我们改进 Netflix 推荐系统的目标在于打造个性化观赏体验,让会员更容易地找到喜欢的内容。对于这套推荐系统,我们希望最终能够精确判断出会员最想看的内容,并在他们打开 Netflix 后立刻开始播放。虽然距离这样的目标还有一段距离,但我们已经取得了不菲的成绩。
当会员打开 Netflix 网站或应用后,他可能希望找一些从没看过的新电影或电视剧,或者可能希望继续观看以前没看完的内容。如果我们能更合理地预测会员是否希望通过“续看”模式继续观看没看完的内容,就可以将这些内容放在首页上更显眼的位置。
虽然与内容推荐有关的大部分工作主要侧重于内容本身的交付,但本文中我们将着重介绍“续看模式”,并介绍我们如何通过机器学习技术改善不同模式下会员观看体验的。尤其是将介绍大部分平台上 Netflix 会员打开首页后出现在页面最主要位置的“续看”(Continue Watching,CW)区域。会员可以通过该区域更轻松地找到最近看过(但尚未看完),并希望继续观看的内容。你可能已经想到了,我们的会员大部分时间所观看的内容都是通过该区域播放的。
续看
以前某些平台上的 Netflix 应用会用一个区域显示最近观看过的内容(此处所谓的“内容”泛指 Netflix 提供的所有形式的内容,包括电影和电视剧等),这里的内容按照最后播放时间为顺序进行排序。页面上该区域内容的显示方式取决于与所用播放设备类型有关的规则。例如,网站只在页面左上角显示一部可以续看的内容。这些决定都出于一些比较合理的基准,设置这样的基准是为了对不同平台的 CW 体验进行统一,并通过下列两个维度进行改进:
- 改善该区域内容在页面上的放置:如果会员更有可能希望继续观看某个节目(续看模式),就将其放在更醒目的位置;如果会员更有可能观看新内容(发现模式),就将其放在不那么醒目的位置。
- 改善该区域中最近观看过内容的排序:根据当前会话中每个内容可能被续看的可能性进行调整。
从直觉方面考虑,会员的很多行为模式代表着他可能希望采用续看模式,例如:
- 正处于“追剧模式”中,例如最近用了大量时间观看某部电视剧,同时该剧还没看完
- 最近刚看了一部电影但还没看完
- 总在每天的这个时间,或总在当前设备上观看内容
另一方面,如果会员有如下行为,很可能代表他希望查找新的内容来看:
- 刚刚看完某部电影,或某部电视剧的所有剧集
- 最近什么都没看过
- 新注册了我们的服务
这些猜测以及会员在续看模式下度过的大量时间激励着我们开发机器学习模型,通过识别和利用这些行为模式打造更精确的 CW 区域。
为续看行为构建推荐模型
为了给 CW 区域构建推荐模型,首先需要计算一系列特征,从会员行为中发现可能存在的模式,借此才能让模型预测用户什么时候希望续看。需要考虑的特征包括会员信息,CW 区域显示的内容,会员以往与这些内容的交互,以及其他上下文信息。随后我们使用这些特征作为输入内容,借此构建机器学习模型。通过变量的选择、模型的训练,以及交叉验证等过程进行迭代,我们将能进一步提炼并选择最相关的特征。
构建 CW 模型的过程中,在对各种特征进行集思广益时我们考虑过很多想法,包括:
A. 会员级别的特性:
- 有关会员订阅的数据,例如订阅时长、注册所在国、语言首选项
- 会员最近的活跃度
- 会员过去的评分和内容类型的喜好
B. 节目特征信息以及会员与节目的交互情况:
- 节目是什么时候发布到某一分类中,或被会员观看的
- 会员观看过多少电影 / 电视
- 有关节目的元数据,例如类型、流派、剧集数量,例如儿童节目被重看的概率往往更高
- 该分类下可供会员观看的其他内容
- 节目对会员的流行度和相关性
- 会员继续看该节目的频率
C. 上下文特征:
- 当前时间和星期数
- 位置和各种分辨率
- 会员所用设备
两个应用程序,两个模型
如上所述,在优化会员续看剧集的过程中有两个任务:对 CW 区域的内容进行排名,并将 CW 区域放在会员首页的恰当位置。
内容排名
为了对该区域的内容排名,我们训练了一个可以针对排名损失函数进行优化的模型。训练模型的过程中,我们从一组随机会员中挑选出包含未看完内容,通过续看模式继续观看的会话,即续看会话。在每个会话中,模型会学习区分可能被续看的目标内容,并根据预测的续看可能性对其进行排名。在构建该模型时,我们通过一个特殊权重让模型将实际被续播的内容放在第一位。
我们还通过脱机评估的方式进一步了解了模型排名在 CW 区域展示后的实际效果。这一过程中使用以往的系统作为比较的基准,以往系统中只是简单地按照每个内容的最后播放时间对所有内容进行排序。这种新近性排名(Recency rank)是一种很强大的基准(远远好过随机排名),也被作为一个特性包含在我们新建的模型中。通过对模型结果和新近性排名结果进行比较,我们发现各种脱机指标都有显著提升。下图展示了两种方式在一段时间内精确度为 1 时的结果。从图中可见,相比逐日变动,具体效果有了很大提升。
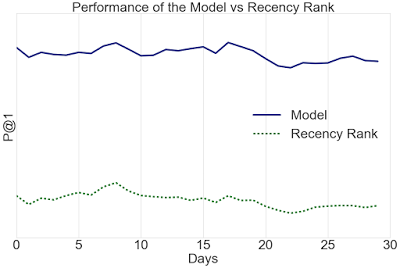
在 B/A 测试中,该模型的效果远好于基于新近度的排名,与针对会员行为的预期也更为匹配。例如我们从中发现,CW 区域使用新模型提供排名后,会员从搜索页面播放内容的情况大为减少。这意味着很多会员曾经因为无法轻松地在首页上找到最近观看过的内容,而不得已通过搜索功能查找,新模型也有助于改善这方面的用户体验。
CW 区域的放置
为了将 CW 区域放在成员首页最恰当的位置,我们还希望预测会员希望使用续看模式或发现模式的可能性,并针对不同可能性采取不同的方法。一种简单的方法是将该区域的放置变成一种二元决策问题,只需要为 CW 区域的位置考虑两种可能:页面上最醒目的位置,或页面上不那么醒目的位置。通过对预测出的续看可能性应用一个阈值,我们可以决定要将 CW 区域放在两个位置中的哪一个。该阈值还可通过一些更精确的指标进行优化。另一种方法则是将可能性直接对应为不同的位置,例如可以根据内容在页面上的位置进行决定。在任何情况下,都需要准确预测续看的可能性,这也是确定 CW 区域放置情况的关键。下文将介绍两种预测会员是否选择续看模式的方法。
继续使用内容排名模型
为了预测续看模式和发现模式的可能性,一种简单的方法是继续使用内容排名模型预测的分数。更具体来说,可以对特定内容的分数进行校准,借此估算特定会话中每个内容被续看的概率 P(play(s)=1)。可以使用 CW 区域内所有内容的可能性数据得出续看的整体可能性,例如 CW 区域至少有一个内容有可能被续看。举例来说,在一个不同内容均相互独立的简单假设下,我们可以将 CW 区域至少一个内容将被观看的可能性表示为:
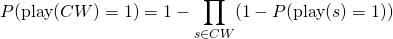
该区域专用的模型
在这个方法中,我们训练了一个二元分类器,借此将续看会话标记为正向标签,并将用户首次观看某个节目的会话(发现会话)标记为负向标签。这一模型可能用到的特性包括会员级别和上下文特性,以及观看历史记录中包含的会员与最近观看过内容进行的交互。
对比这两种方法,第一种方法更简单,因为只需要一个模型,但前提是需要对概率进行妥善校准。然而第二种方法能对续看模式提供更精确的预测,因为可以专门为这一目的训练一个分类器。
放置结果的调优
我们在实验中使用分类指标对续看概率的估算进行了评估,并在脱机指标方面获得了不错的成果。然而依然面临一个挑战:需要对估算的概率提供更优化的映射,例如要在续看和发现模式之间进行权衡。在本例中,不同的放置方式导致预测结果要在两种类型的错误中进行取舍:假正向(错误地预测为会员希望从 CW 区域续看内容)和假负向(错误地预测为会员希望发现新的内容)。这两类错误会对会员产生不同的影响。尤其是假负向使得会员更加难以续看节目。虽然有经验的会员可以滚动页面或使用搜索功能找到自己要看的内容,但这会对新用户造成一定的难度。另一方面,假正向会浪费宝贵的屏幕空间,而这些空间本应可以用来显示与会员更相关的新内容推荐。考虑到这两种类型错误对会员体验的影响难以通过脱机的方式精确评估,我们对不同放置方式进行了 A/B 测试,借此通过在线实验的方式进一步了解了该如何为会员提供最有吸引力的内容。
上下文感知
我们的另一个假设是:续看行为取决于具体的上下文:时间、位置、设备等。如果是这种情况,对于特定的特性,训练后的模型应当能检测出这些模式并结合会员的当前上下文适应预测出的节目续看概率。例如,会员可能习惯于在每天某个固定时间观看特定内容(例如周内每天晚十点看喜剧片)。
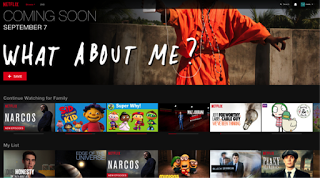
举一个有关上下文感知的例子,下列屏幕截图演示了该模型如何通过上下文特性区分会员在不同设备上截然不同的行为。本例中的这个会员刚在 iPhone 上看了几分钟的“科学小子西德(Sid the Science Kid)”,并在 Netflix 网站看了“毒枭(Narcos)”。作为对这种行为的回应,CW 模型立刻将“科学小子西德”排名放在了 iPhone 上 CW 区域的首位,并将“毒枭”放在了网站上的首位。
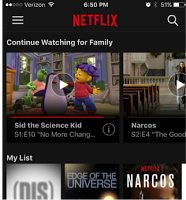
CW 区域内容的提供
会员都希望 CW 区域的内容能在自己观看节目之后立刻做出响应并动态调整。更重要的是,模型中的一些特性是依赖于特定时间或具体设备的,无法预先计算出来,而这种方法也被我们用在其他推荐系统中。因此需要实时计算出CW 区域的内容,以确保用户使用服务时请求主页后可以看到最新鲜的内容。为保证内容的新鲜,还要在用户在会话中进行某些交互之后对其进行更新,并将更新立刻推送至客户端并更新到用户的主页上。以我们的规模来说,通过计时计算获得CW 区域的内容,这本身也是一个挑战,需要进行妥善的设计。例如对拥有很长观看历史的用户来说,一些特性的计算开销非常大,但我们需要对所有会员实现合理的响应时间,因为续看是一种十分常见的场景。为了应对这一挑战,我们已经与多个工程团队展开协作,通过更为动态、可缩放的方式提供CW 区域的内容。
结论
更贴心的续看区域无疑可以让我们的会员更轻松地随时继续欣赏自己喜爱的节目,同时可以帮助他们更方便地发现感兴趣的新内容。虽然在改善这一体验的过程中我们已经取得了一定的成果,但依然有很大的改进空间。例如我们正面临这样一个挑战:希望通过统一的方式对CW 区域以及首页上的其他区域提供内容,并希望更加侧重于新内容的发现。这一点很难实现,因为不同意图需要用到不同的算法,需要通过某种方式进行权衡。此外我们还希望对CW 内容数量更为慎重,希望大家“更理智地追剧”,同时也别忘了浏览各种新的内容。另外还有很多细节有待挖掘,例如,如何确定用户已经不再想继续看某个节目,以便将其从CW 区域中删除。不同场景下这一目标其实很难实现,例如用户是否虽然关了电视机但播放器还开着,或者观看过程中已经睡着了。此外我们还希望这套CW 模型可以在产品中发挥出其他新的用途。
作者: Hossein Taghavi 、 Ashok Chandrashekar 、 Linas Baltrunas ,以及 Justin Basilico ,阅读英文原文: To Be Continued: Helping you find shows to continue watching on Netflix
感谢陈兴璐对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




