

大数据领域从来都不缺乏重磅消息。尤记得 Cloudera 与 Hortonworks 宣布合并,后又被 KKR 和 CD&R 收购并被私有化,再加上 HPE 收购 MapR,曾经凭借 Hadoop 冲上云霄的三驾马车,如今风光不再。此外,今年 Apache 软件基金会(ASF)宣布将其至少 19 个开源项目撤回到 Apache Attic(用于归档的开源项目),其中有 10 个项目属于 Hadoop 生态系统。
Hadoop,这个统治大数据分析处理领域十年的开源框架,如今虽然产品本身强健,但相关的生态和商业化公司却过得越来越惨。市场上不免唏嘘,以 Hadoop 为代表的大数据时代已经落幕。究其原因,如今的企业在数据处理方面的场景,已经和十年前出现天翻地覆的差别:数据来源更加复杂;数据处理的量级大幅增长;数据消费的认知门槛在变低,更重要的是,消费数据的人也变了。
从前,数据分析师是数据的消费者,如今一线业务人员是数据的消费者。
这种变化并不难理解。今天轰轰烈烈的数字化转型,从某种意义上来说,就是在与这个问题较劲:数字化带来的数据,必须要适应业务、赋能业务,满足业务人员的需求,否则对企业而言就很难有实际的效率提升。
这种需求直接催生了大批的大数据云平台,比如 Kyligence Intelligent Data Cloud( Kyligence 智能数据云)、Cloudera Data Platform 等,其中又以 Kyligence 最为典型。Kyligence 由 Apache Kylin(领先的开源分布式 OLAP 分析引擎)核心团队创立,后者是第一个由国人贡献的 Apache 顶级开源项目,最早基于 Hadoop 的 OLAP 引擎开发而来,并在 2019 年宣布完全脱离 Hadoop。
InfoQ 为此特别采访了 Kyligence 联合创始人兼 CTO 李扬,试图搞清楚智能数据云到底要解决什么问题,以及如何解决这些问题。

Kyligence 联合创始人兼 CTO 李扬
让人头痛的四类问题
李扬首先举了一个很常见的需求,客户经常会问:“你有没有一个数据平台能够搞定各种分析场景?”
这不是无理取闹,而是反映了行业的实际情况。今天的数据分析处理行业,首先要适配复杂的数据生产场景:既要处理结构化数据,也要处理非结构化数据;既要做批式处理,也要做流式处理;数据源不是集中式的,而是“烟囱式”的。
其次,要适应不同的基础设施。今天,上云是每一个企业都要考虑的终极选择,多云、混合云都是常见的场景。
另外,对新的数据分析技术要友好,有可扩展性;
最后,数据分析必须要为一线业务人员服务,而不仅只为数据科学家服务,保证计算效率的同时,缩短从技术到效能的转化链路。
Kyligence 4.5 的发布,算是对以上问题有了一个集中回答。而答案大致可以分为三个维度:
统一受治理的数据集市
全面拥抱云原生
引入 AI 增强技术
统一受治理的数据集市与全面拥抱云原生
李扬首先描述了智能数据云的设计理念:“在做强分析能力的基础上,增强数据管理能力,以人工智能进一步替代人工工作,以云原生进一步替代基于 Hadoop 的基础架构,让数据服务与管理发挥核心作用,帮助企业智能管理最有价值数据,支持企业全面数字化转型。”
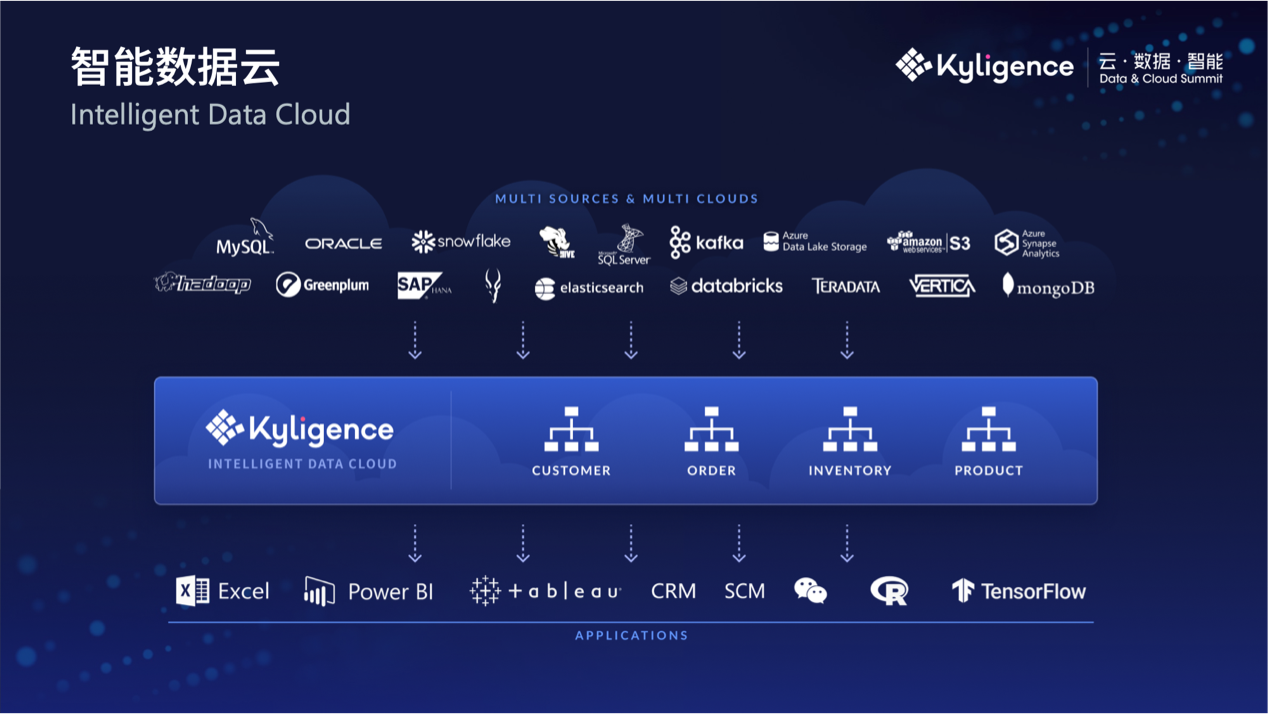
关于对复杂数据生产场景的适配,Kyligence 4.5 提供了两层方案。
一层方案叫做“统一受治理的数据集市”:通过 SQL、MDX、以及 Rest API 等多种接口连接各个数据源,包括流式数据、数据库、数据湖及云,用这种方式统一“烟囱式”的数据。
另外一层方案叫做“统一语义层”,意思是通过统一的业务语义层将复杂的数据映射为业务语言,并以服务的形式为每一个数据消费方在 PB 级别数据规模上提供统一的数据定义及行业标准的访问接口(标准 SQL 及 MDX),为业务提供一致的、标准的数据口径。
“相对于一般的数据库来说,智能数据云是基于业务数据模型设计的”,李扬说。最终呈现到门店经理眼前的,不是关系表、星形模型、英文的表名、列名等技术层面的内容,而是由指标、标签等业务人员常常打交道的内容组成的多维分析模型。
通过这两层方案,Kyligence 完成了对不同业务场景、繁杂海量数据的收集和汇总。
除此之外,Kyligence 4.5 另一个重要更新在于正式支持批流一体。自从 Apache Flink 成熟,业内就开始关注批流一体,试图统一流计算和批计算接口,避免 Spark 和 Flink 打"混双"。去年阿里“批流一体”抗住了双十一 40 亿条/秒的实时计算峰值,算是帮业内吃了定心丸。而在数据分析处理行业,动作快的如 Kyligence 也快速完成了对批流一体的支持。
但至此,当下的数据云平台还不算“搞定各种分析场景”,在基础设施层面,还有另一个关键词必须要注意,它叫做“云原生”。
这里的云原生,重点解决的是数据处理的基础设施和场景问题,也是目前行业内比较统一的发展方向。可以说,以 Hadoop 发行版为立家之本的商业公司,基本都先后受到了云原生理念的冲击,一部分是产品上的,一部分是生态上的。
云计算实现了更低成本,云原生则实现了对业务的赋能,无论是 AWS S3 还是 Kubernetes,都实现了某种技术或生态上对 Hadoop 的替代。Hadoop 庞大的集群部署和公有云的冲突尤其明显,即便是部分企业无法接受 100% 上云,混合云的理念也无疑更适合未来发展。以“存算分离”为代表的云原生概念,更是当下整个业界探索的主流。
所以,各厂商无一例外的全面拥抱云原生。唯一的问题是对云计算厂商的适配问题。
Kyligence 已经支持了多个公有云平台,包括微软 Azure 、亚马逊 AWS,今年 6 月发布了 Kyligence on Huawei Cloud,进展还是非常不错。据透露,Kyligence 后续还会登陆谷歌云、阿里云、腾讯云。在 7 月的 Kyligence Data & Cloud Summit 2021 行业峰会上,Kyligence 则进一步阐释了这种上云构想:
“未来我们也希望能保证我们的客户在多个云的不同架构和平台上,业务的使用方式、体验和接口都是一致的,即使你迁移到一个云平台,上层应用不用改变。在公有云上,我们完全没有了 Hadoop 的依赖,只依赖了云的对象存储和计算资源,可以做到自动缩容,自动监控。”
此外,Kyligence 也发布了“玄武计划”,目的在于加速基于 Kubernetes 及分布式对象存储等架构的私有云产品落地。
对云原生的拥抱,同时也解决了对新技术的开放性问题。传统的 Hadoop 架构,很难及时拥抱新技术。但是 Kyligence 4.5 版本已经整合了大火的 ClickHouse。
Kyligence CTO 李扬对此解释道:“大数据分析产品必须在灵活性、成本、性能方面做平衡,ClickHouse 偏向灵活性,原来 Apache Kylin 偏向性能或成本。一般来说,新业务需要灵活度,更适合 ClickHouse ;成熟的业务看中降本提效,适合 Apache Kylin 。但一个业务总归是要走向成熟的,与其事到临头,在架构层面做整体替换,我们更倾向整合 Kylin 和 ClickHouse ,在顶层保有一个统一的数据分析入口。”
“群体智慧”:AI 增强
至此,数据云平台已经解决了很多问题,不过企业数字化转型过程中面临的一大核心痛点仍未解决:如何让普通业务人员也能通过大数据技术受益,切实把技术突破转变为业务增长。
这个问题的解法大概分为两步:
找出对业务有帮助的数据主题
基于该数据主题建立模型,并分享给普通员工
但第一步通常比第二步要难上许多。因为对于企业而言,定义一个业务主题通常也是件困难的事:一个业务主题之下,包含哪些指标、维度才足够准确和周全?
尤其是对于员工规模千人以上的企业而言,“很难找到一个人,能够从上向下的一下子把统一模型给定义出来”。
Kyligence 的解法是引入 AI 增强技术。AI 增强技术是一门新兴的数据分析方式,是 2019 年 Gartner 列举的十大战略性技术趋势之一。Gartner 认为,这种方式借助了机器学习和 AI,可以降低数据使用门槛,让更多用户进行数据分析。
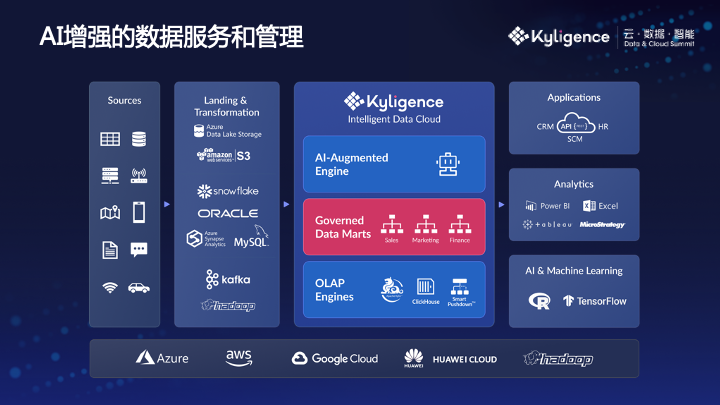
AI 增强算法能够根据用户群体的使用习惯,自动发现和推荐新的业务数据模型,比如从上万条 SQL 中,发现最有价值的表关联、维度和度量的组合。
李扬围绕 AI 增强进一步解释道,假设一家企业有几千个门店经理,平台会赋能每一个门店经理,AI 增强算法则通过持续观察这些人每天分析数据的模式,就能在其中找到一个共有的业务模式,提炼出业务数据主题模型。李扬也将这种自下而上的定义方法称为:群体的智慧。
此外,数据人员也可以连接来自不同主题的业务对象,研究新的数据规律,发现或创造新的有价值的业务数据。
以上种种,让“普通员工读懂数据”成为可能。李扬总结道:“通过 AI 进行整个数据处理,再反馈到 AI,这是一个正循环。我们希望接下来通过统一的数据服务接口,不仅能服务于 BI,也能够服务于更多的 AI 场景上,让一个平台能同时服务于数据科学家、业务用户等多种数据消费者。”
结语
受治理的数据集市、统一语义层、批流一体、云原生支持、AI 增强,基本回答了数据处理领域的核心命题:做什么,怎么做。未来,该领域产品势必要围绕两个基本条件做迭代:
能用,意味着产品能够适用于企业目前的架构条件
好用,意味着产品能够为企业创造价值
我们也乐于看到,未来有更多优秀的数据分析产品,做好“发掘数据价值”这一数字化转型核心工作。

InfoQ 总经理

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论