
微软公司为期一个月的“牛津计划. Docker 在线黑客松”活动已经圆满结束了,此次活动参赛者们根据主办方公布的开发需求以及免费提供的牛津计划 APIs,为我们带了各种各样有趣好玩、脑洞大开的应用。此项活动再次将人们的目光聚焦在了这个可能孕育着未来核心科技萌芽的项目:“牛津计划”。
还记得不久前火过的那个测年龄应用 how-old 吗?用户只要将照片上传到网上,这个应用就可以识别出照片里有几个人,他们的年龄分别是几岁。这项有趣的应用正是基于牛津计划人脸技术的其中一个应用,与此相类似的还有 TwinsOrNot 等。牛津计划就像一个“黑科技”的杂货铺,用户只要注册一个免费的秘钥,即可使用这些 API 轻松地打造自己个性化的应用,而不需深刻理解其背后复杂的算法和模型。牛津计划的提出很大程度上得益于其新任 CEO 萨蒂亚•纳德拉 (Satya Nadella)。这位印度裔高管上台初始就确定了微软今后“移动为先云为先”的战略,而牛津计划正是微软云平台 Azure 的一部分。通过开放 API 和 SDK 的形式,将它借给第三方开发者使用,这也正体现了一个行业领导者所具有的责任与胸怀。
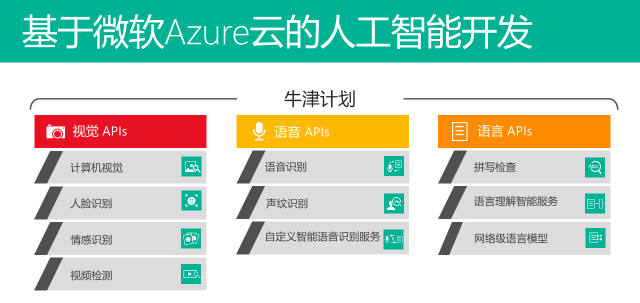
除了图像视觉方面的技术,牛津计划还开放了很多语音识别和语言理解方面的 API 供开发者调用,为人类与计算机进行轻松“对话”贡献一份力量。例如声纹识别(Speaker Recognition APIs)、自定义智能语音识别服务(CRIS)、语言理解智能服务(LUIS)以及拼写检查服务(Spell Check API)等等。不仅提供微软最先进的云端声纹识别算法,可识别音频流中的人声;还能帮助开发者创建自定义语音识别端点的门户,可根据应用的环境、用户群体和词汇表进行量身定制;更可以帮助开发者在应用中增加语言理解能力,让应用具备网络级语言模型的强大处理能力。
那么牛津计划中语音识别和语言理解领域的技术服务究竟是什么样的,它们是如何被研发出来的呢?近日,InfoQ 就该问题采访了微软中国云计算与企业首席项目经理李京梅女士。首先对李女士做一个介绍:
李京梅女士,本科毕业于北京大学并在美国取得纽约州立大学硕士学位。现任微软中国云计算与企业首席项目经理,负责微软牛津计划(Project Oxford) 平台的开发工程及运营。她拥有 18 年软件开发及 IT 行业经验,其间在美国和中国微软公司任职近十年,先后在咨询服务和研发部门担任技术架构师和产品项目经理职务。
InfoQ:您好,李女士。首先请您对微软的牛津计划做一个介绍。
李京梅:牛津计划最早是在 4 月 29 日的全球 “Build 2015”大会上公布的,当时公布的时候有 4 款 API。“牛津计划”仅仅是一个代号,在正式商用之前便于大家记住。牛津计划现阶段还处于公测阶段,我们希望有更多的用户去使用,尤其是第三方的开发者,并提供反馈,以便我们不断更新和迭代,并最终形成对外发布的版本。牛津计划是一系列 API,刚刚推出的时候仅有 4 款:人脸识别、语音识别、计算机视觉和语言理解智能服务;今天牛津计划已经发展到 11 款 API 了。
在这背后有很多微软的大型团队进行支持,例如以沈向阳博士为领导者的微软研究院以及将算法变成现实产品的工程团队。这些团队在牛津计划之前都已经存在了很多年了,但之前的这些所谓的“黑科技”都是存在与微软的现有产品或应用服务中的,例如 Windows、Bing.com 等;但当开发者真正想要用到这些核心技术时,除了购买产品几乎别无他法,因此微软想要将这些核心技术开放给广大的开发者。这些开放给广大开发者的 API 具有以下特点:
- 基于云平台,API 服务都放置于 Windows Azure 云。
- 无需安装。
- 跨平台、跨语言、跨设备,只要开发者可以调用 REST API,都可以轻松使用。
目前牛津计划的 API 服务可以分为:视觉、语音和语言三类领域。基本涵盖了人类“听(语音)、说(语言)、读(视觉)、写(拼写检查)”的各个方面。
InfoQ:那么牛津计划中的语音识别和语言理解这两款 API 是怎样的?
李京梅:至于语音功能则是来自于 Cortana(微软小娜)的核心技术,还是比较成熟的,只不过将 Cortana 当中核心技术拿出来做成了 API 提供给大家而已。在第一款语音 API 中,仅能实现语音转文字(语音识别)和文字转语音(语音合成)的功能,这两项技术与 Cortana 是完全一样的。在语言理解的 API——即 LUIS 中,与语音识别不同的是它包括模型训练的过程,现在 LUIS 已经对公共开放测试,通过访问 https://www.luis.ai/ 即可参与测试。语言理解更多的针对文字,会帮助我们标注“intent(意图)”和“entity(实体)”;与此同时还提供一些现有的模型,例如“小娜”语言理解模型,也提供了自定义模型的功能,目的是为使用者提供方便。
“小娜”语言理解模型中有很多现成的功能,例如“帮我设置一个明早 7 点的闹钟”这样的语言命令可以直接调用。如果开发者想要建立一个“锻炼身体”的语言模型,却没有现成的语言模型可以调用,可以自己训练诸如“追踪我的自行车训练”这样的语言命令,并进行标注其语义(intent)和实体(entity)。语言理解背后很多模型都用到了深度神经网络,我们将基本的数据进行训练后,被训练的模型就会根据使用而变得越来越“聪明”,这即是学习的过程。
LUIS——语言理解智能服务在标注了自定义的意图和实体之后,开发者可以将其对外发布成自己的“Runtime”——即自己的服务。就像微软提供的一些语音识别、人脸识别服务,都是前期训练好的 Runtime,只不过用的是微软自己收集的数据集来训练出来的。
InfoQ:这些微软收集到的,用于训练模型的数据集会有多大体量呢?
李京梅:不同 API 有所不同。这些 API 都是由不同的研发团队研发而成的,不同服务的研发团队所收集数据的方式、收集数据的体量都各有不同。例如 Cortana 的美国研发团队与负责人脸识别的国内研发团队收集数据的方式与体量是不一样的。牛津计划涉及到很多团队的工作,但并不存在一个专门为此提供数据的部门。
这些研究团队都在不断进行前沿技术的研究,当一些前沿技术变得比较成熟、适合做产品化、并且适合从战略角度进行技术开放时,研究团队就会和“云计算与企业事业部”相合作,将该技术变成“云服务”、可以“扩展”、被成千上万开发者去调用。我们“云计算与企业事业部”就是将算法变成产品、在线的服务;也会负责后期的维护与运营;以及商用的“端到端”打理。
InfoQ:目前市面上存在很多其他厂家的语音识别 API,牛津计划的语音识别 API 相较于它们有什么特色或者创新之处吗?
李京梅:凡是进入到“牛津计划”中的 API,目前在微软中的技术一定是相对有竞争力的。从研究领域来说,计算机视觉和语音在业界是有不同的衡量标准的,大家进行测试和排名的标准也不一样。从技术上来说,业界彼此所提供的功能也不同。以计算机视觉为例,人们可以简单地讲:“我这是一款计算机视觉的 API。”但是每一款 API 里面可能还包括很多细分的项目,在每一个细分项目上会有自己不同的衡量和排名。
另外,在研究领域上,如果我们某个研究团队的研究成果获得了一些排名,精确度有所提高,但也仅仅是在该研究领域的技术层面来看,不等于我们的 API 与该研究成果是等同的。从 API 的角度很难去做比较,很难简单地从数字指标的方式去评判优劣。
微软希望大量地从用户体验的角度去了解用户的反馈,也是为了让开发者在写代码之前去 https://www.projectoxford.ai/ 观看 API 的在线演示窗口。这样无需开发者填写拿到的密钥,很好地提升了用户体验。以图片分析和人脸识别为例,开发者只需将想要分析的图片上传上来,该页面的代码只是进行分析功能代码的调用,返回结果与开发者自己编写程序返回的 JSON 结果是一样的,开发者可以查看返回结果精确度等等,不需要自己写代码去实现。
InfoQ:在语音识别过程中人们往往会碰到远场识别和噪音环境下识别等特殊情况,微软在这两方面的应对方案是怎样的?
李京梅:我们有“CRIS”—自定义智能语音识别服务。2015 年 4 月份发布的语音识别服务是微软提前训练好的、通用的模型。通用模型只在正常环境下那些各方面都健全、各个年龄段都有的人群,其测试结果才会比较高。而我们有时候会涉及到特定人群:例如托福考试中非英语母语的人群,说出的英语往往带有口音;老人院中的老人,说话往往不太清楚;比如迪斯尼游乐场这样的噪音环境。针对上述这些特殊环境,我们允许开发者使用自己的、适用于特殊环境的数据集来训练出一个定制化的模型。由于这些数据是针对小范围的、特殊人群(或特殊环境下)的,因此使用 CRIS 开发出的自定义服务在这些语音识别环境下的识别精确度比通用模型要好很多。CRIS 要求我们的开发者具有自定义的数据集,目前还处于内测阶段,开发者可以去申请使用。
InfoQ: 从 API 发布之后,微软使用 API 收集用户数据的过程是怎样的?会涉及到用户隐私吗?
李京梅:在模型研究开发阶段,各个研究团队有他们自己的数据收集方式,无论是购买还是外包,都不尽相同,这一点我之前提到过。在 API 正式发布之后,各个 API 都会有用户隐私声明,还会有开发者行为准则,使用 API 的开发者需要在他开发的应用程序中向终端用户做隐私声明;从微软门户网站上的 API 在线演示来说,牛津计划的算法和模型都是放在“云”上的,它相当于一个“黑盒子”,用户通过 API 将自己的数据上传给微软用于处理测试,处理完毕后微软会将其删除,并不做长期保留。
另外,微软处理完用户数据后还会通过页面上的按钮向用户寻求反馈,用于检验在线演示的结果是否准确。如果用户表示愿意将自己的数据用于微软的模型改善,仅在此种情况下微软才会长期存储该用户的数据,并将用户数据进行“去敏处理”—例如去除位置隐私信息、手机型号信息等。微软虽然收集客户的数据,但绝对会保护客户的隐私并经过客户本人同意。
如果这个数据是事务(transaction)所必须的,例如声纹识别数据、人脸图像数据。用户需要提供这些数据来进行建档 / 建模,微软肯定需要收集这些数据,帮助用户“注册”。
InfoQ:语音识别 API 和语言理解 API 目前有成熟的产品应用吗?
李京梅:现在说“成熟的产品应用”还有点早,因为整个牛津计划发布到现在还不到一年。“微软小冰”对我们来说就是一个应用,虽然它集结了微软的各种技术,但其中语音部分就用了牛津计划中的语音识别技术。现在也有很多用户在使用牛津计划 API,但是暂时没有多少用户将其开发出的产品公布出来。
InfoQ:牛津计划对于自然语言处理技术未来的期待是怎样的?
李京梅:牛津计划还是很注重各个技术领域的平衡。虽然刚开始自然语言处理技术在牛津计划中所占的比重比较小,但是目前也开始慢慢上来了。后续还会有像“知识”、“字典”、“字库”这样偏向语言的服务出现。
就某项技术好不好是一方面,但适不适合做成 API 还要从“数字”来说话。之所以有一段时间给大家做私测和公测,也是希望用数字来说话。例如不同 API,内部不同的功能被用户调用的次数就是一项“硬指标”,有没有人用对于评判 API 好坏很重要;另外从应用的角度我们也在不断征集好的应用案例(App Gallery),靠外部的好的应用案例去放大 API 调用的实际效果,包括内部一些团队搞“黑客松”这样的活动,就是想更多地进行经验分享、在应用上彼此激发灵感。关键是做出能“接地气”的 API。

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论