClause *wc = (WindowClause *) lfirst(l);
/* partitionClause/orderClause are sort/group expressions */
wc->startOffset = preprocess_expression(root, wc->startOffset,
EXPRKIND_LIMIT);
wc->endOffset = preprocess_expression(root, wc->endOffset,
EXPRKIND_LIMIT);
}
parse->limitOffset = preprocess_expression(root, parse->limitOffset,
EXPRKIND_LIMIT);
parse->limitCount = preprocess_expression(root, parse->limitCount,
EXPRKIND_LIMIT);
root->append_rel_list = (List *)
preprocess_expression(root, (Node *) root->append_rel_list,
EXPRKIND_APPINFO);
...
newHaving = NIL;
foreach(l, (List *) parse->havingQual)//having 子句优化处理
{
...
}
parse->havingQual = (Node *) newHaving;
...
return plan;
Click and drag to move
}
由 PostgreSQL 给出的实现可以看出,核心处理思想与我们讨论的相一致:依据类型对查询语句进行分类处理。
这里需要读者注意的一点就是查询计划的生成部分,PostgreSQL 将查询计划的生成也归入 subquery_planner 中,但为了方便问题的讨论,我们并未将查询计划的生成部分在 subquery_planner 中给出。我们将查询优化的主要步骤总结如下:
- 处理 CTE 表达式,ss_process_ctes;
- 上提子链接,pull_up_sublinks;
- FROM 子句中的内联函数,集合操作,RETURN 及函数处理,inline_set_returning_ functions;
- 上提子查询,pull_up_subqueries;
- UNION ALL 语句处理,flatten_simple_union_all;
- 处理 FOR UPDATE(row lock)情况,preprocess_rowmarks;
- 继承表的处理,expand_inherited_tables;
- 处理目标列(target list),preprocess_expression;
- 处理 withCheckOptions,preprocess_expression;
- 处理 RETURN 表达式,preprocess_expression;
- 处理条件语句 -qual,preprocess_qual_conditions;
- 处理 HAVING 子句,preprocess_qual_conditions;
- 处理 WINDOW 子句,preprocess_qual_conditions;
- 处理 LIMIT OFF 子句,preprocess_qual_conditions;
- WHERE 和 HAVING 子句中的条件合并,如果存在能合并的 HAVING 子句则将其合并到 WHERE 条件中,否则保留在 HAVING 子句中;
- 消除外连接(Outer Join)中的冗余部分,reduce_outer_joins;
- 生成查询计划,grouping_planner。
书籍介绍

PostgreSQL 作为当今最先进的开源关系型数据库,本书揭示 PostgreSQL 查询引擎运行原理和实现技术细节,其中包括:基础数据结构;SQL 词法语法分析及查询语法树;查询分析及查询重写;子连接及子查询处理;查询访问路径创建;查询计划生成,等等。以深入浅出的方式讨论每个主题并结合基础数据结构、图表、源码等对所讨论的主题进行详细分析,以使读者对 PostgreSQL 查询引擎的运行机制及实现细节能有全面且深入的认识。




