
编者按:Maglev 是谷歌为自己的数据中心研发的解决方案,并于 2008 开始用于生产环境。在第十三届网络系统设计与实现 USENIX 研讨会( NSDI ‘16 )上, 来自谷歌、加州大学洛杉矶分校、 SpaceX 公司的工程师们分享了这一商用服务器负载均衡器Maglev 的详细信息。Maglev 安装后不需要预热5 秒内就能应付每秒100 万次请求令人惊叹不已。在谷歌的性能基准测试中,Maglev 实例运行在一个8 核CPU 下,网络吞吐率上限为12M PPS(数据包每秒),如果Maglev 使用Linux 内核网络堆栈则速度会小于4M PPS。无独有偶,国内云服务商UCloud 进一步迭代了负载均衡产品——Vortex,成功地提升了单机性能。在技术实现上,UCloud Vortex 与Google Maglev 颇为相似。以一台普通性价比的x86 1U 服务器为例,Vortex 可以实现吞吐量达14M PPS(10G, 64 字节线速),新建连接200k CPS 以上,并发连接数达到3000 万、10G 线速的转发。在本文中,UCloud 网络研发团队分享UCloud Vortex 的具体实现。
什么是负载均衡
一台服务器的处理能力,主要受限于服务器自身的可扩展硬件能力。所以,在需要处理大量用户请求的时候,通常都会引入负载均衡器,将多台普通服务器组成一个系统,来完成高并发的请求处理任务。
最早的负载均衡技术是通过DNS 来实现的,将多台服务器配置为相同的域名,使不同客户端在进行域名解析时,从这一组服务器中的请求随机分发到不同的服务器地址,从而达到负载均衡的目的。
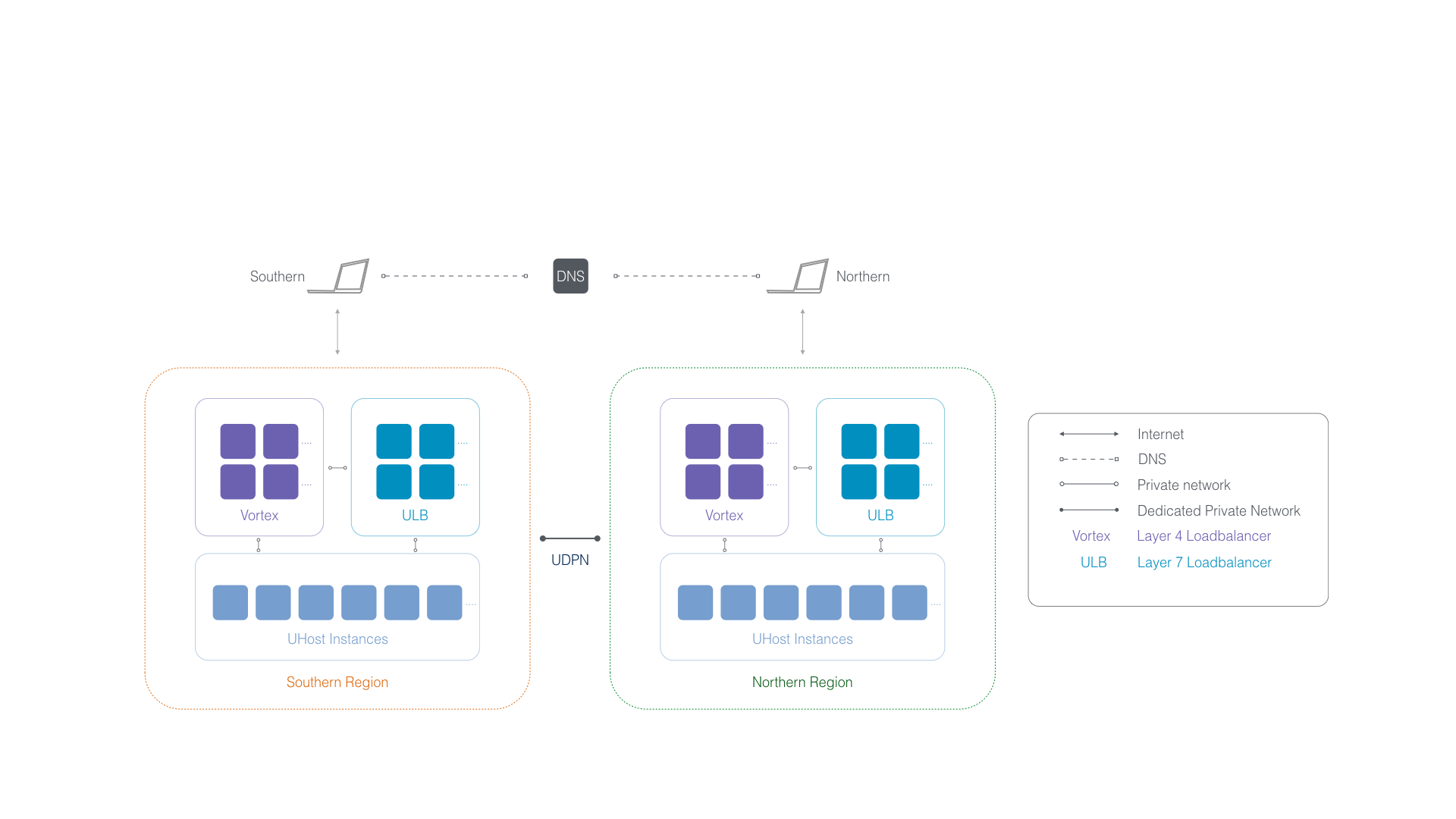
图:多层次负载均衡
但在使用DNS 均衡负载时,由于DNS 数据刷新的延迟问题,无法确保用户请求的完全均衡。而且,一旦其中某台服务器出现故障,即使修改了DNS 配置,仍然需要等到新的配置生效后,故障服务器才不会被用户访问到。目前,DNS 负载均衡仍在大量使用,但多用于实现“多地就近接入”的应用场景。
1996 年之后,出现了新的网络负载均衡技术。通过设置虚拟服务地址 (IP),将位于同一地域 (Region) 的多台服务器虚拟成一个高性能、高可用的应用服务池;再根据应用指定的方式,将来自客户端的网络请求分发到服务器池中。网络负载均衡会检查服务器池中后端服务器的健康状态,自动隔离异常状态的后端服务器,从而解决了单台后端服务器的单点问题,同时提高了应用的整体服务能力。
网络负载均衡主要有硬件与软件两种实现方式。主流负载均衡解决方案中,硬件厂商以 F5 为代表,软件主要为 Nginx 与 LVS。但是,无论硬件或软件实现,都逃不出基于四层交互技术的“报文转发”或基于七层协议的“请求代理”这两种方式。四层的转发模式通常性能会更好,但七层的代理模式可以根据更多的信息做到更智能地分发流量。一般大规模应用中,这两种方式会同时存在。
为什么要研发 Vortex?
在研发 UCloud Vortex 之前,我们一直在思考是不是在重造轮子。这要求我们站在 2016 年这个时间点上去分析现状,深入思考各种负载均衡实现的优、劣势。负载均衡大致可分为以 F5、Netscaler 为代表的硬件负载均衡和以 LVS 为代表的软件负载均衡。
不妨,我们先以 F5 为代表来看硬件负载均衡的优劣势。
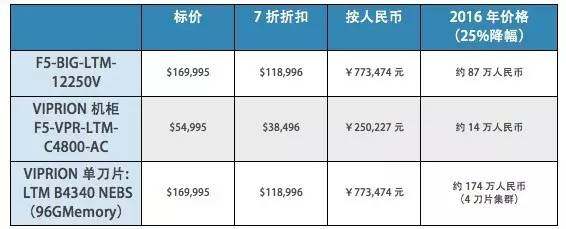
F5 的硬件负载均衡产品又分单机和集群系列。12250v 是单机中的高端版本,能支撑每秒 150 万新建连接数,8000 万并发连接数,84G 数据吞吐量。从 F5 的 datasheet 中,我们推算出并发连接数受限于内存,高端的 12250v 和次一级的 11050 内存相差 4 倍,并发连接数也是 4 比 1 的关系,后者大概为 2400 万;根据 UCloud 自身云平台的运营经验,150 万新建连接在特定大压力场景下是非常危险的,很有可能被击穿;而 84G 的吞吐量,一般来说是够用的,数据中心南北向的流量有限。

图:F5 12250v
集群系列中 VIPRION 4800 阵列是旗舰产品,每个阵列支持最多 8 个 Blade,每个 Blade 提供每秒 290 万新建连接数,1.8 亿并发连接数以及 140G 数据吞吐量。按线性比例计算,一个顶配的 VIPRION 4800 阵列能满足绝大多数海量互联网应用的业务需求了。其中,需要指出的是单片 Blade 都是用了普通 X86 架构,2 块英特尔 12 核 CPU 配 256G 内存,这个转变使其支撑量产生了飞越,也进一步证实并发连接数与内存呈相关性。
从技术角度来说,我们认为硬件负载均衡最终的路线是回到 X86 服务器架构,通过横向扩展来提升性能。这里软硬件的区分已经不再存在,因为如果 F5 能做到,具备深入研发能力的技术公司如 Google、Facebook 也能逼近甚至超越。
从商业角度来说,硬件负载均衡产品过于昂贵,高端产品动辄几十万甚至数百万的价格对于用户是几乎不可承受的负担。在文章末尾,我们提供了一份根据网上数据整理后的比较内容,主要来源为 Google 搜索:F5 Networks - Price List - January 11th, 2014 - Amended for the WSCA-NASPO JP14001 Request for Proposal,供大家参考。
从使用角度来说,硬件负载均衡是黑盒,有 BUG 需要联系厂商等待解决,时间不可控、新特性迭代缓慢且需资深人员维护升级,也是变相增加昂贵的人力成本。
再来看 (开源) 软件负载均衡代表 LVS
LVS 作为目前互联网时代最知名的负载均衡软件,在性能与成本方面结合地很好,阿里云的 SLB 产品也通过 LVS 实现,因此也继承了 LVS 的优点和缺点。LVS 最常用的有 NAT、DR 以及新的 FULL NAT 模式。以下是各模式详细的优缺点比较:
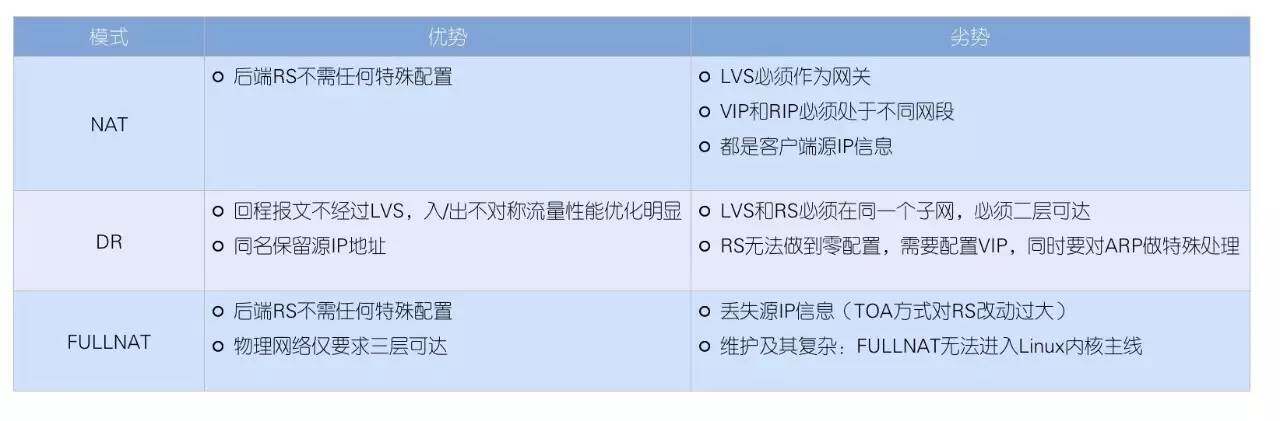
图:NAT、DR 和 FULL NAT 模式优缺点对比
我们认为 LVS 的每种模式都有较大的缺点,但这并不是最为致命的。最为致命的是 LVS 本质上是一个工作于 Linux 内核层的负载均衡器,它的上限取决于 Linux 内核的网络性能,但 Linux 内核的网络路径过长导致了大量开销,使得 LVS 单机性能较低。因此,Google 于 2016 年 3 月最新公布的负载均衡 Maglev 实现完全绕过了 Linux 内核 (Kernel Bypass),也就是说 Google 已经采用了与 LVS 不同的技术思路。
LVS 在运维层面还要考虑容灾的问题,大多使用 Keepalived 完成主备模式的容灾。有 3 个主要缺点:
- 主备模式利用率低;
- 不能横向平行扩展;
- VRRP 协议存在脑裂 (Split Brain) 的风险。Split Brain 从逻辑角度来说是无解的,除非更换架构。
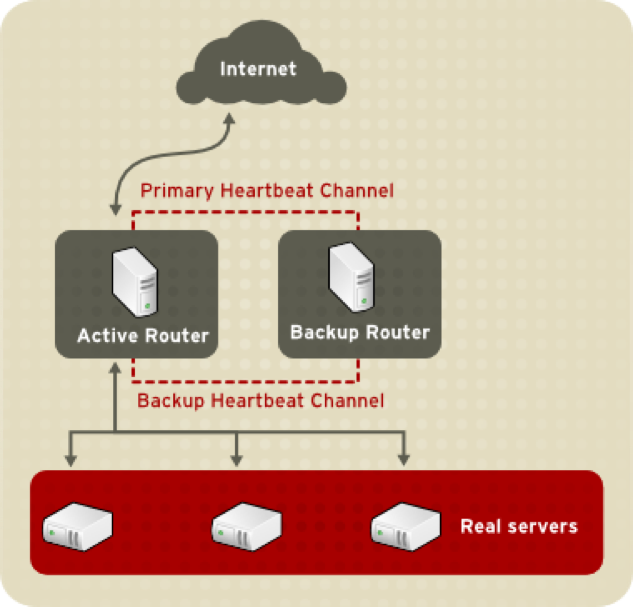
也有少数公司通过 ECMP 等价路由协议搭配 LVS 来避免 Keepalived 的缺陷。综合来看,ECMP 有几个问题:
- 需要了解动态路由协议,LVS 和交换机均需要复杂配置;
- 交换机的 Hash 算法一般比较简单,增加删除节点会造成 Hash 重分布,可能导致当前 TCP 连接全部中断;
- 部分交换机 (华为 6810) 的 ECMP 在处理分片包时会有 BUG。
这些问题均在生产环境下,需要使用者有资深的运维专家、网络专家确保运营结果。
理性的剖析下,我们发现没有任何的负载均衡实现在价格、性能、部署难度、运维人力成本各方面能达到最优,所以 Vortex 必然不是在重造轮子而是在推动这个领域的革新:Vortex 必须不能像 LVS 那样被 Linux 内核限制住性能,Vortex 也不能像 F5 那么的昂贵。
Vortex 负载均衡器的设计理念
用户使用负载均衡器最重要的需求是“High Availability”和“Scalability”,Vortex 的架构设计重心就是满足用户需求,提供极致的“可靠性”和“可收缩性”,而在这两者之间我们又把“可靠性”放在更重要的位置。
1.Vortex 的 High Availability 实现
四层负载均衡器的主要功能是将收到的数据包转发给不同的后端服务器,但必须保证将五元组相同的数据包发送到同一台后端服务器,否则后端服务器将无法正确处理该数据包。以常见的 HTTP 连接为例,如果报文没有被发送到同一台后端服务器,操作系统的 TCP 协议栈无法找到对应的 TCP 连接或者是验证 TCP 序列号错误将会无声无息的丢弃报文,发送端不会得到任何的通知。如果应用层没有超时机制的话,服务将会长期不可用。Vortex 的可靠性设计面临的最大问题就是如何在任何情况下避免该情况发生。Vortex 通过 ECMP 集群和一致性 Hash 来实现极致程度的可靠性。
首先,我们来考察一下负载均衡服务器变化场景。这种场景下,可能由于负载均衡服务器故障被动触发,也可能由于运维需要主动增加或者减少负载均衡服务器。此时交换机会通过动态路由协议检测负载均衡服务器集群的变化,但除思科的某些型号外大多数交换机都采用简单的取模算法,导致大多数数据包被发送到不同的负载均衡服务器。
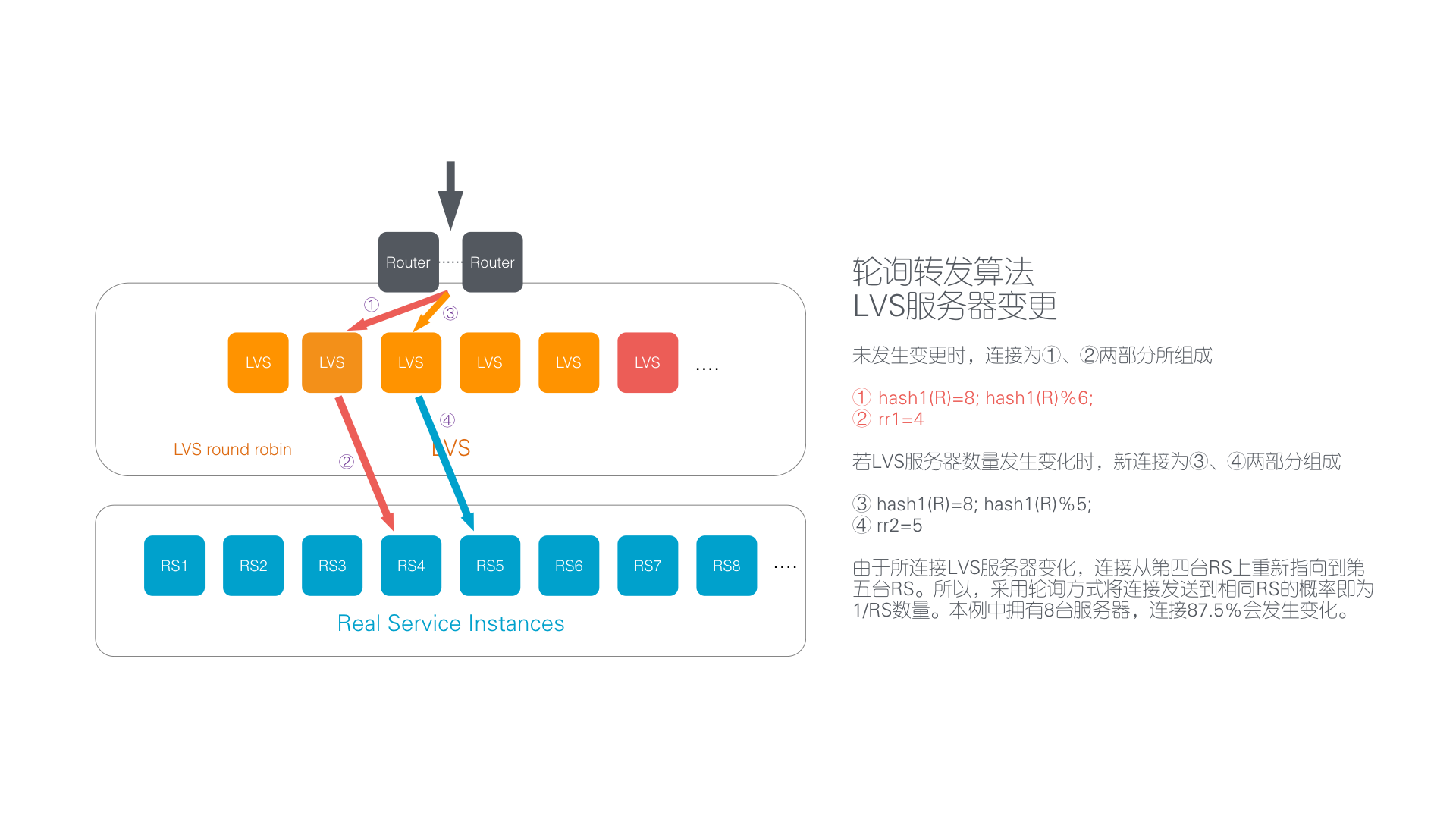
图:负载均衡服务器变化场景
Vortex 服务器的一致性 Hash 算法能够保证即使是不同的 Vortex 服务器收到了数据包,仍然能够将该数据包转发到同一台后端服务器,从而保证客户应用对此类变化无感知,业务不受任何影响。
这种场景下,如果负载均衡器是 LVS 且采用 RR(Round Robin) 算法的话,该数据包会被送到错误的后端服务器,且上层应用无法得到任何通知。如果 LVS 配置了 SH(Source Hash) 算法的话,该数据包会被送到正确的后端服务器,上层应用对此类变化无感知,业务不受任何影响;如果负载均衡器是 Nginx 的话,该数据包会被 TCP 协议栈无声无息地丢弃,上层应用不会得到任何通知。
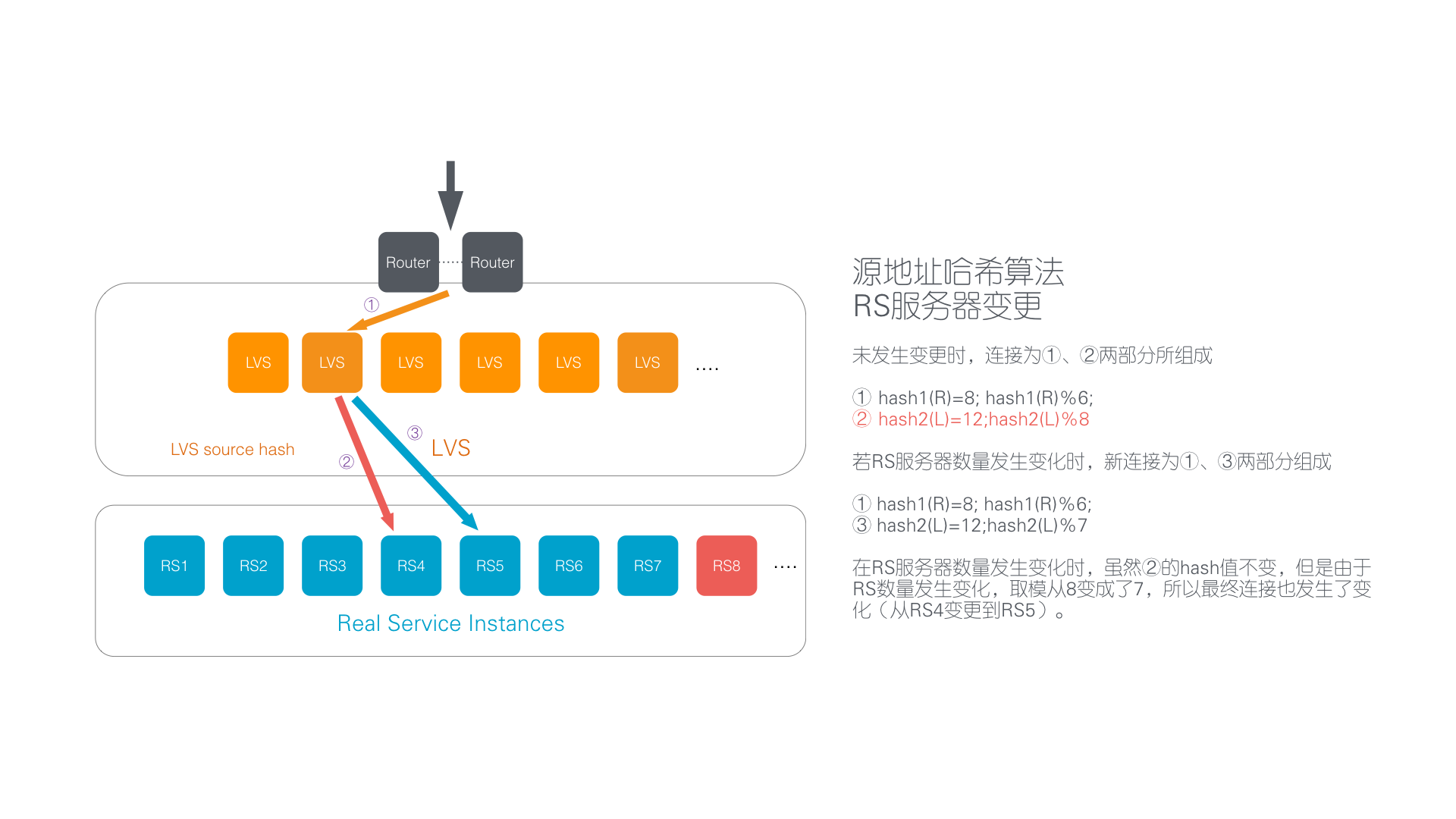
图:后端服务器变化的场景
其次,来考察后端服务器变化的场景。这种场景下,可能由于后端服务器故障由健康检查机制检查出来,也可能由于运维需要主动增加或者减少后端服务器。此时,Vortex 服务器会通过连接追踪机制保证当前活动连接的数据包被送往之前选择的服务器,而所有新建连接则会在变化后的服务器集群中进行负载分担。
同时,Vortex 一致性 Hash 算法能保证大部分新建连接与后端服务器的映射关系保持不变,只有最少数量的映射关系发生变化,从而最大限度地减小了对客户端到端的应用层面的影响。这种场景下,如果负载均衡器是 LVS 且 SH 算法的话,大部分新建连接与后端服务器的映射关系会发生变化。某些应用,例如缓存服务器,如果发生映射关系的突变,将造成大量的 cache miss,从而需要从数据源重新读取内容,由此导致性能的大幅下降。而 Nginx 在该场景下如果配置了一致性 Hash 的话可以达到和 Vortex 一样的效果。
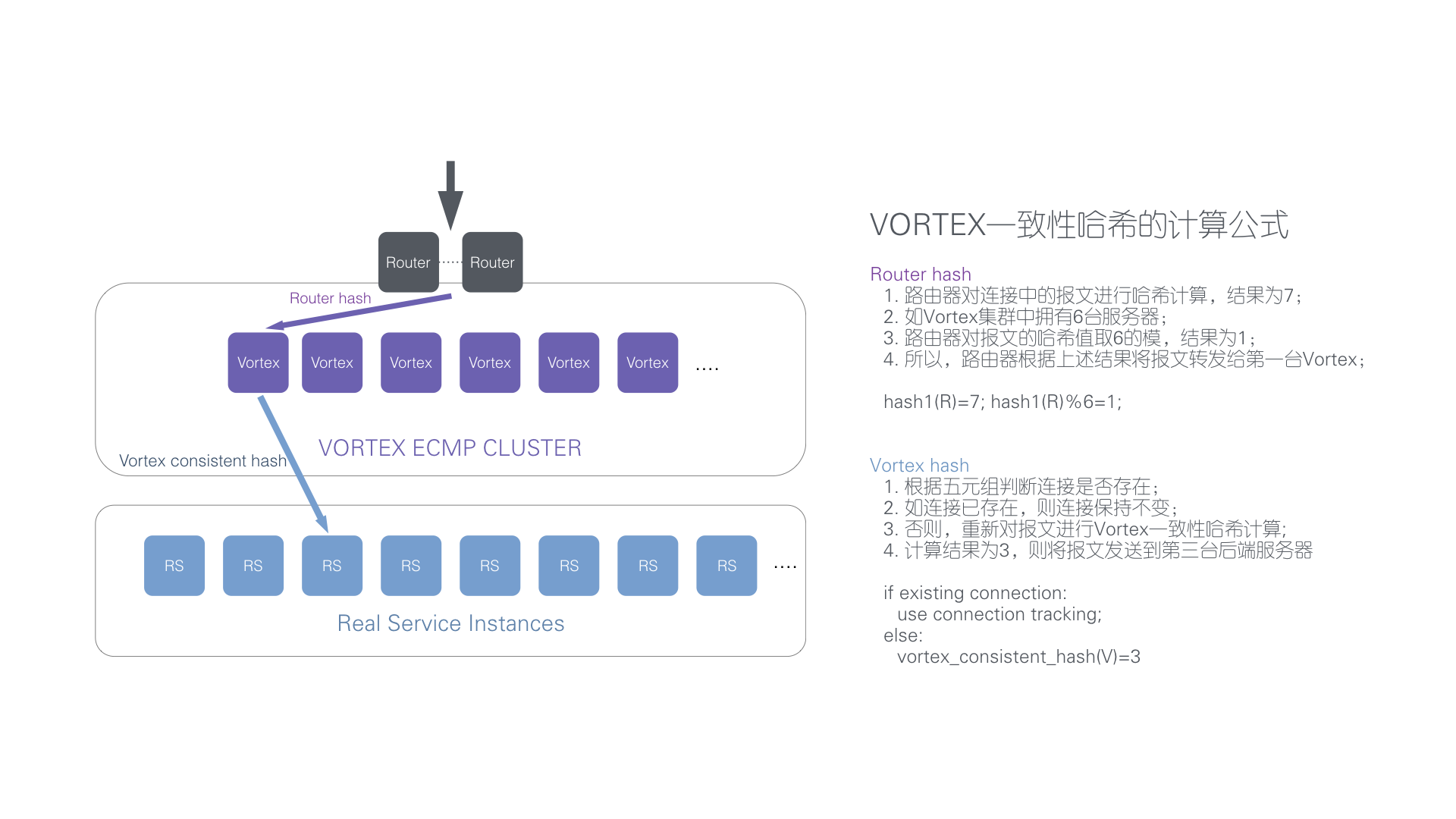
图:Vortex 一致性 Hash 算法的计算公式
最后,让我们来看一下负载均衡服务器和后端服务器集群同时变化的场景。在这种场景下,Vortex 能够保证大多数活动连接不受影响,少数活动连接被送往错误的后端服务器且上层应用不会得到任何通知。并且大多数新建连接与后端服务器的映射关系保持不变,只有最少数量的映射关系发生变化。
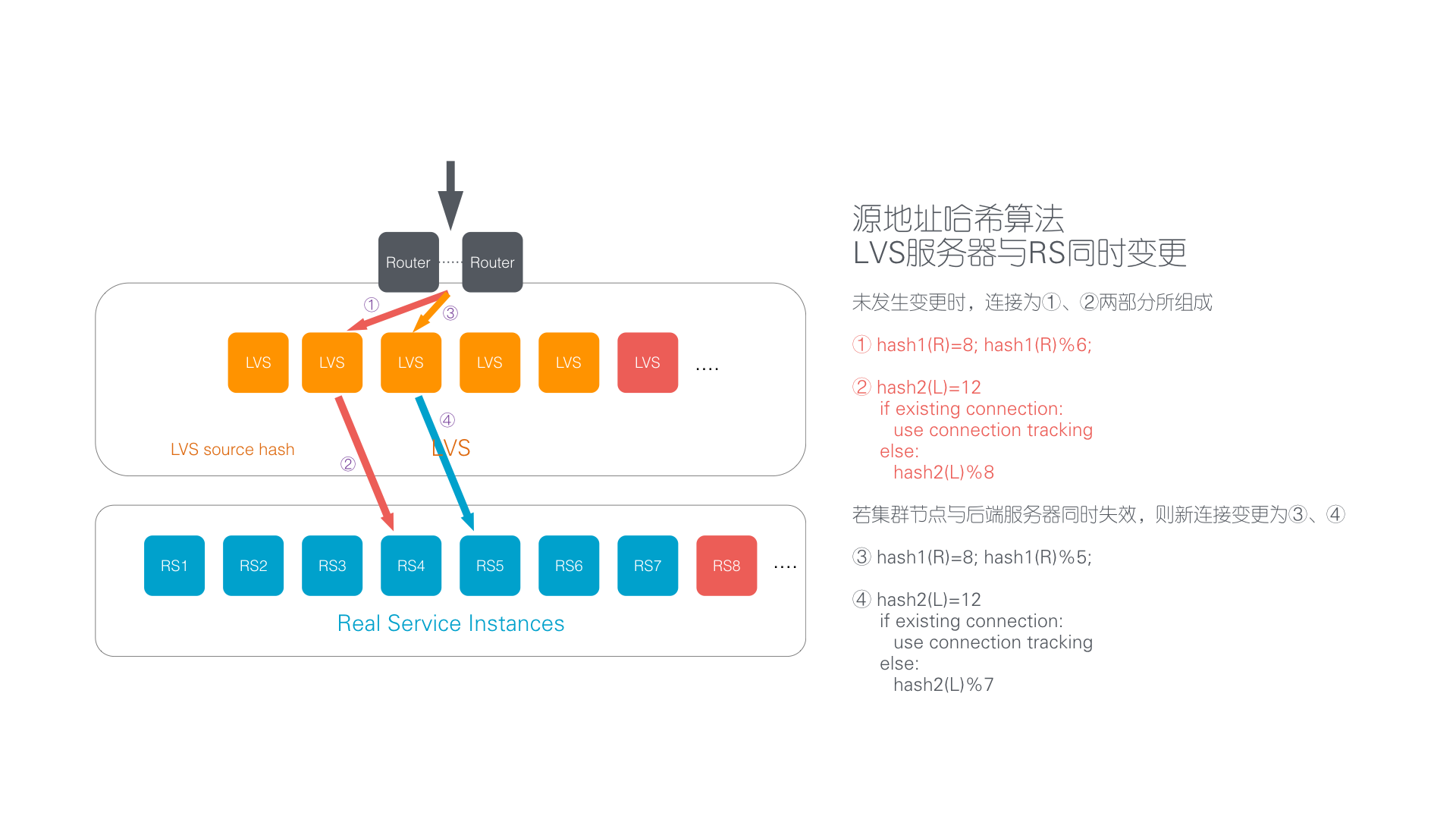
图:负载均衡服务器和后端服务器集群同时变化的场景
如果负载均衡器是 LVS 且 SH 算法的话几乎所有活动连接都会被送往错误的后端服务器且上层应用不会得到任何通知。大多数新建连接与后端服务器的映射关系同样也会发生变化。如果是 Nginx 的话因为交换机将数据包送往不同的 Nginx 服务器,几乎所有数据包会被无声无息的丢弃,上层应用不会得到任何通知。
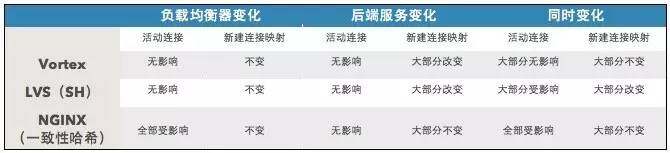
图:不同变化带来的影响对比
2.Vortex 的 Scalability 实现
2.1 基于 ECMP 集群的 Scaling Out 设计
Vortex 采用动态路由的方式通过路由器 ECMP(Equal-cost multi-path routing) 来实现 Vortex 集群的负载均衡。一般路由机支持至少 16 或 32 路 ECMP 集群,特殊的 SDN 交换机支持多达 256 路 ECMP 集群。而一致性 Hash 的使用是的 ECMP 集群的变化对上层应用基本无感知,用户业务不受影响。
2.2 基于 DPDK 的 Scaling Up 设计
虽然 ECMP 提供了良好的 Scaling Out 的能力,但是考虑到网络设备的价格仍然希望单机性能够尽可能的强。例如,转发能力最好是能够达到 10G 甚至 40G 的线速,同时能够支持尽可能高的每秒新建连接数。Vortex 利用 DPDK 提供的高性能用户空间 (user space) 网卡驱动、高效无锁数据结构成功的将单机性能提升到转发 14M PPS(10G,64 字节线速),新建连接 200K CPS 以上。
内核不是解决方案,而是问题所在!
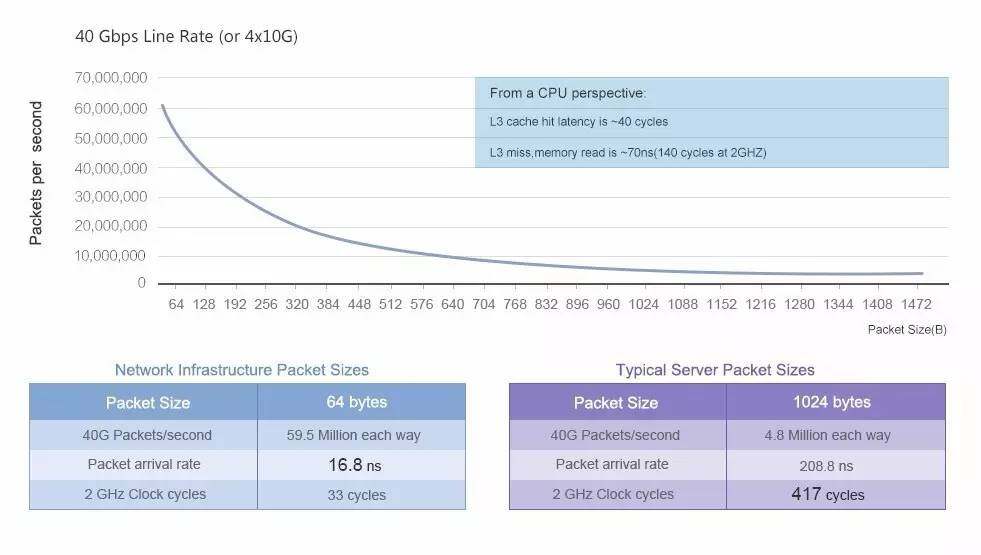
图:DPDK 性能数据图
从上图可以看到随着高速网络的发展 64 字节小包线速的要求越来越高,对 10G 网络来说平均 67ns,对 40G 网络来说只有 17ns。而于此同时 CPU、内存的速度提升却没有那么多。以 2G 主频的 CPU 为例,每次命中 L3 缓存的读取操作需要约 40 个 CPU 周期,而一旦没有命中缓存从主存读取则需要 140 个 CPU 周期。为了达到线速就必须采用多核并发处理、批量数据包处理的方式来摊销单个数据包处理所需要的 CPU 周期数。此外,即使采用上述方式,如果没有得到充分的优化,发生多次 cache miss 或者是 memory copy 都无法达到 10G 线速的目标。
像 Nginx 这样的代理模式,转发程序因为需要 TCP 协议栈的处理以及至少一次内存复制性能要远低于 LVS。而 LVS 又因为通用 Kernel 的限制,会考虑节省内存等设计策略,而不会向 Vortex 一样在一开始就特别注重转发性能。例如 LVS 缺省的连接追踪 Hash 表大小为 4K,而 Vortex 直接使用了 50% 以上的内存作为连接追踪表。
下图简明地比较了三者在实现上的差异:
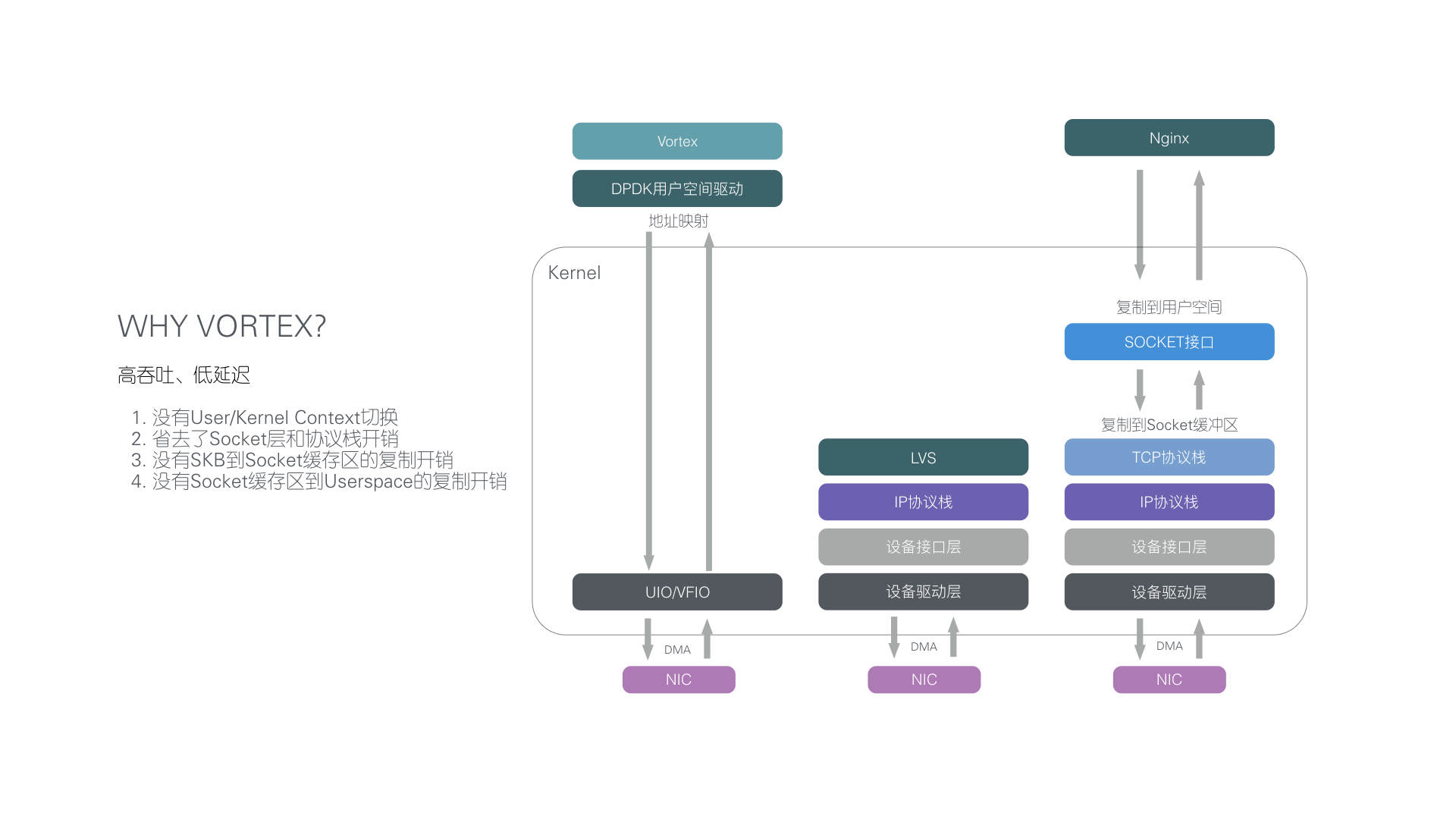
图:LVS、Google Maglev 和 UCloud Vortex 实现差异
Vortex 通过 DPDK 提供函数库充分利用 CPU 和网卡的能力从而达到了单机 10G 线速的转发性能。
- 用户空间驱动,完全 Zero-Copy;
- 采用批处理摊销单个报文处理的成本;
- 充分利用硬件特性;
- Intel DataDirect I/O Technology (Intel DDIO)
- NUMA
- Huge Pages,Cache Alignment,Memory channel use
Vortex 直接采用多队列 10G 网卡,通过 RSS 直接将网卡队列和 CPU Core 绑定,消除线程的上下文切换带来的开销。Vortex 线程间采用高并发无锁的消息队列通信。除此之外,完全不共享状态从而保证转发线程之间不会互相影响。Vortex 在设计时尽可能的减少指针的使用、采用连续内存数据结构来降低 cache miss。通过这样一系列精心设计的优化措施,Vortex 的单机性能远超 LVS。单机性能横向测试比较,参见下图:
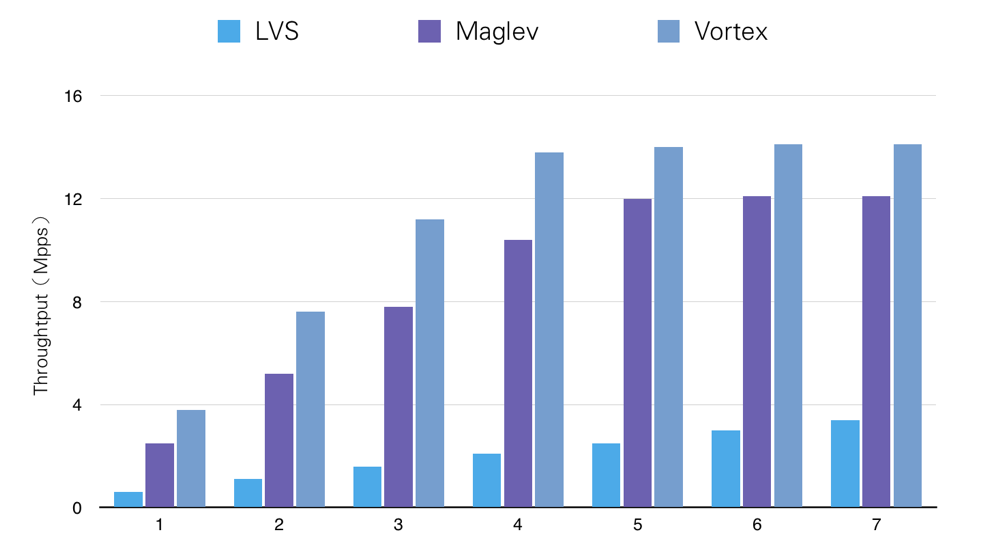
图:单机性能横向测试比较
基于 DR 转发方式
LVS 支持四种转发模式:NAT、DR、TUNNEL 和 FULLNAT,其实各有利弊。Vortex 在设计之初就对四种模式做了评估,最后发现在虚拟化的环境下 DR 方式在各方面比较平衡,并且符合我们追求极致性能的理念。
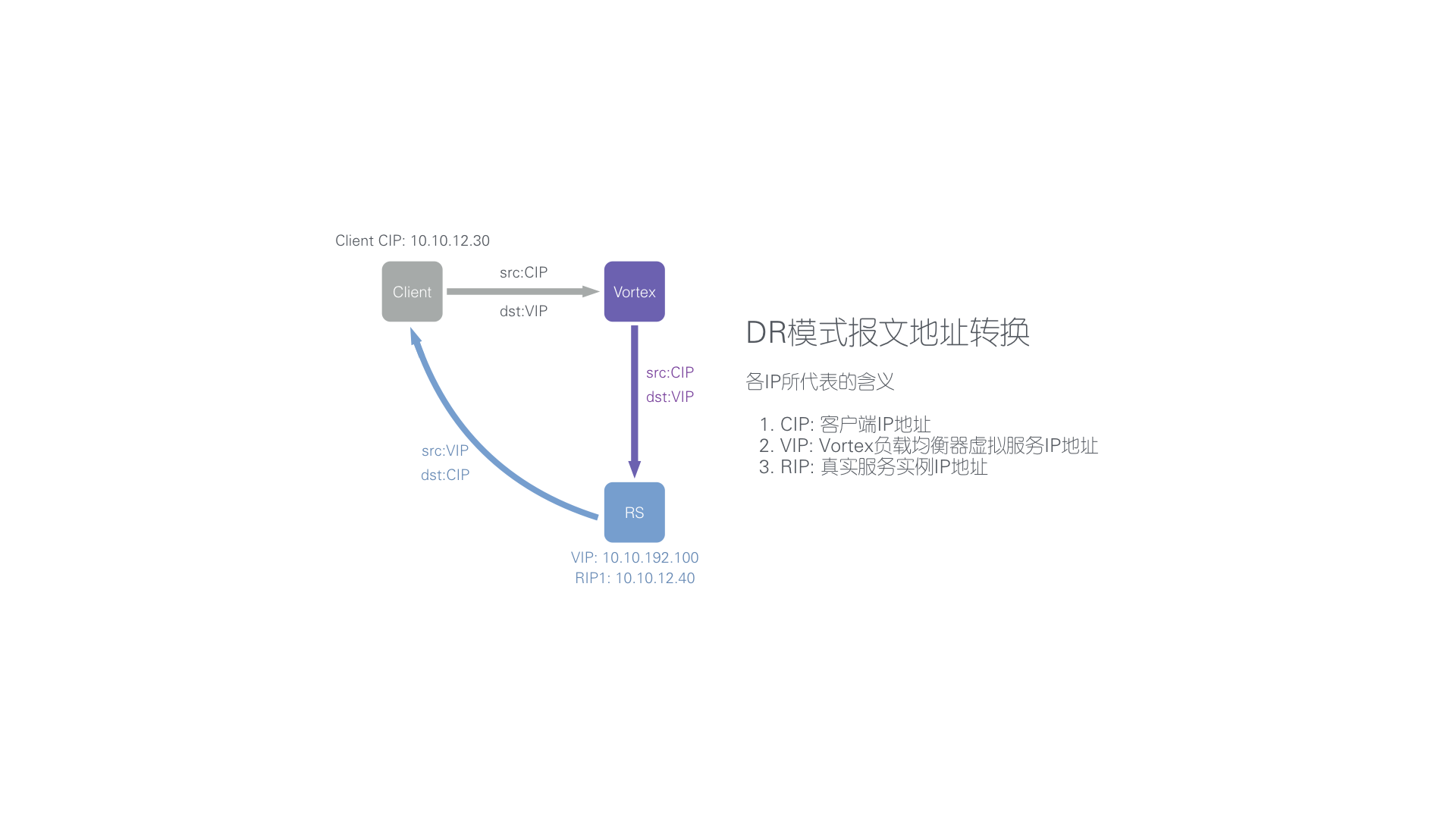
- DR 方式最大的优点是绝佳的性能,只有 request 需要负载均衡器处理,response 可以直接从后端服务器返回客户机,不论是吞吐还是延时都是最好的分发方式。
- 其次,DR 方式不像 NAT 模式需要复杂的路由设置,而且不像 NAT 模式当 client 和后端服务器处于同一个子网就无法正常工作。DR 的这个特性使他特别合适作为内网负载均衡。
- 此外,不像 FULLNAT 一样需要先修改源 IP 再使用 TOA 传递源地址,还得在负载均衡器和后端服务器上都编译非主线的 Kernel Module,DR 可以 KISS(Keep It Simple,Stupid) 地将源地址传递给后端服务器。
最后,虚拟化环境中已经采用 Overlay 虚拟网络了,所以 TUNNEL 的方式变得完全多余。而 DR 方式最大的缺点:需要 LB 和后端服务器在同一个二层网络,而这在 UCloud 的虚拟化网络中完全不是问题。主流的 SDN 方案追求的正是大二层带来的无缝迁移体验,且早已采用各种优化手段 (例如 ARP 代理) 来优化大二层虚拟网络。
结语
采用 Vortex 作为 UCloud 负载均衡产品 ULB 的核心引擎,通过一致性 Hash 算法的引入,并结合 ECMP 与 DPDK 的的服务架构,解决了利用 commodity server 实现 high availability + high scalability 的高性能软件负载均衡集群的课题。
此外,ULB 对原有功能进行了扩展,重新调整了用户交互并增加了数十个新的特性。如优化了批量管理场景下的操作效率,SSL 证书提高为基本资源对象管理。未来,Vortex 将以 ULB 为产品形态输出更多的创新理念。
关于作者:
Y3(俞圆圆),UCloud 基础云计算研发中心总监,负责超大规模的虚拟网络及下一代 NFV 产品的架构设计和研发。在大规模、企业级分布式系统、面向服务架构、TCP/IP 协议栈、数据中心网络、云计算平台的研发方面积累了大量的实战经验。曾经分别供职于 Microsoft Windows Azure 和 Amazon AWS EC2,历任研发工程师,高级研发主管,首席软件开发经理,组建和带领过实战能力极强的研发团队。
附录:
按 7 折折扣并考虑每年 25% 的降价幅度,上文提到的一套 12250v 价格约 87 万人民币 (生产环境中需要主备 2 台),一套包含一个机柜与 4 刀片的 VIPRION 4800 价格约为 188 万人民币。
活动推荐:
2023年9月3-5日,「QCon全球软件开发大会·北京站」 将在北京•富力万丽酒店举办。此次大会以「启航·AIGC软件工程变革」为主题,策划了大前端融合提效、大模型应用落地、面向 AI 的存储、AIGC 浪潮下的研发效能提升、LLMOps、异构算力、微服务架构治理、业务安全技术、构建未来软件的编程语言、FinOps 等近30个精彩专题。咨询购票可联系票务经理 18514549229(微信同手机号)。

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论