
2024 年 8 月,ByConity 1.0 正式发布,翻开了 ByConity 新的一页。1.0 版本有哪些不同,以及 1.x 版本会重点迭代哪些能力,下面为大家一一解读。
完整的数据仓库能力
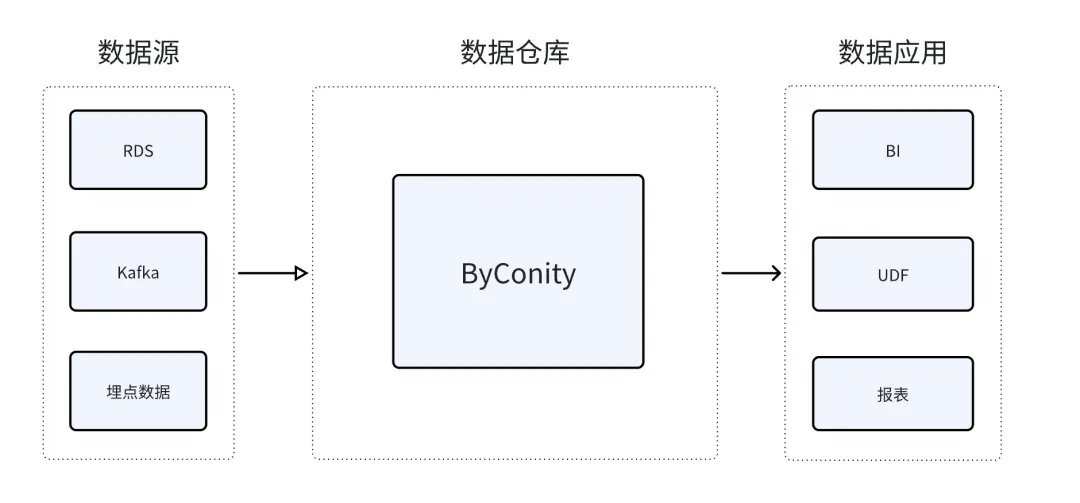
从 ByConity 开源之初,我们一直将产品定位为开源云原生数据仓库。区别于传统 OLAP 产品,ByConity 采用存算分离的云原生架构,通过这种架构获得了弹性和降低资源浪费的优势,但与此同时也在一定程度上提高了产品的复杂度。定位为云原生数据仓库,是希望能够承担更多类型、更复杂的分析任务负载,无论是在线的实时分析还是离线数据的清洗/加工任务都能够胜任。更全面的能力能够帮助用户降低数据分析平台的整体复杂度。
传统的 OLAP 产品通过数据索引、列式存储、向量化执行等技术,注重对实时分析或者 Ad-hoc 分析的快速反应,满足低时延的要求。在数据加载进 OLAP 产品之前,往往需要经过复杂的数据清洗和转换过程,也就是大家熟知的 ETL 任务。在传统的数据分析架构中,这部分工作是由 Hive、Spark、Flink 等产品来完成的。
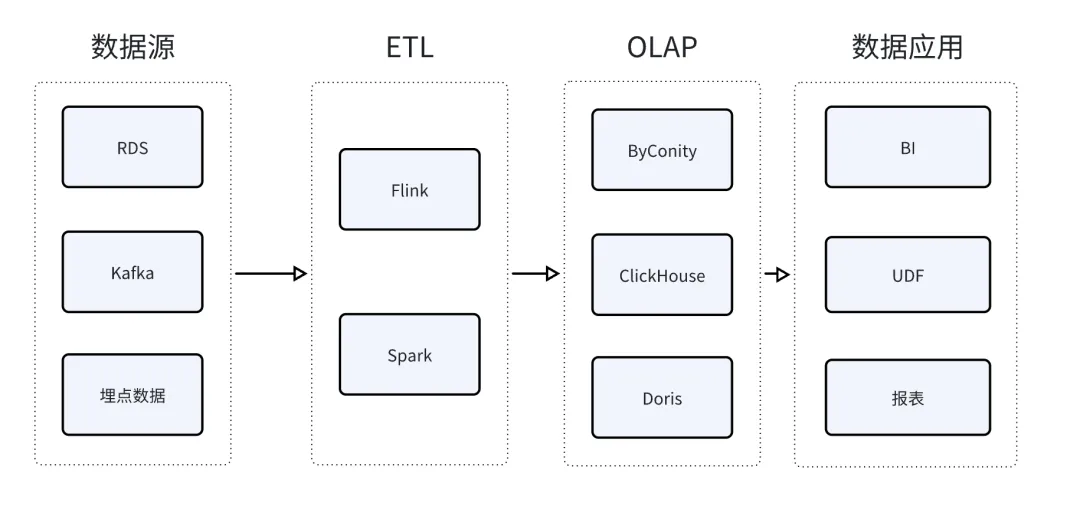
在 ByConity 1.x 版本中,增加了对 BSP 模式的支持,减少数据加工和数据分析之间多系统耦合带来的运维负担,使 ByConity 能够一站式完成数据接入、加工和分析。
1.0 版本中,在 BSP 模式下(settings bsp_mode = 1 打开 bsp 模式)增加了对 TableScan 算子并行度扩展的支持:一、通过设置 distributed_max_parallel_size,可以将 TableScan 的并行度进行扩展,实现资源平铺的功能,在资源有限的情况下实现对大表的处理;二、增加了对 task 重试的支持:通过设置 bsp_max_retry_num(task 的最大重试次数,默认值为 5),可以在作业的中间 task 发生失败时,从失败的 task 开始重试,而不是从头开始重试,进而大大减少 failover 对执行时长的影响。
后续的 1.x 版本中,我们还将推出基于资源感知的 BSP 模式,可以根据集群资源使用情况有序调度并发 ELT 任务,从而减少资源的挤占,避免频繁失败。
湖仓一体
在 ByConity 1.0 版本中的一个重要能力升级就是提升了湖仓一体的能力。ByConity 可以直接分析数据湖中的数据,而无需做数据搬迁,从而让用户可以更灵活的规划其数据分析架构。
Hive 外表查询性能在 1.0 版本中得到了非常大的提升。这主要得益于以下几点:
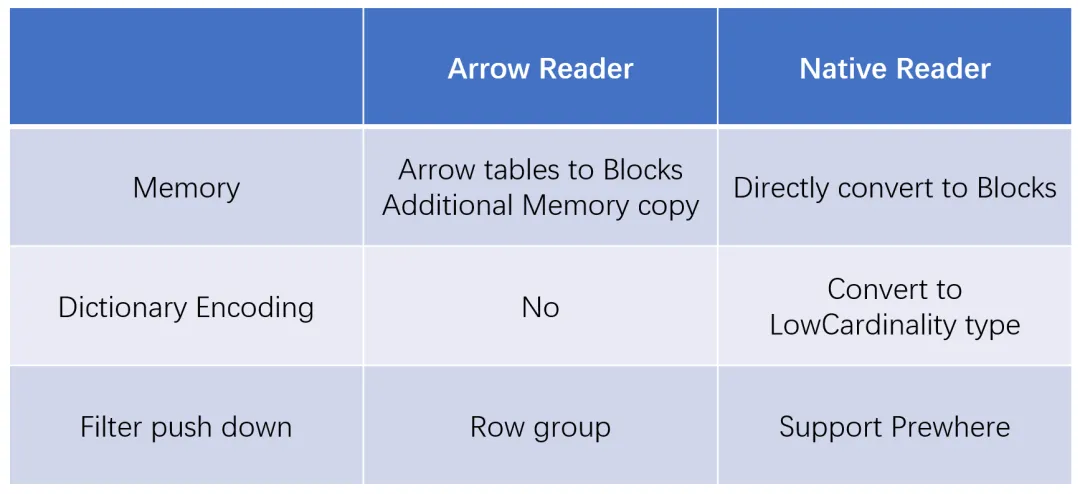
1、实现了外表的 Native Reader(Parquet/Orc),Native Reader 具有以下特点:
2、增加中间结果缓存。
3、结合 ByConity 查询优化器的统计信息自动收集,将 Filter 的有效下推,降低 IO 开销(1.x 版本)。
通过以上能力大大提升了 Hive 外表的查询性能,在 TPC-DS 测试中性能达到 Trino 的 4 倍。
除 Hive 外表外,在 1.0 版本中我们还支持了 Hudi 和 GLUE 的外表查询能力。在后续的 1.x 版本中,我们还将支持 Iceberg 和 Paimon 的外表能力。
MySQL 语义兼容
在 ByConity 0.x 版本中,主要支持 SQL 标准是 ClickHouse SQL 和 Ansi SQL。除 ClickHouse 生态外,MySQL 同样是当前主流的 OLAP 产品生态。过去一年中很多用户反馈从 MySQL 生态产品迁移到 ByConity 过程中有比较复杂的业务改写,以及部分工具不兼容。
在 1.0 版本中,ByConity 已经完成了 90% 以上的语法、函数、数据类型、DQL、DML、DDL 的兼容。此外,如 MySQL Workbench、DBeaver、Navicat 等 IDE 工具,Tableau、QuickBI、FineBI 等主流 BI 工具的兼容性也在当前版本中完成。
在 1.x 版本中,我们希望和社区的贡献者们一起,在存储介质、数据导入、IDE、BI、数据治理工具等方面全面提升 ByConity 广泛的生态工具兼容性。
其他特性
1、默认开启优化器,支持开优化器简单查询走 local 模式,优化了开启优化器后简单查询性能下降的问题。
2、优化 Unique 表的 TableWrite 重试能力,提升 Unique 表可用性。
3、新增 bucket join 相关的能力。
4、提升 map 函数性能。
5、优化 disk cache 加载策略,支持按比例配置。
6、string 数据类型转化为 map,支持 nullable string。
7、支持导出数据导文件目录,支持 Worker 导出数据。
8、支持表级别的快照能力。
9、(Preview)增强高并发点查性能。
展望
未来,我们还将持续为提升分析性能和打造全面的数仓能力而努力。除此之外,我们还将向一体化分析引擎的方向进行探索,继续打磨倒排索引的能力,以及向向量检索和时空分析等场景进行探索。
ByConity 1.0 完整 Changelog:
https://github.com/ByConity/ByConity/releases/tag/1.0.0
关于 ByConity
ByConity 是字节跳动开源的云原生数据仓库,在满足数仓用户对资源弹性扩缩容,读写分离,资源隔离,数据强一致性等多种需求的同时,提供优异的查询,写入性能。




