

下一代英特尔 C/C++编译器的表现会更加出色,因为它们将使用 LLVM 开源基础架构。
LLVM 帮助我们实现了为英特尔架构提供更加优秀的 C/C++编译器这一目标。最新的英特尔 C/C++编译器使用 LLVM 架构,可提供更快的编译时间、更好的优化、增强的标准支持以及对 GPU 和 FPGA 负载转移(offloading)的支持。
在这篇文章中,我将分享我们采用 LLVM 的相关信息。我将讨论这对编译器的用户有哪些意义、我们为什么这样做以及未来的光明前景。英特尔 C/C++编译器采用 LLVM 的工作已经完成,我还会分享关于英特尔 Fortran 编译器采用 LLVM 这一重要(但尚未完成)计划的更新信息。
采用 LLVM 的好处有很多。我会建议大家从经典编译器升级到基于 LLVM 的编译器。我们正努力让这一过程尽可能无缝平滑,同时为使用英特尔编译器的开发人员提供大量收益。
采用 LLVM 的好处
LLVM 开源项目是模块化和可重用的编译器和一系列工具链技术的集合,整个项目支持多种处理器架构和编程语言。Clang 开源项目提供了一个 C/C++前端,为 LLVM 项目支持了最新的语言标准。包括 Clang 在内,LLVM 是由一个庞大且非常活跃的开发社区维护的。
采用 LLVM 的好处有很多,第一条要说的是更快的构建时间。众所周知,Clang 是很快的!我们使用英特尔 oneAPI 2021.3工具包中的英特尔 C/C++编译器时,测得构建时间减少了 14%。除了减少构建时间外,采用 Clang 使我们可以从社区支持最新 C++语言标准的一系列成果中受益,并贡献成果来反哺社区。
英特尔为开源项目提供贡献和支持的历史颇为悠久,其中我们向 LLVM 做出贡献就有十年时间了。我们今天的主动合作行为包括了优化报告补充、扩大的浮点模型支持,以及向量增强。英特尔直接对 LLVM 项目做出贡献,我们也有一个临时区域(英特尔 LLVM 技术项目),针对 SYCL 支持。
在英特尔架构上,英特尔 C/C++编译器预期能提供比基础 Clang+LLVM 编译器更高的性能。接下来英特尔 C/C++编译器都会是采用了 LLVM 开源基础架构的版本(icx)。我们会继续之前的长期努力,持续为 Clang 和 LLVM 项目做出贡献,包括为它们提供优化。并非所有的优化技术都会被上游采纳,有时是因为它们太新了,有时因为它们过于针对英特尔架构。这是可以预料的,并且与其他已经采用 LLVM 的编译器是同样的情况。
我们使用英特尔 oneAPI 工具包 2021.3 版本中发布的最新英特尔 C/C++编译器进行了一系列的性能测试。我们的目标是为英特尔架构提供一流的 C/C++编译器,而我们的测试结果证明了这一点,表明英特尔 C/C++编译器击败了其他所有对手。我们也战胜了自己:新的基于 LLVM 的英特尔 C/C++编译器在性能上打平或超越了经典版本。现在是时候升级你使用的编译器了!我在这里先分享一个例子,文末提供了更多测试结果。
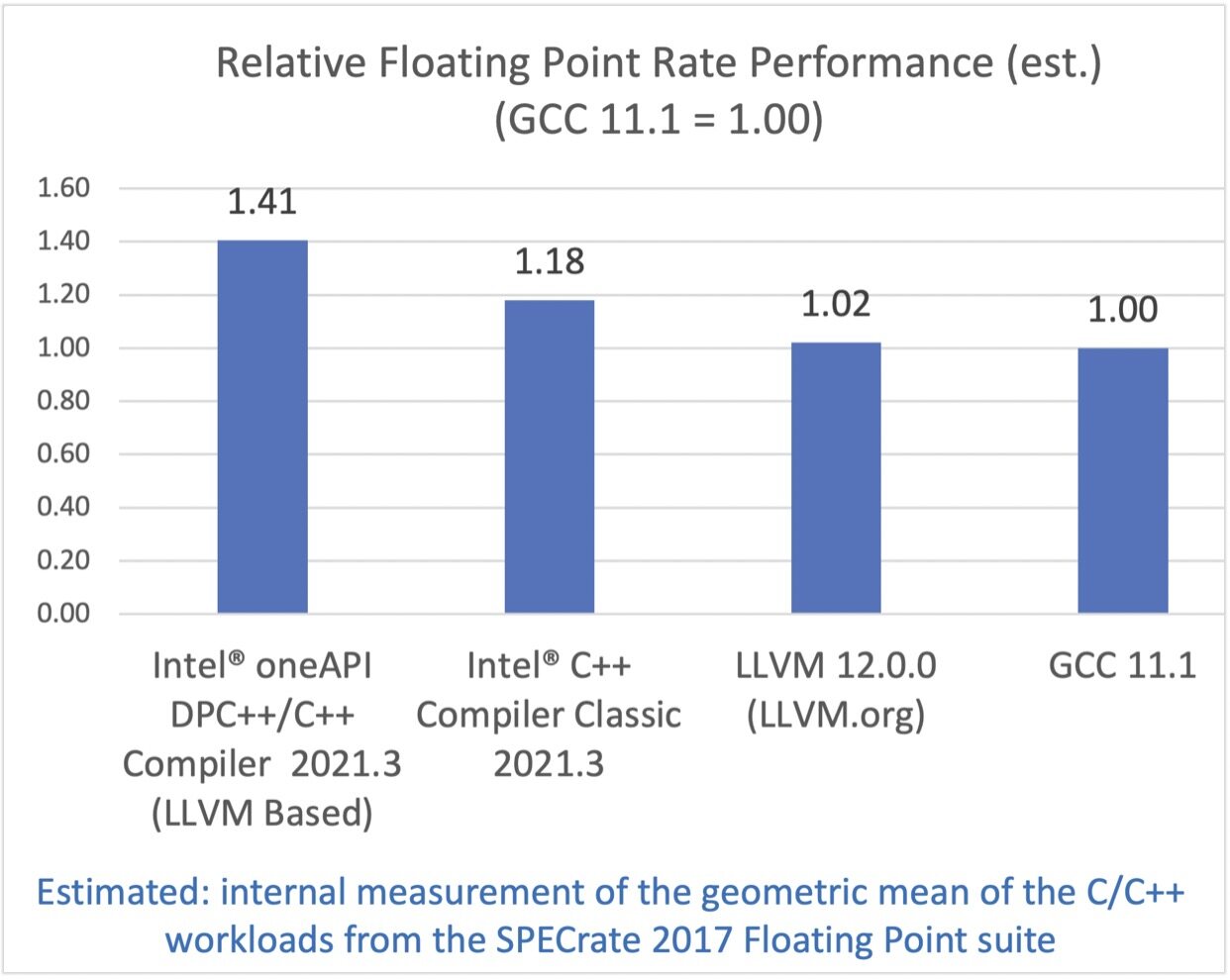
英特尔 C/C++编译器一直都在提供最优秀的性能。经典版本的英特尔 C/C++编译器取得了对 GCC 18%的优势,而基于 LLVM 的英特尔 C/C++编译器取得了41%的优势。
为支持英特尔不断发展的众多平台,我们在基于 LLVM 的编译器中重点关注了新特性和新硬件支持。除了继续提供业界一流的 CPU 优化之外,我们还加入了对 GPU 和 FPGA 的高度优化的支持。我们基于 LLVM 的编译器将提供对 SYCL、C++20、OpenMP 5.1 和 OpenMP GPU 目标设备的支持。
我们鼓励用户现在就转向基于 LLVM 的 C/C++编译器,享用更快的构建时间、更高级别的优化和新功能等收益。英特尔会长期坚持使用 LLVM,在这条道路上不断创新、持续追求业界一流的优化成果。
Parallel Studio XE 编译器发生了什么变化?
2007 年,我们开始使用“Parallel Studio”这个新名字,强调这款工具对并行性的支持。彼时世界正在发生变革,并行编程注定要伴随多核处理器的普及而得到全面推广。一开始是单核处理器被双核处理器取代。如今,处理器核心数量已经达到了几十个的水平,且仍在持续增长。
就像针对同构系统的并行编程广泛普及一样,我们看到针对异构系统的并行编程也走上了类似的道路。与多核并行性不同的是,异构编程会利用来自多个供应商的计算能力。这带来了让编程碎片化的风险,除非我们共同努力来支持开放的多源方法,为软件开发人员提供编译器、库、框架和整套工具链。
我们给这款流行工具的下一代版本取的新名字是为了强调针对异构并行的单一 API 开放方法。这些工具依旧具备获得行业数十年信赖的产品品质,并通过拥抱 oneAPI规范和 SYCL标准提供了对异构编程的支持。现在你就可以免费下载并开始使用这些工具了!英特尔社区论坛提供了社区支持。英特尔将继续为提交的问题,疑难和其他技术支持问题提供优先支持。
C/C++已就绪
我们建议所有的新项目直接使用基于 LLVM 的英特尔 C/C++编译器,而所有现有项目应该制定一个计划,在今年迁移到新的编译器。在未来的某个时候,经典 C/C++编译器将进入“旧版产品支持”模式,意味着对经典编译器代码库的更新终结,且它们不会再出现在 oneAPI 工具包中。
新的基于 LLVM 的英特尔 C/C++编译器已经取得了与经典版本相当的表现,前者也提供了我们已有的最佳优化技术。我们建议所有用户都应该立即尝试新的 C/C++编译器,享受它带来的好处,并提供反馈。
这里有一份很棒的指南来帮助你从经典的 C/C++编译器转向基于 LLVM 的编译器。你会注意到的第一件事是新编译器改了名字(icx)。这可以让你同时安装经典版本和新版本,并在它们之间自由切换。许多用户已经决定在未来产品中只使用基于 LLVM 的英特尔 C/C++编译器。最新的发行说明提供了更多关于已知问题和限制的细节(这里则是针对经典 C/C++编译器版本的说明)。你还可以观看我们的网络研讨会(“与专家对话”),观看专家直播或通过点播观看先前录制的会议。
基于 LLVM 的英特尔 Fortran 编译器正在开发中
众所周知,英特尔 Fortran 编译器一直都在提供广泛的标准支持和优越的性能表现。当我们完成基于 LLVM 的英特尔 Fortran 编译器测试计划时,这一传统也会得到延续。我们欢迎大家提供反馈。
基于 LLVM 的 Fortran 编译器测试版提供了对 Fortran 语言的广泛支持,但有些功能仍在开发中。你可以查看具体特性的开发状态,看它是否已准备就绪:在我们的Fortran和OpenMP特性状态表中可以找到基于 LLVM 的 Fortan 编译器中各个特性的发布状态。这里是 Fortran 编译器发行说明,同时提供了经典版本和基于 LLVM 测试版本的说明。
今年晚些时候我会发布一篇博文,更新我们基于 LLVM 的 Fortran 编译器的开发进度。
英特尔编译器开启全新篇章
英特尔 C/C++和 Fortran 编译器产品的历史源远流长,它们始于 20 世纪 90 年代早期的 Unix System V 编译器,并在 90 年代中期加入了来自 Multiflow 的编译器技术。我们在 2000 年代获得了来自 DEC/康柏的 Fortran 团队,和 Kuck and Associates Inc.(KAI)的 OpenMP 和并行性专业知识。随着英特尔编译器进入第四个十年,它们会在 LLVM 编译器技术的帮助下继续这一旅程。英特尔编译器的用户将继续看到强大的标准支持、可靠的代码优化和满足用户需求的积极态度。我们还会提供对异构编程的一流支持。
我们会继续努力将英特尔 C/C++和 Fortran 编译器打造成为重要和有用的工具,帮助你构建改变世界的应用程序。
英特尔编译器下载方式
英特尔编译器的用户现在可以充分利用英特尔数十年来针对英特尔架构和 OpenMP 的专业优化成果与 LLVM 的优势。
请从 oneAPI 工具包网站下载新版。
有任何思考、反馈和建议,请在英特尔社区 James-Reinders 博客发表评论。
更多基准测试结果和配置细节
总的来说,这些基准测试显示已经达到了一个临界点,标志着基于 LLVM 的编译器已准备好成为所有用户的首选编译器。
更快的编译速度
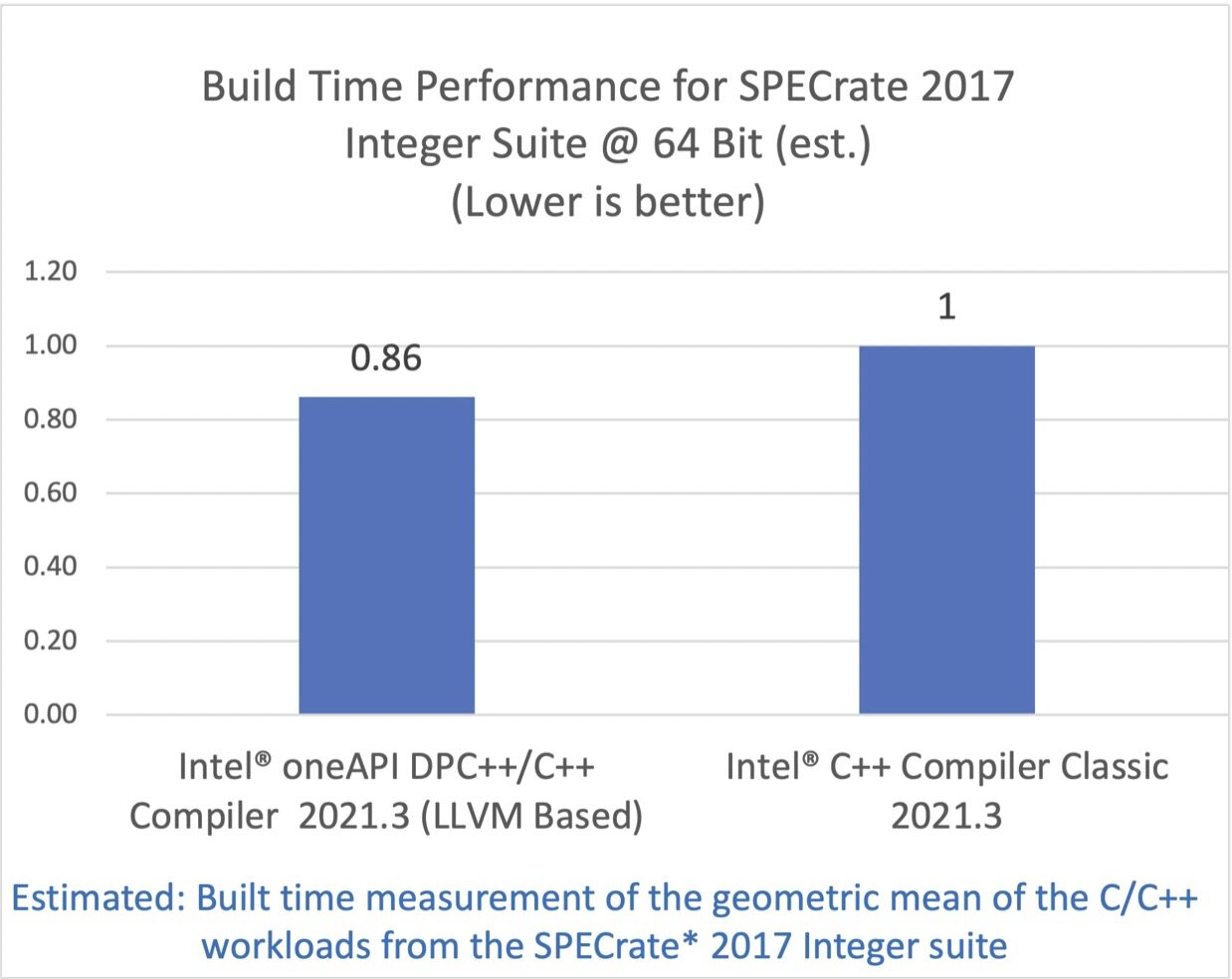
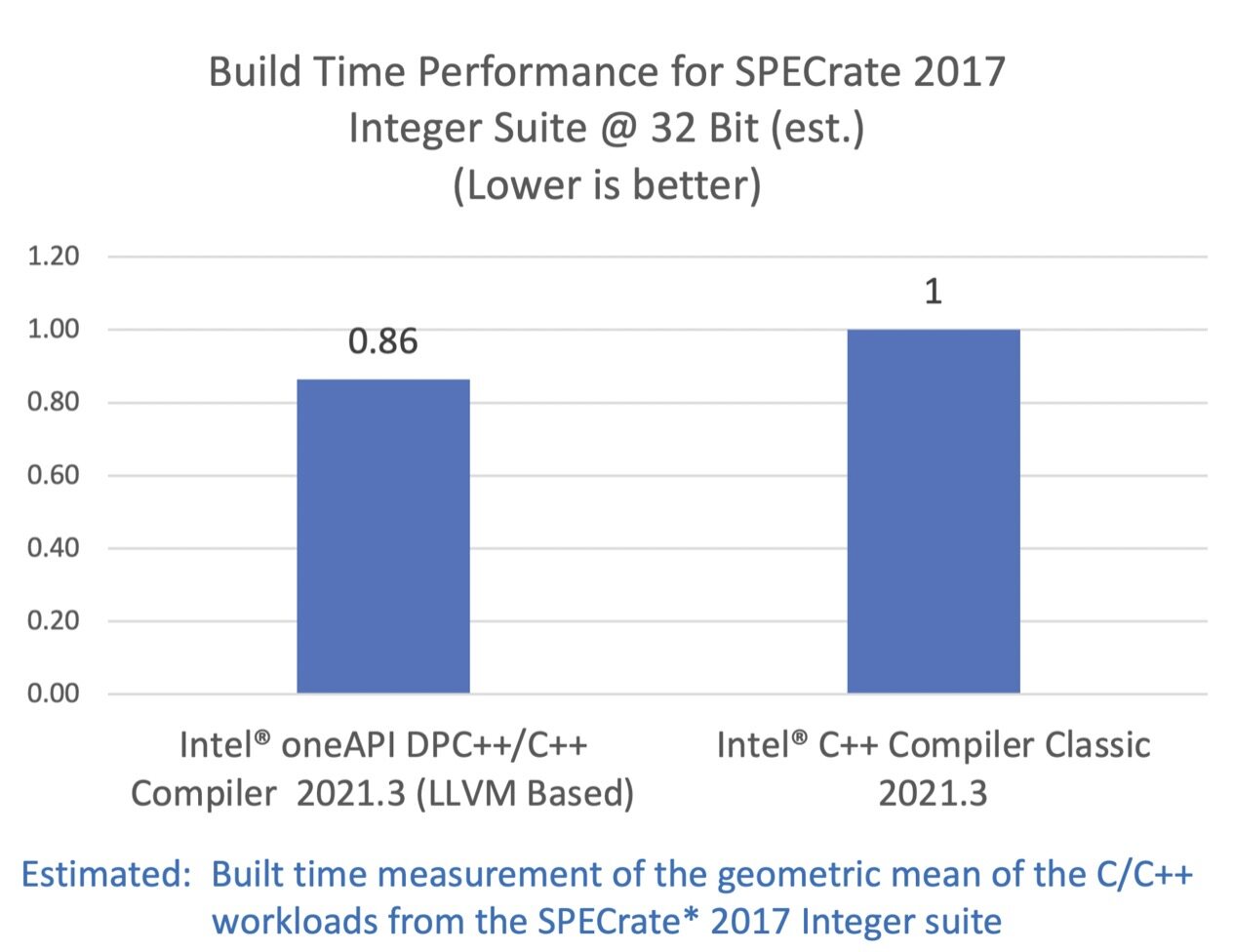
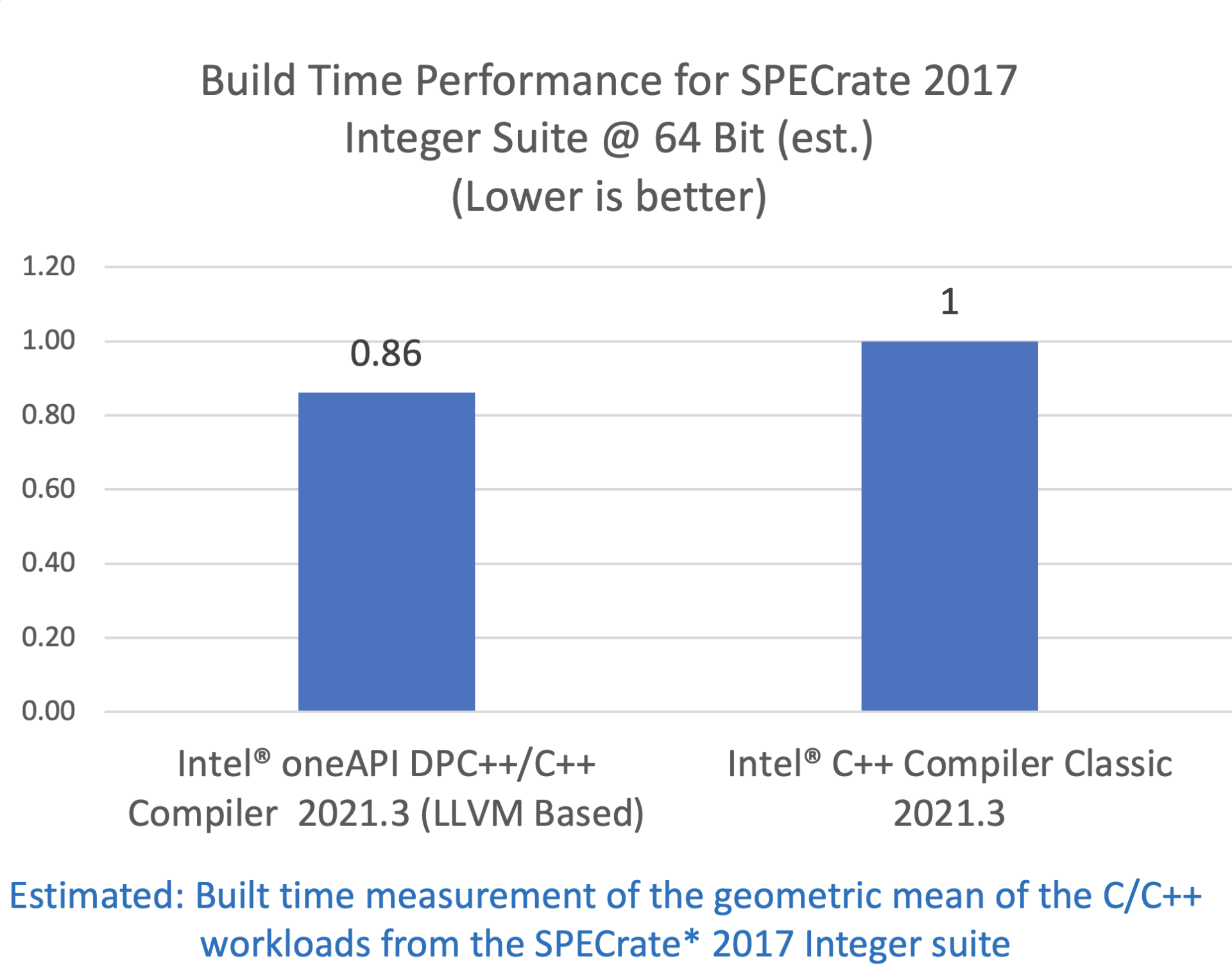
SPEC CPU 2017 基准测试包中包含了一系列行业标准的 CPU 密集型测试套件,用于测试和对比计算密集型性能表现,考验系统的处理器、内存子系统和编译器。关于 SPEC 基准测试的更多信息可以在这里找到。
配置:测试由英特尔在 2021 年 6 月 10 日完成。Intel(R) Core(TM) i7-8700K CPU @ 3.70GHz, 16G x2 DDR4 2666. Red Hat Enterprise Linux release 8.0 (Ootpa), 4.18.0-80.el8.x86_64. 软件:Intel(R) 64 Compiler Classic for applications running on Intel(R) 64, Version 2021.3.0 Build 20210604_000000. Intel(R) oneAPI DPC++/C++ Compiler for applications running on Intel(R) 64, Version 2021.3.0 Build 20210604. 编译器开关:Intel(R) 64 Compiler Classic: -O2 -xCORE-AVX512, Intel(R) oneAPI DPC++/C++ Compiler: -O2 -xCORE-AVX512
优化的性能表现
SPECrate 2017(Estimated)
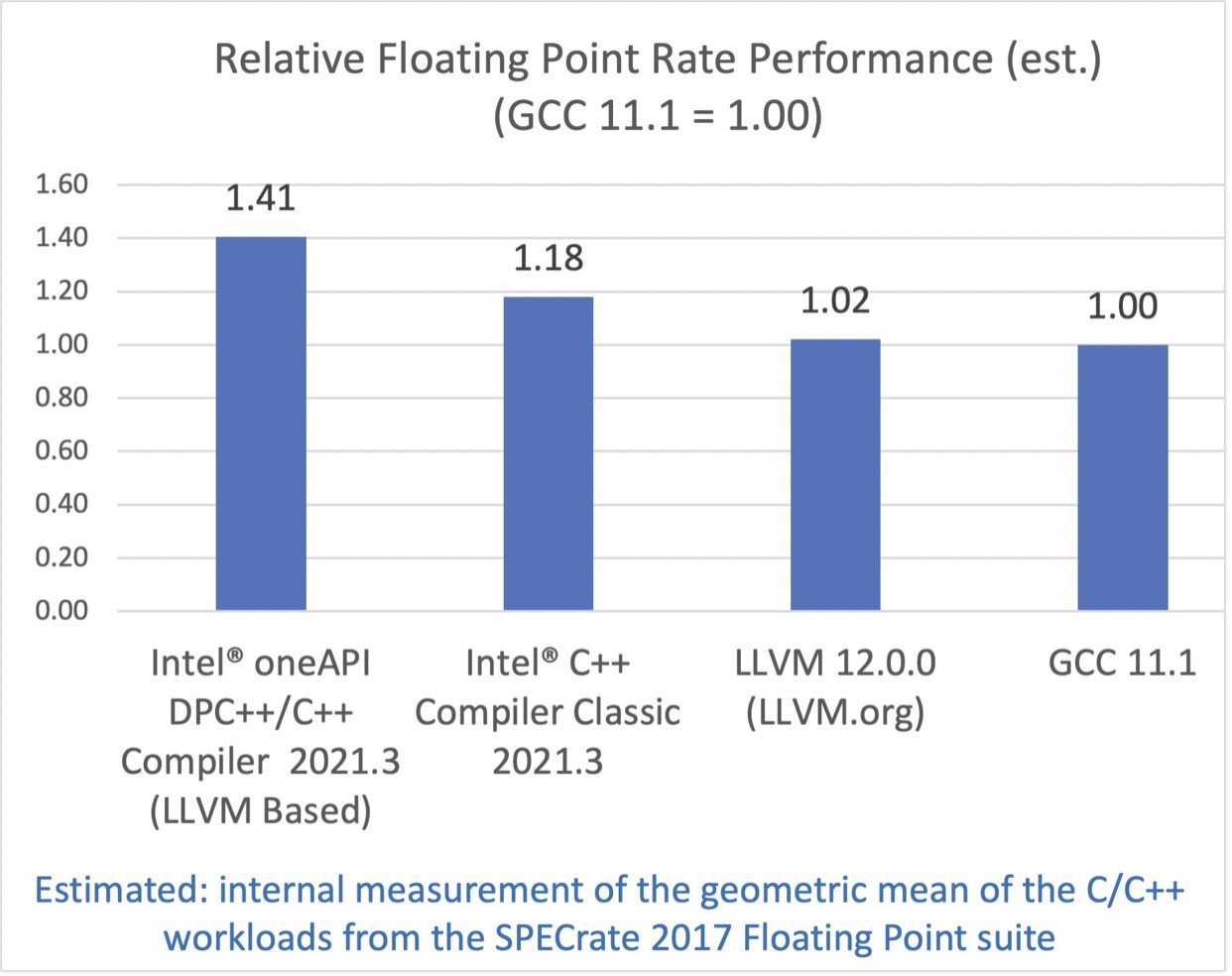
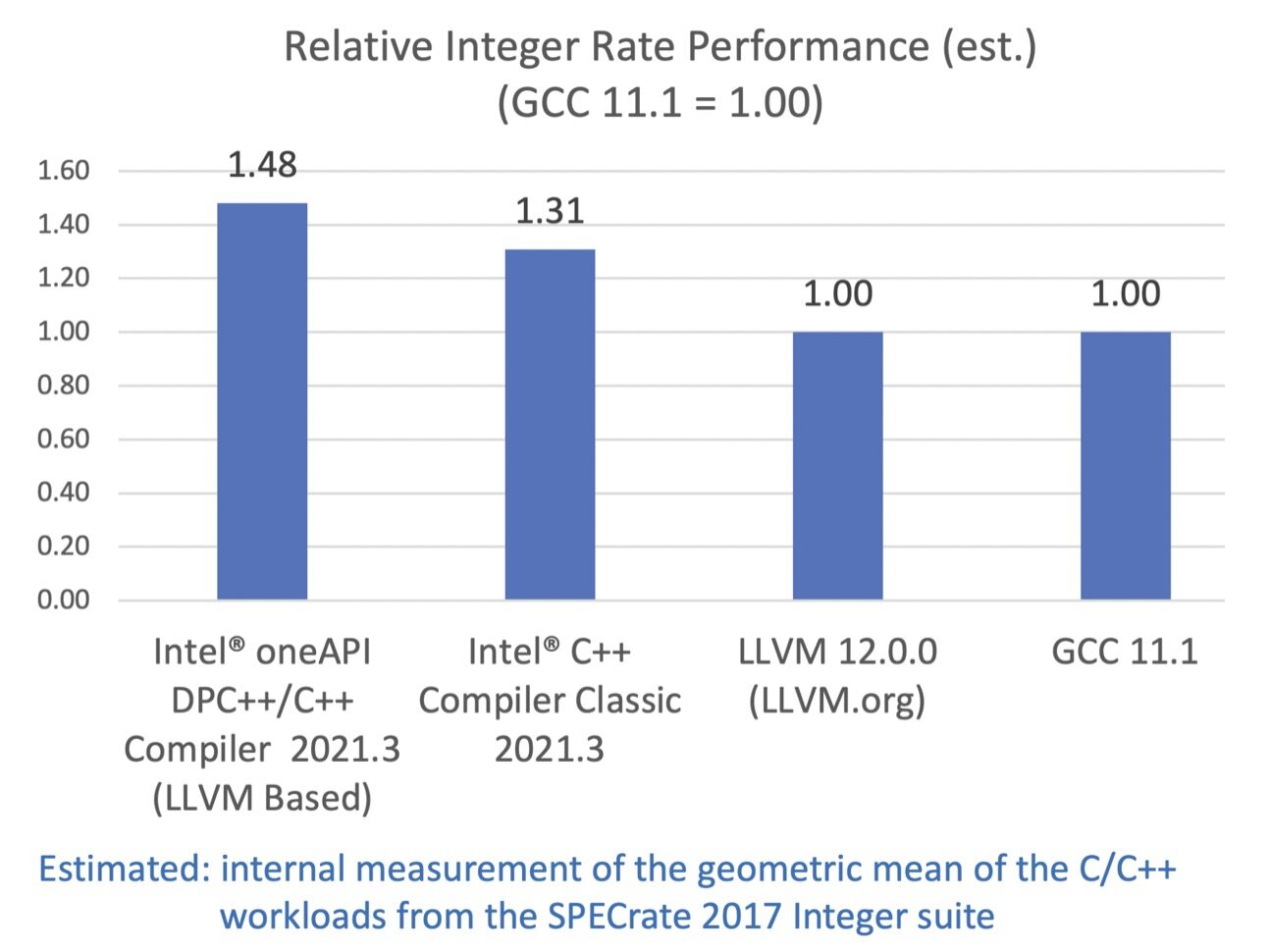
SPEC CPU 2017 基准测试包中包含了一系列行业标准的 CPU 密集型测试套件,用于测试和对比计算密集型性能,考验系统的处理器,内存子系统和编译器。关于 SPEC 基准测试的更多信息可以在这里找到。
配置:测试由英特尔在 2021 年 6 月 10 日完成。Intel(R) Xeon(R) Platinum 8380 CPU @ 2.30GHz, 2 socket, Hyper Thread on, Turbo on, 32G x16 DDR4 3200 (1DPC). Red Hat Enterprise Linux release 8.2 (Ootpa), 4.18.0-193.el8.x86_64. 软件:Intel(R) oneAPI DPC++/C++ Compiler for applications running on Intel(R) 64, Version 2021.3.0 Build 20210604. Intel(R) C++ Intel(R) 64 Compiler Classic for applications running on Intel(R) 64, Version 2021.3.0 Build 20210604_000000, GCC 11.1, Clang/LLVM 12.0.0. SPECint®_rate_base_2017 编译器开关:Intel(R) oneAPI DPC++/C++ Compiler: -xCORE-AVX512 -O3 -ffast-math -flto -mfpmath=sse -funroll-loops -qopt-mem-layout-trans=4. Intel(R) C++ Intel(R) 64 Compiler Classic: -xCORE-AVX512 -ipo -O3 -no-prec-div -qopt-mem-layout-trans=4 -qopt-multiple-gather-scatter-by-shuffles. GCC: -march=skylake-avx512 -mfpmath=sse -Ofast -funroll-loops -flto -mprefer-vector-width=128. LLVM: -march=skylake-avx512 -mfpmath=sse -Ofast -funroll-loops -flto. qkmalloc used for intel compiler. jemalloc 5.0.1 used for gcc and llvm. SPECfp®_rate_base_2017 编译器开关:Intel(R) oneAPI DPC++/C++ Compiler: -xCORE-AVX512 -Ofast -ffast-math -flto -mfpmath=sse -funroll-loops -qopt-mem-layout-trans=4. Intel(R) C++ Intel(R) 64 Compiler Classic: -xCORE-AVX512 -ipo -O3 -no-prec-div -qopt-prefetch -ffinite-math-only -qopt-multiple-gather-scatter-by-shuffles -qopt-mem-layout-trans=4. GCC: -march=skylake-avx512 -mfpmath=sse -Ofast -fno-associative-math -funroll-loops -flto. LLVM: -march=skylake-avx512 -mfpmath=sse -Ofast -funroll-loops -flto.
SPECspeed 2017(Estimated)
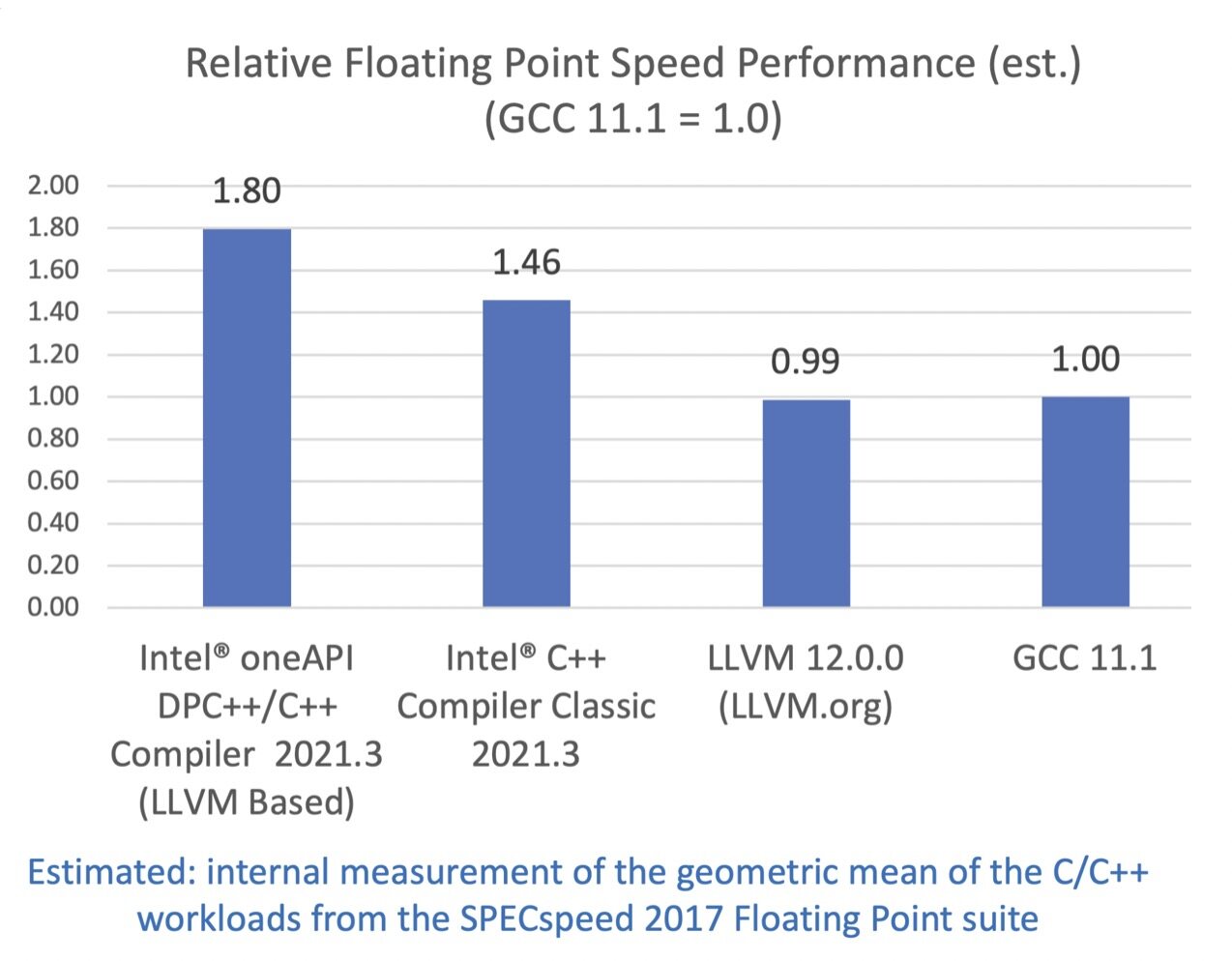

SPEC CPU 2017 基准测试包中包含了一系列行业标准的 CPU 密集型测试套件,用于测试和对比计算密集型性能,考验系统的处理器,内存子系统和编译器。关于 SPEC 基准测试的更多信息可以在这里找到。
配置:测试由英特尔在 2021 年 6 月 10 日完成。Intel(R) Xeon(R) Platinum 8380 CPU @ 2.30GHz, 2 socket, Hyper Thread on, Turbo on, 32G x16 DDR4 3200 (1DPC). Red Hat Enterprise Linux release 8.2 (Ootpa), 4.18.0-193.el8.x86_64. 软件:Intel(R) oneAPI DPC++/C++ Compiler for applications running on Intel(R) 64, Version 2021.3.0 Build 20210604. Intel(R) C++ Intel(R) 64 Compiler Classic for applications running on Intel(R) 64, Version 2021.3.0 Build 20210604_000000, GCC 11.1, Clang/LLVM 12.0.0. SPECint®_speed_base_2017 编译器开关:Intel(R) oneAPI DPC++/C++ Compiler: -xCORE-AVX512 -O3 -ffast-math -flto -mfpmath=sse -funroll-loops -qopt-mem-layout-trans=4 -fiopenmp. Intel(R) C++ Intel(R) 64 Compiler Classic: -xCORE-AVX512 -ipo -O3 -no-prec-div -qopt-mem-layout-trans=4 -qopt-GCC: -march=skylake-avx512 -mfpmath=sse -Ofast -funroll-loops -flto –fopenmp. LLVM: -march=skylake-avx512 -mfpmath=sse -Ofast -funroll-loops -flto -fopenmp=libomp. multiple-gather-scatter-by-shuffles -qopenmp. jemalloc 5.0.1 used for intel compiler, gcc and llvm. SPECfp®_speed_base_2017 编译器开关:Intel(R) oneAPI DPC++/C++ Compiler: -xCORE-AVX512 -Ofast -ffast-math -flto -mfpmath=sse -funroll-loops -qopt-mem-layout-trans=4 -fiopenmp. Intel(R) C++ Intel(R) 64 Compiler Classic: -xCORE-AVX512 -ipo -O3 -no-prec-div -qopt-prefetch -ffinite-math-only -qopt-multiple-gather-scatter-by-shuffles -qopenmp. GCC: -march=skylake-avx512 -mfpmath=sse -Ofast -fno-associative-math -funroll-loops -flto –fopenmp. LLVM: -march=skylake-avx512 -mfpmath=sse -Ofast -funroll-loops -flto -fopenmp=libomp. jemalloc 5.0.1 used for intel compiler, gcc and llvm.
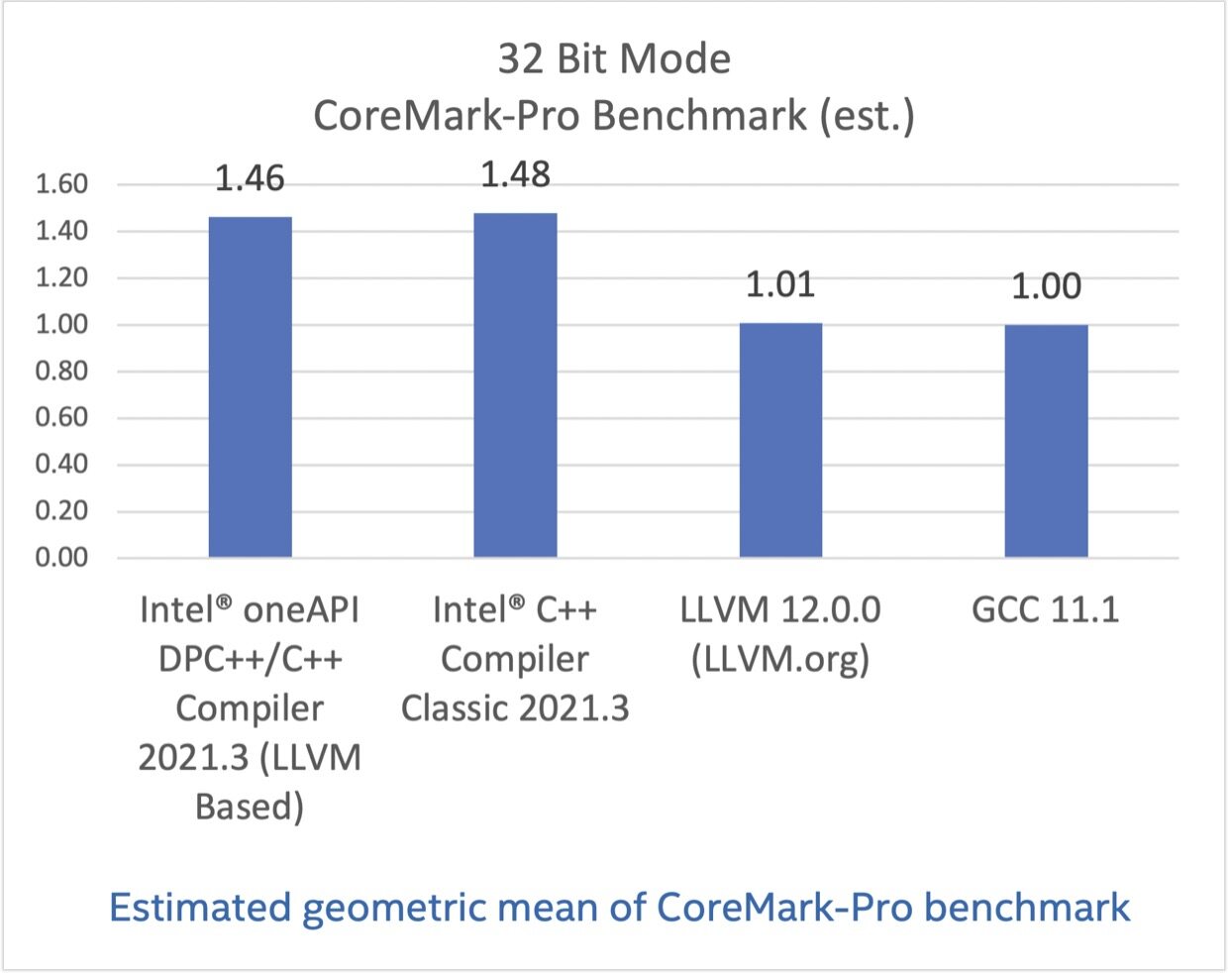
CoreMark-Pro,基于英特尔®酷睿 i7-8700K 处理器测试
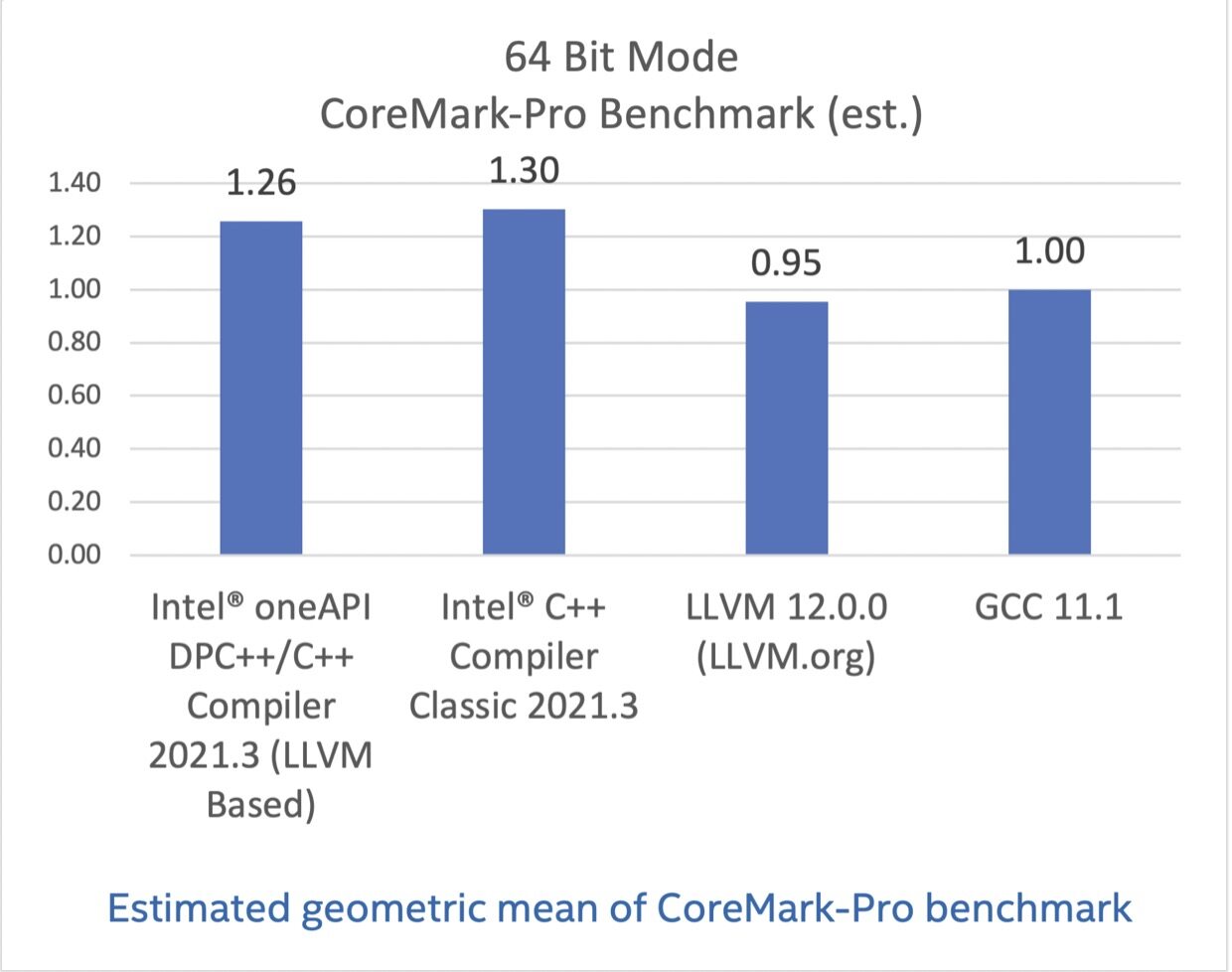
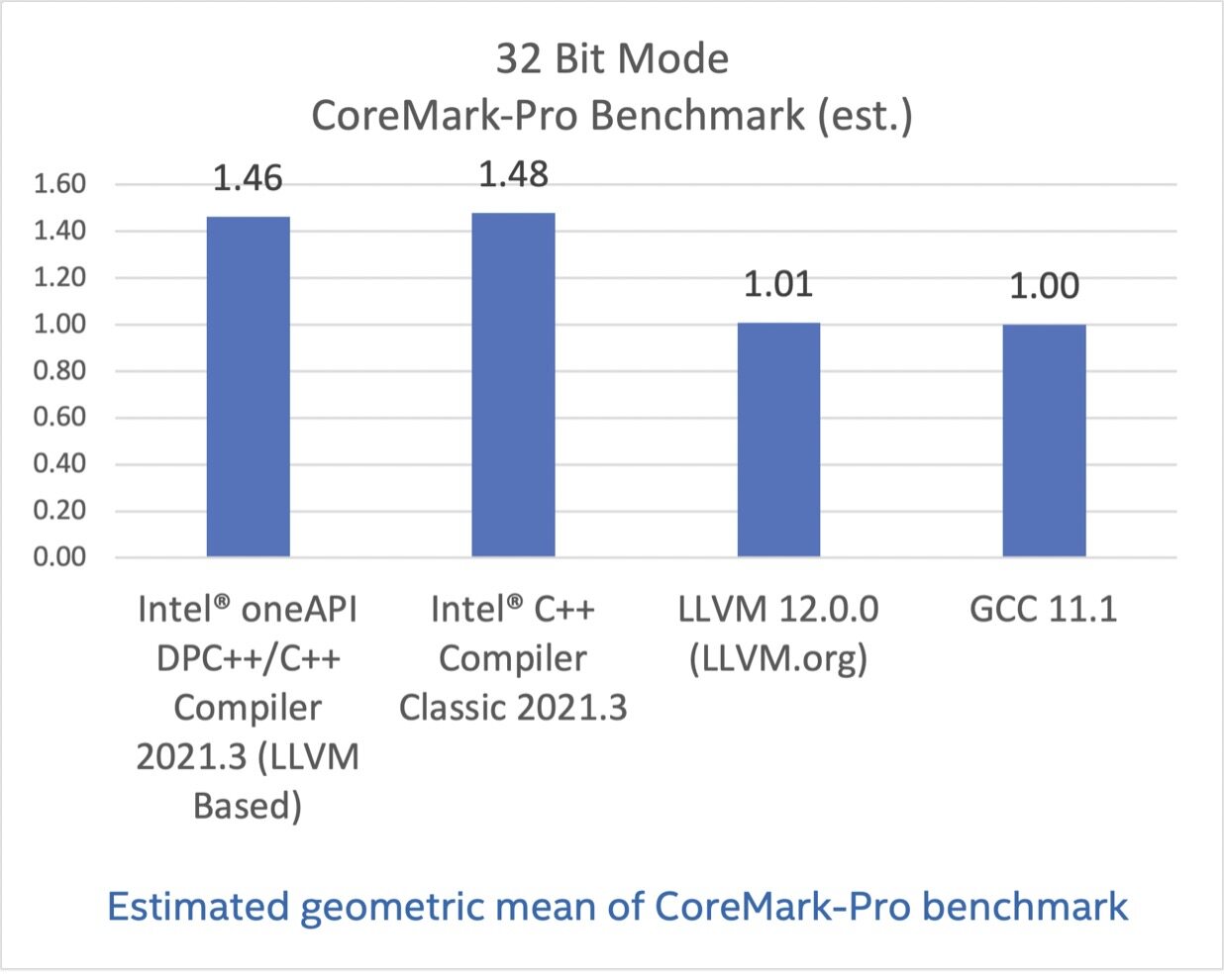
CoreMark-Pro 旨在测试处理器整体表现,其充分支持多核技术,提供了整数和浮点负载组合,并为内存子系统压力测试提供了测试数据集。CoreMark-Pro 来自嵌入式微处理器基准测试集(EEMBC),更多信息可访问这里。
在这些基准测试结果中,英特尔编译器选项都已关闭,但成绩显示基于 LLVM 的英特尔编译器与经典版本还有一些差距。我希望你也能认同这点差距并不算大,毕竟其他结果显示我们的基于 LLVM 的编译器有着优异的表现。
配置:测试由英特尔在 2021 年 6 月 10 日完成。Intel(R) Core(TM) i7-8700K CPU @ 3.70GHz, 16G x2 DDR4 2666. 软件:Intel(R) C++ Compiler Classic for applications running on Intel(R) 64, Version 2021.3.0 Build 20210604_000000, GCC 11.1, Clang/LLVM 12.0.0. Red Hat Enterprise Linux release 8.0 (Ootpa), 4.18.0-80.el8.x86_64. 编译器开关: Intel(R) C++ Compiler Classic for applications running on Intel(R) 64, Version 2021.1 Build 20201112_000000: icc -xCORE-AVX2 -mtune=skylake -ipo -O3 -no-prec-div -qopt-prefetch. GCC 11.1: gcc -march=native -mfpmath=sse -Ofast -funroll-loops -flto. LLVM 12.0.0: clang -Ofast -funroll-loops -flto -static -mfpmath=sse -march=native.
CoreMark-Pro,基于英特尔®Atom C3850 处理器测试
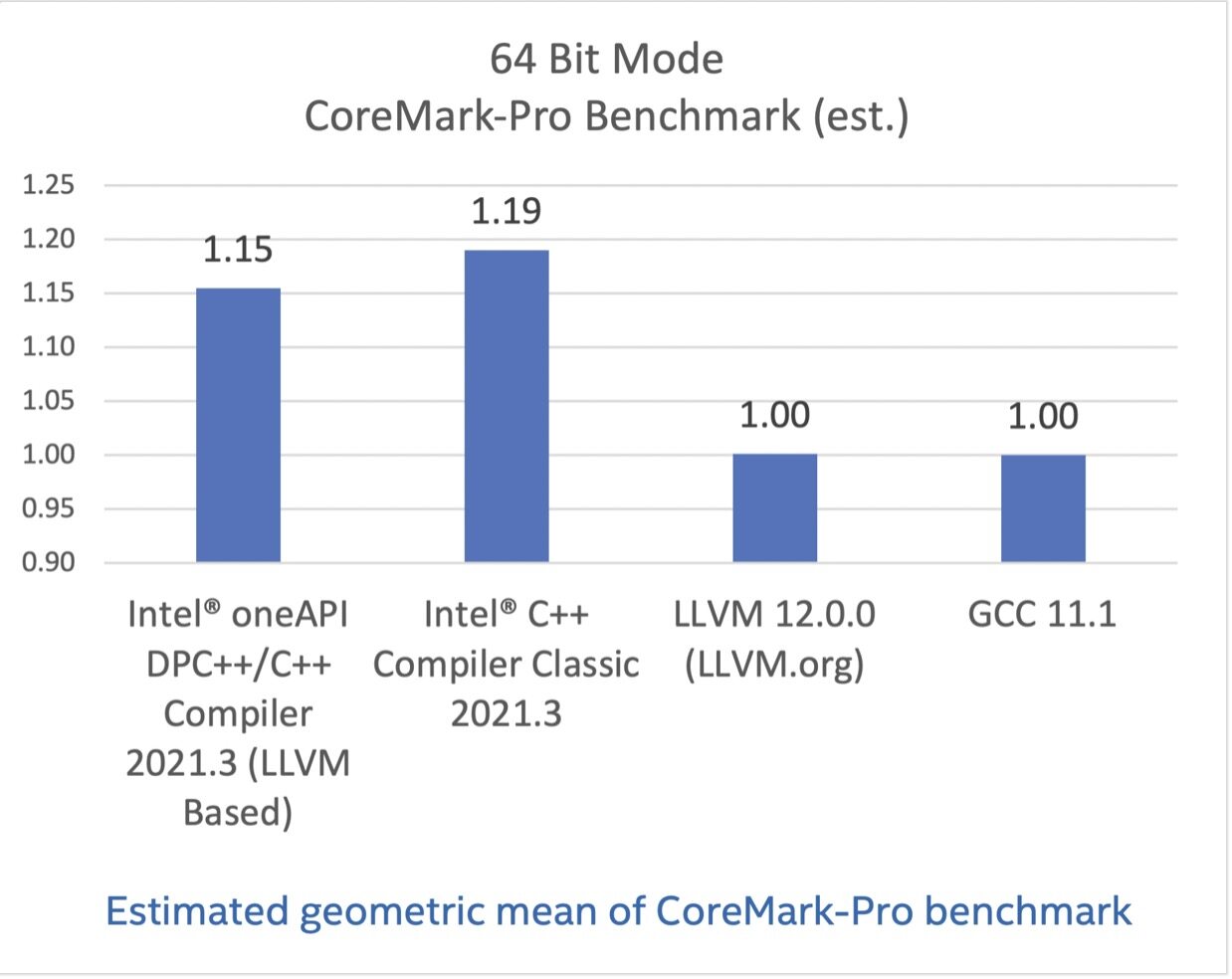
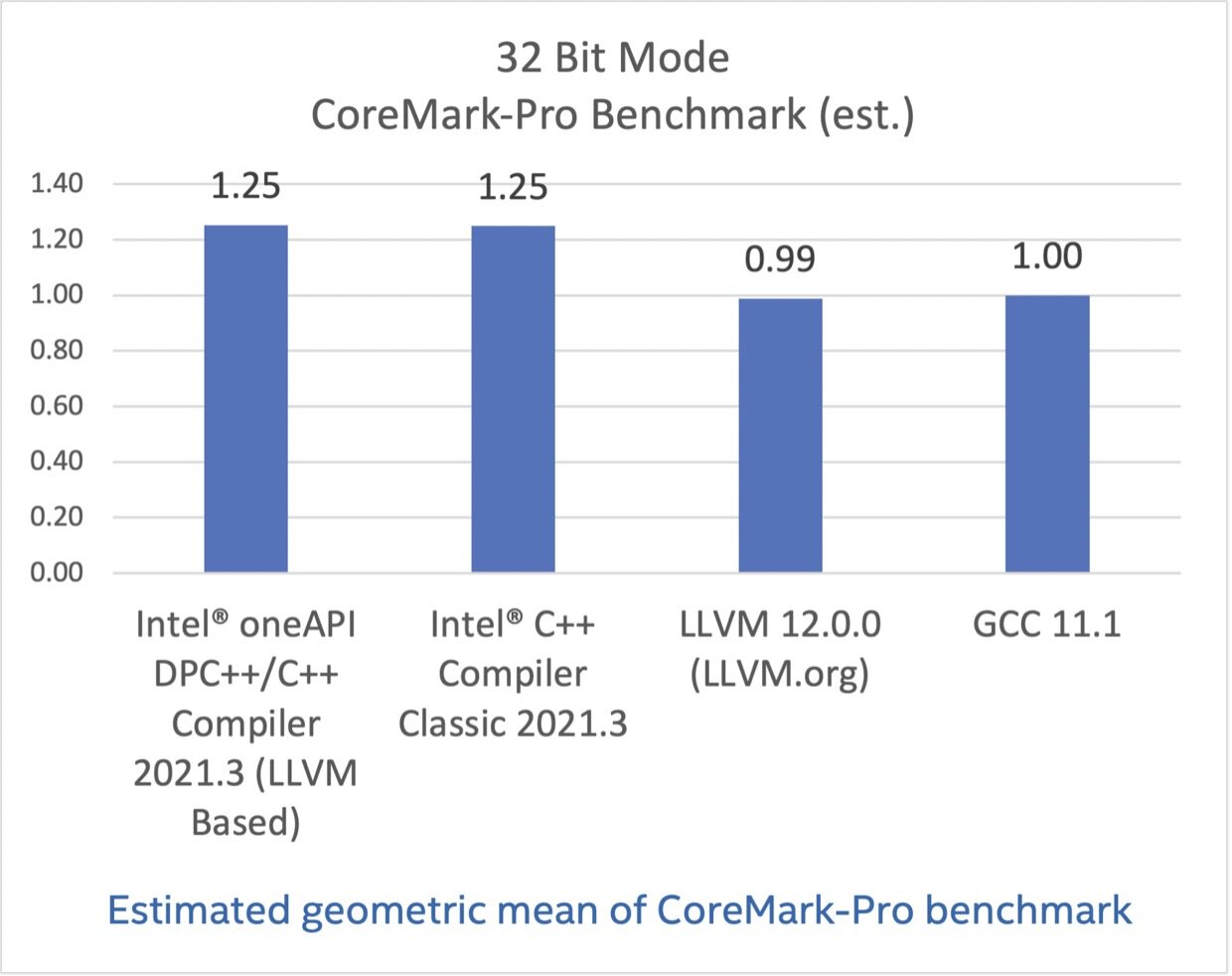
CoreMark-Pro 旨在测试处理器整体表现,其充分支持多核技术,提供了整数和浮点负载组合,并为内存子系统压力测试提供了测试数据集。CoreMark-Pro 来自嵌入式微处理器基准测试集(EEMBC),更多信息可访问这里。
在这些基准测试结果中,英特尔编译器选项都已关闭,但成绩显示基于 LLVM 的英特尔编译器与经典版本还有一些差距。我希望你也能认同这点差距并不算大,毕竟其他结果显示我们的基于 LLVM 的编译器有着优异的表现。
配置:测试由英特尔在 2021 年 6 月 10 日完成。Intel(R) Atom(TM) CPU C3850 @ 2.10GHz, 16G x2 DDR4 2400. 软件:Intel(R) C Intel(R) 64 Compiler Classic for applications running on Intel(R) 64, Version 2021.1 Build 20201112_000000, GCC 11.1, Clang/LLVM 12.0.0. Red Hat Enterprise Linux release 8.0 (Ootpa), 4.18.0-80.el8.x86_64. 编译器开关: Intel(R) C++ Compiler Classic for applications running on Intel(R) 64, Version 2021.1 Build 20201112_000000: icc -xATOM_SSE4.2 -mtune=goldmont -ipo -O3 -no-prec-div -qopt-prefetch. GCC 11.1: gcc -march=native -mfpmath=sse -Ofast -funroll-loops -flto. LLVM 12.0.0: clang -Ofast -funroll-loops -flto -static -mfpmath=sse -march=native.
Lore:用于评估编译器基准测试的循环存储库
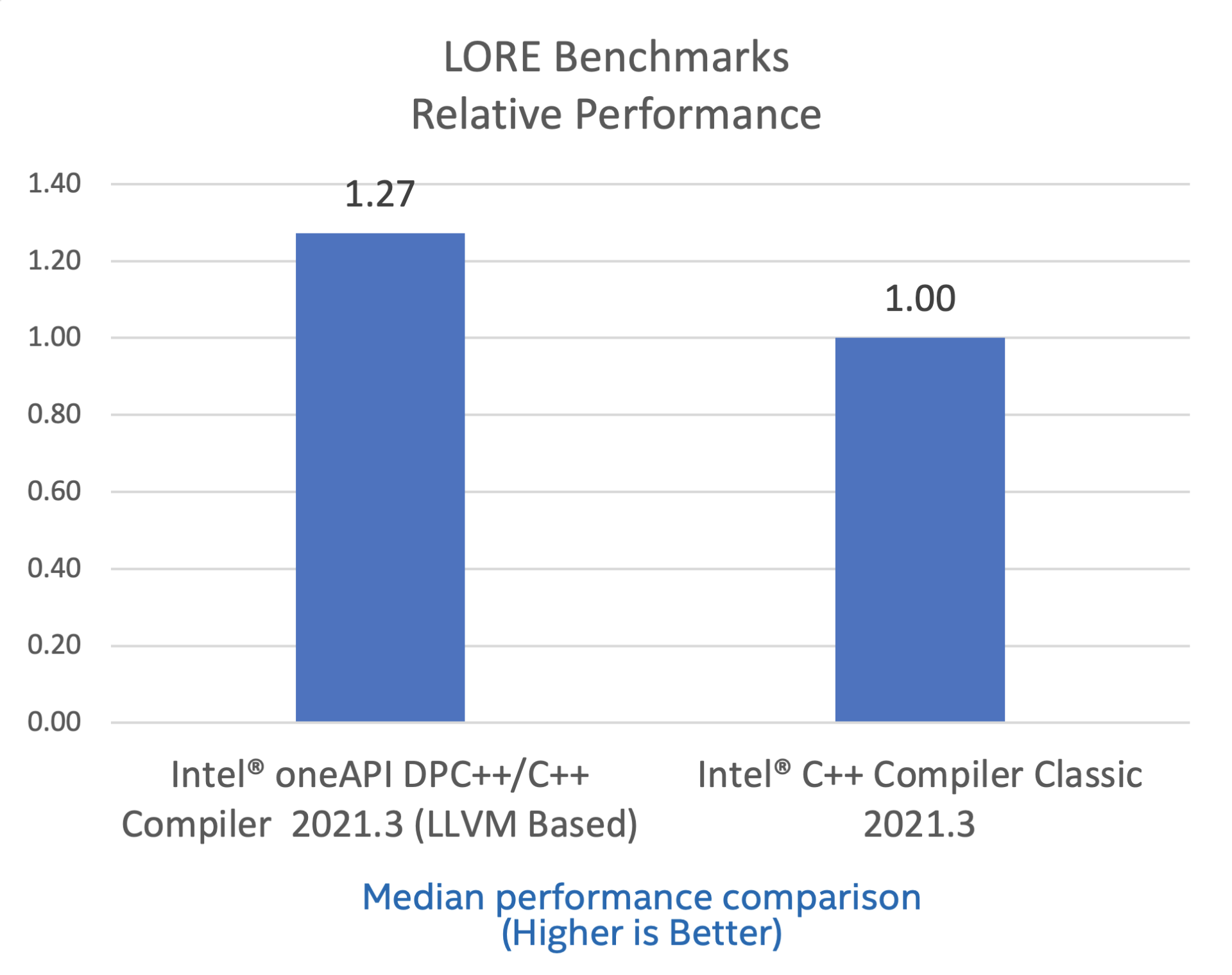
LORE 从流行的基准测试、库和真实应用中提取的循环嵌套来测试 C 语言的性能表现。循环涵盖了各种可以由编译器社区被用来评估循环优化的属性。测试包含了 65 个基准测试和负载。欲了解更多信息,请参见这里。
配置:测试由英特尔在 2021 年 6 月 9 日完成。Intel(R) Xeon(R) Platinum 8180CPU @ 2.50GHz, 2 socket, 28 cores, HT enabled, Turbo enabled, 384GB RAM. 软件:Intel(R) oneAPI DPC++/C++ Compiler for applications running on Intel(R) 64, Version 2021.2.0 Build 20210607, Intel(R) C++ Compiler Classic for applications running on Intel(R) 64, Version 2021.3.0 Build 20210607. Ubuntu 18.04.1 with GCC 10.2.0. 编译器开关: Intel(R) C++ Compiler Classic for applications running on Intel(R) 64, Version 2021.3.0 Build 20210607: ICC OPT - OPT="-Ofast -qopt-prefetch -unroll-aggressive -restrict -xHost -w". ICC OPT512 - OPT="-Ofast -qopt-prefetch -unroll-aggressive -restrict -xHost -w -qopt-zmm-usage=high”. Intel(R) oneAPI DPC++/C++ Compiler for applications running on Intel(R) 64, Version 2021.2.0 Build 20210607: ICX OPT - OPT="-Ofast -qopt-prefetch -unroll-aggressive -restrict -xHost -w". ICX OPT512 - OPT="-Ofast -qopt-prefetch -unroll-aggressive -restrict -xHost -w -mprefer-vector-width=512". ICX OPTm - OPT="-Ofast -qopt-prefetch -unroll-aggressive -restrict -march=skylake-avx512 -w". ICX OPT512m - OPT="-Ofast -qopt-prefetch -unroll-aggressive -restrict -march=skylake-avx512 -w -mprefer-vector-width=512.
RAJA 性能套件(RAJAPerf)
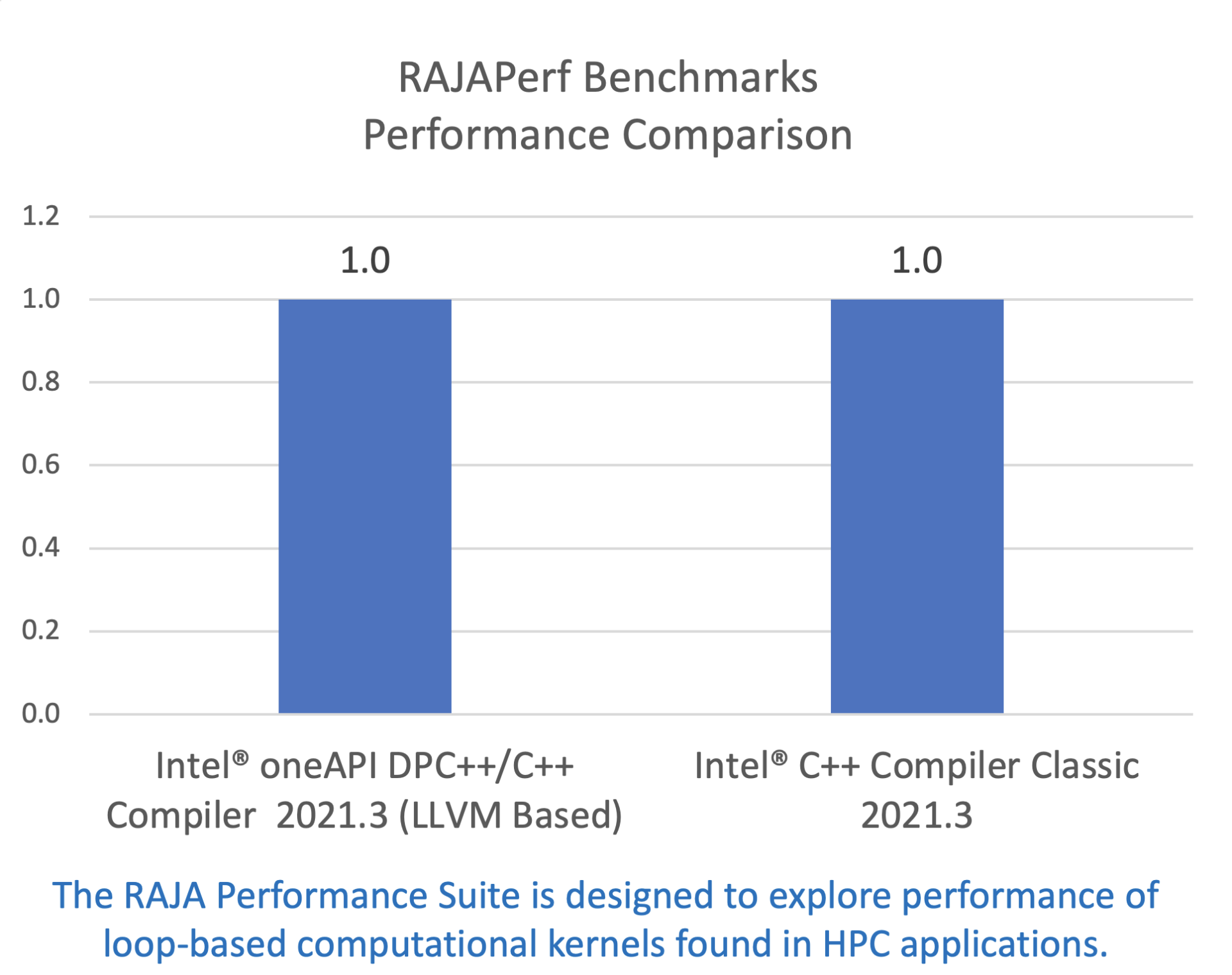
RAJA 性能套件旨在探索 HPC 应用中基于循环的计算内核的性能。这里有更多关于 RAJA 性能套件的信息。
你可能会注意到,这一高压力基准测试中基于 LLVM 的编译器表现与我们的经典版本相当。这样的结果依旧称得上稳健和出色。我之所以毫不犹豫把它加了进来,是因为我们要证明新版本已经完全值得大家选择了。
配置:测试由英特尔在 2021 年 6 月 9 日完成。Intel(R) Xeon(R) Platinum 8180CPU @ 2.50GHz, 2 socket, 28 cores, HT enabled, Turbo enabled, 384GB RAM. 软件:Intel(R) oneAPI DPC++/C++ Compiler for applications running on Intel(R) 64, Version 2021.2.0 Build 20210607, Intel(R) C++ Compiler Classic for applications running on Intel(R) 64, Version 2021.3.0 Build 20210607. Ubuntu 18.04.1 with GCC 10.2.0. 编译器开关: Intel(R) C++ Compiler Classic for applications running on Intel(R) 64, Version 2021.3.0 Build 20210607: ICC OPT OPT="-Ofast -ansi-alias -xCORE-AVX512", ICC OPT512 OPT="-Ofast -ansi-alias -xCORE-AVX512 -qopt-zmm-usage=high", setenv KMP_AFFINITY compact,granularity=fine. Intel(R) oneAPI DPC++/C++ Compiler for applications running on Intel(R) 64, Version 2021.2.0 Build 20210607: ICX OPT OPT="-Ofast -ansi-alias -xCORE-AVX512", ICX OPT512 OPT="-Ofast -ansi-alias -xCORE-AVX512 -qopt-zmm-usage=high", setenv KMP_AFFINITY compact,granularity=fine
性能表现会受使用情况、配置和其它因素的影响。如需了解更多信息,请访问这里。
原文链接:https://software.intel.com/content/www/us/en/develop/blogs/adoption-of-llvm-complete-icx.html

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论