
Netflix 已经拥有了超过 83000000 名遍布全球的会员,他们使用着数千个多样的微服务。这些服务由多个团队分别负责,每个服务有自己的构建和发布周期,服务产生的复杂多样的数据被存储在不同类型的数据存储系统中。云数据工程团队(CDE)负责管理数据存储系统,他们通过运行基准测试来验证这些系统的更新、进行容量规划,还会在不同的失败场景下和多种工作负载下测试我们的云实例。我们希望有这样一个工具,它可以评估和比较在市场上或开源领域出现的新的数据存储系统的性能特征和缺陷,可以预估它们是否可以用在相关的产品中。有了以上需求,创作了 Netflix Data Benchmark (NDBench),一个用于各种数据存储系统的可插拔云端基准测试工具。NDBench 为我们使用的各种主要的数据存储系统提供了插件支持,包括 Cassandra(Thrift 和 CQL)、Dynomite(Redis)和 Elasticsearch。它也可以被扩展连接其他客户端的 API。
简介
由于 Netflix 运行着数以千计的微服务,工程师并不是总能感知到在我们的后端系统中捆绑的微服务可能产生的流量。了解后端系统中的新的微服务的潜在性能同样是个困难的任务。所以我们需要一个框架,它可以协助工程师,在不同的工作负载、维护操作和示例类型的情形下帮助我们决定数据存储系统的行为。我们想要在不同的工作负载和在一些例如节点失败、网络分区等的情况下及时地动态配置它们、横向(通过添加节点)或纵向(通过更新实例的类型)地动态扩展它们和操作它们。
如今,出现在市场上的新的数据存储系统,趋向于只是基于经过优化的硬件和基准测试配置来报告“好看的”的性能数字。作为一个云原生的数据团队,希望能够确认我们的系统可以在多种故障场景中提供高可用的服务,同时做到以最佳方式使用实例资源。有很多其他因素会影响部署在云端的数据库的性能,例如实例的类型、负载模式和部署的类型(孤立和全局)。NDBench 可以通过模拟性能基准测试来提供帮助,原理是通过模仿数个生产用例。
还有一些额外的需求,例如,由于升级了数据存储系统(比如升级 Cassandra),团队希望在部署系统到生产环境之前进行一次系统测试。对于那些开发的内部系统,例如 Dynomite ,我们希望功能测试流程能够自动化,在多种条件和不同存储引擎下了解 Dynomite 的性能。因此,我们需要一个可以集成到之前的流水线的负载生成器来将 AWS AMI 转变为一个生产完备的 AMI。
在调研了各种基准测试工具之后,包括基于 REST 的性能工具,我们发现一些工具只是拥有我们需求的子集,对达到以下目标的工具有兴趣:
- 在测试过程中动态调整基准测试配置,这样才能和我们的生产环境的微服务一起进行测试。
- 集成到平台云服务,例如动态配置、发现、权值等等。
- 运行无限时长,这样才能引入故障场景来测试长时间运行的维护,例如数据库维修。
- 提供插拔模式和负载,
- 支持不同客户端的 API。
- 从单一入口部署、管理和监控多个实例。
基于以上这些原因,Netflix 创造了 Netflix Data Benchmar(NDBench)。我们将 NDBench 引入到了 Netflix 的开源生态系统中,将它集成到了一些组件中,例如作为配置工具的 Archaius 、用来度量指标的 Spectator 和作为发现服务的 Eureka 。
NDBench 的架构
下面的图表展示了 NDBench 的架构。主要由三个组件构成:
- Core:负载生成器
- API:允许基于 NDBench 开发多种插件
- WEB:UI 和 servlet 上下文监听器
目前为止,NDBench 提供了如下几种客户端插件—— Datastax Java Driver (CQL)、 C* Astyanax (Thrift)、Elasticsearch API 和 Dyno (Jedis support)。 也可添加其他插件,或者用户可以使用如 Groovy 这样的动态语言来添加新的工作负载。每个驱动都是一个驱动插件接口的实现。
NDBench-Core 是 NDBench 的核心组件,用户可以通过它调整负载设置。
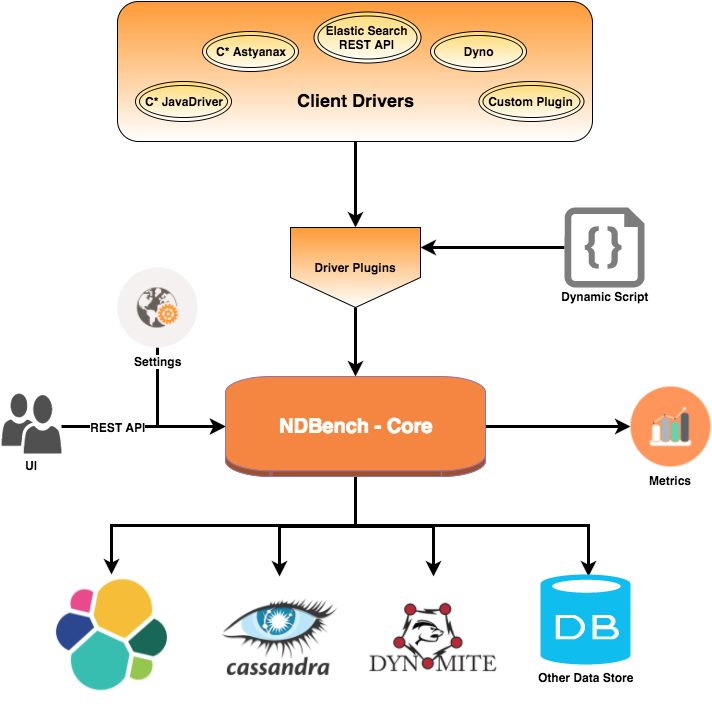
图 1:NDBench 架构
NDBench 可以通过命令行(使用 REST 调用)或基于 WEB 的 UI 来操作。
NDBench Runner UI
(点击放大图像)

图2:NDBench Runner UI
图2 是 NDBench Runner UI 的截图。通过这个 UI,用户可以选择集群、连接驱动、修改设置、设置一个负载测试模式(随机或滑动窗口),然后运行负载测试。在负载测试运行时选择一个实例,用户同样可以看到实时更新的数据统计,例如读写延迟、每秒请求数、缓存命中率等等。
负载参数
NDBench 提供了大量输入参数,它们会被动态加载并可以在工作负载测试运行中动态修改。下列参数可以基于每个节点进行配置:
- numKeys:用于存储随机生成键的样本空间
- numValues:用于存储随机生成值的样本空间
- dataSize: 每个值的大小
- numWriters/numReaders:每个 NDBench 节点的写 / 读线程数
- writeRateLimit/readRateLimit:每秒写 / 读数
- userVariableDataSize:控制开关随机生成负载功能的布尔值
工作负载的类型
NDBench 能够进行可插拔的负载测试。目前它有两种模式——随机流量和滑动窗口流量。滑动窗口测试是一个更加精细的测试,它可以并发地使用在窗口中的重复数据,从而提供时间本地数据和空间本地数据的组合数据。尤其是当我们想要同时测试数据存储系统提供的缓存层和磁盘的 IOPS(每秒输入 / 输出操作数)时,它非常重要。
负载的生成
可以单独为应用的每个节点生成负载,也可以同时为所有节点生成读写操作。更妙的是,NDBench 提供了使用“回填”特性的能力,因此我们可以使用热数据才启动负载测试。这帮我们减少了基准测试的爬升时间。
Netflix 使用 NDBench
NDBench 在 Netflix 内部已经被广泛使用了。在接下来的一节里,我们来讨论下能够证明 NDBench 是个有用的工具的用例。
基准测试工具
几个月前,我们将 Cassandra 从 2.0 迁移到了 2.1。迁移之前,我们想要知道能将性能提升多少,在升级我们的 Cassandra 实例期间性能会下降到什么地步。图 3 和图 4 展示了 p99 和 p95 使用了 NDBench 前后读操作延迟的变化。在图 3 中,我们高亮显示了 Cassandra 2.0(蓝色线条) 和 2.1(棕色线条) 不同的部分。
(点击放大图像)

图3:记录 Cassandra 的 OPS 和 延迟百分比
去年,我们将 Cassandra 实例从老旧的 Red Hat 5.10 操作系统迁移到了 Ubuntu 14.04(值得信赖的塔尔羊)。我们使用 NDBench 来在新操作系统中测试性能。在图 4 中,我们使用了 NDBench 的长时间运行基准测试的能力展示了迁移过程的三个阶段。用 Cassandra 实例的滚动终端在新的操作系统中更新 AMI,使用 NDBench 来验证在迁移期间不会受到客户端的影响。NDBench 同时也允许我们验证了迁移后的新系统性能更好。
(点击放大图像)

* 图 4:从 Red Hat 5.10 升级到 Ubuntu 14.04 后的性能提升
AMI 认证过程
NDBench 同时也是 Netflix 的 AMI 认证过程的一部分,AMI 认证包括集成测试和部署验证。团队使用 SPinnaker 设计了流程,并将 NDBench 集成到其中。下图展示了 bakery-to-release 的生命周期。开始时我们使用 Cassandra 烘焙了一个 AMI,创建了一个 Cassandra 集群,创建了一个 NDBench 集群,进行配置,启动一个性能测试。最后我们检查了结果,做出了需不需要将“实验性”的 AMI 提升为“候选者”的决定。对于 Dynomite,团队使用了相同的流程,使用不同的客户端 API 测试了重复功能。通过 NDBench 性能测试意味着 AMI 已经可以在生产环境中使用了。类似的流程在 Netflix 的其他的数据存储系统中也被采用。
(点击放大图像)

图5:NDBench 与 Spinnaker 流水线集成
过去,Netflix 团队发布了使用 Dynomite 的基准测试,这个测试利用 Redis 作为存储引擎,由 NDBench 完成。在图 6 中,展示了从 Dynomite 的 NDBench 测试中获得的一些高延迟百分比。
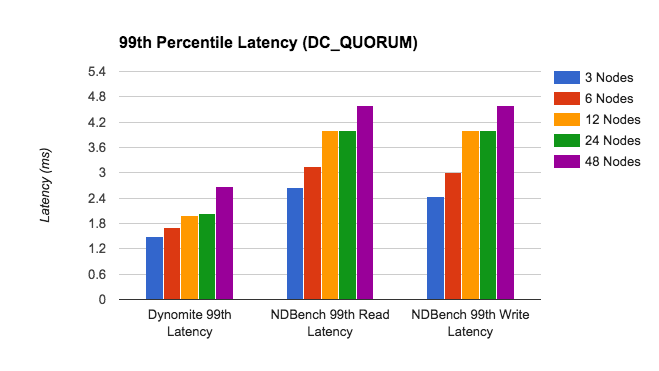
图6:NDBench 的一致性设置为 DC_QUORUM 时 Dynomite P99 延迟
NDBench 允许工程师进行无限期测试来识别内部开发的长时间运行应用可能存在的内存泄漏。同时,在集成测试中,我们引入了错误条件,改变系统中的基本参数,引入了 CPU 密集运算(比如修正 / 和解),和确定了基于应用需求的最优性能。最后,Netflix 的其他应用例如 Priam 、 Dynomite-manager 和 Raigad 进行了各种各样的操作,例如多线程备份到对象存储系统。我们想要确认,通过集成测试,数据存储系统的性能不会受到影响。
结论
在过去几年中,和 AMI 验证一样,NDBench 在功能测试、集成测试和性能测试中被广泛使用。在测试过程中改变负载模式的能力、支持不同客户端的 API 和与我们的云部署进行集成在验证我们的数据存储系统的过程中极大地帮助了我们。将来我们希望 NDBench 在几个方面有提升,这样既能提高可用性也能支持其他特性。我们将会去实现的几个特性包括:
- 性能报告管理
- 自动 cannary 分析
- 基于目的地模式的动态负载生成
在 Netflix 的云数据库工程团队中,NDBench 已经被证明了非常有用,Netflix 也很高兴能有机会分享其中的价值。因此,Netflix 开源了 NDBench 项目,并希望能够收到来自开源社区的反馈、想法和贡献。你可以在 GitHub 中找到 NDBench: https://github.com/Netflix/ndbench 。
查看英文原文: Netflix Data Benchmark: Benchmarking Cloud Data Stores 。
感谢 陈兴璐对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。
活动推荐:
2023年9月3-5日,「QCon全球软件开发大会·北京站」 将在北京•富力万丽酒店举办。此次大会以「启航·AIGC软件工程变革」为主题,策划了大前端融合提效、大模型应用落地、面向 AI 的存储、AIGC 浪潮下的研发效能提升、LLMOps、异构算力、微服务架构治理、业务安全技术、构建未来软件的编程语言、FinOps 等近30个精彩专题。咨询购票可联系票务经理 18514549229(微信同手机号)。

暂无签名

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论