
这个故事源自一个很简单的想法:创建一个对开发人员友好的、简单轻量的线程间通讯框架,完全不用锁、同步器、信号量、等待和通知,在 Java 里开发一个轻量、无锁的线程内通讯框架;并且也没有队列、消息、事件或任何其他并发专用的术语或工具。
只用普通的老式 Java 接口实现 POJO 的通讯。
它可能跟 Akka 的类型化 actor 类似,但作为一个必须超级轻量,并且要针对单台多核计算机进行优化的新框架,那个可能有点过了。
当 actor 跨越不同 JVM 实例(在同一台机器上,或分布在网络上的不同机器上)的进程边界时,Akka 框架很善于处理进程间的通讯。
但对于那种只需要线程间通讯的小型项目而言,用 Akka 类型化 actor 可能有点儿像用牛刀杀鸡,不过类型化 actor 仍然是一种理想的实现方式。
我花了几天时间,用动态代理,阻塞队列和缓存线程池创建了一个解决方案。
图一是这个框架的高层次架构:
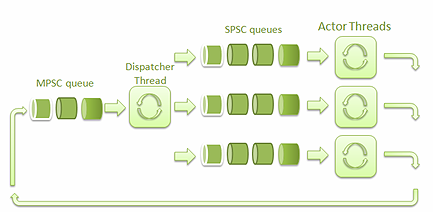
图一: 框架的高层次架构
SPSC 队列是指单一生产者 / 单一消费者队列。MPSC 队列是指多生产者 / 单一消费者队列。
派发线程负责接收 Actor 线程发送的消息,并把它们派发到对应的 SPSC 队列中去。
接收到消息的 Actor 线程用其中的数据调用相应的 actor 实例中的方法。借助其他 actor 的代理,actor 实例可以将消息发送到 MPSC 队列中,然后消息会被发送给目标 actor 线程。
我创建了一个简单的例子来测试,就是下面这个打乒乓球的程序:
public interface PlayerA ( void pong(long ball); // 发完就忘的方法调用 } public interface PlayerB { void ping(PlayerA playerA, long ball); // 发完就忘的方法调用 } public class PlayerAImpl implements PlayerA { @Override public void pong(long ball) { } } public class PlayerBImpl implements PlayerB { @Override public void ping(PlayerA playerA, long ball) { playerA.pong(ball); } } public class PingPongExample { public void testPingPong() { // 管理器隐藏了线程间通讯的复杂性 // 控制 actor 代理,actor 实现和线程 ActorManager manager = new ActorManager(); // 在管理器内注册 actor 实现 manager.registerImpl(PlayerAImpl.class); manager.registerImpl(PlayerBImpl.class); // 创建 actor 代理。代理会将方法调用转换成内部消息。 // 会在线程间发给特定的 actor 实例。 PlayerA playerA = manager.createActor(PlayerA.class); PlayerB playerB = manager.createActor(PlayerB.class); for(int i = 0; i < 1000000; i++) { playerB.ping(playerA, i); } }
经过测试,速度大约在每秒 500,000 次乒 / 乓左右;还不错吧。然而跟单线程的运行速度比起来,我突然就感觉没那么好了。在 单线程 中运行的代码每秒速度能达到20 亿 (2,681,850,373)!
居然差了5,000 多倍。太让我失望了。在大多数情况下,单线程代码的效果都比多线程代码更高效。
我开始找原因,想看看我的乒乓球运动员们为什么这么慢。经过一番调研和测试,我发现是阻塞队列的问题,我用来在actor 间传递消息的队列影响了性能。

图 2: 只有一个生产者和一个消费者的SPSC队列
所以我发起了一场竞赛,要将它换成 Java 里最快的队列。我发现了 Nitsan Wakart 的 博客 。他发了几篇文章介绍单一生产者/ 单一消费者(SPSC) 无锁队列的实现。这些文章受到了Martin Thompson 的演讲 终极性能的无锁算法的启发。
跟基于私有锁的队列相比,无锁队列的性能更优。在基于锁的队列中,当一个线程得到锁时,其它线程就要等着锁被释放。而在无锁的算法中,某个生产者线程生产消息时不会阻塞其它生产者线程,消费者也不会被其它读取队列的消费者阻塞。
在Martin Thompson 的演讲以及在Nitsan 的博客中介绍的SPSC 队列的性能简直令人难以置信—— 超过了100M ops/sec 。比JDK 的并发队列实现还要快10 倍 (在4 核的 Intel Core i7 上的性能大约在 8M ops/sec 左右)。
我怀着极大的期望,将所有actor 上连接的链式阻塞队列都换成了无锁的SPSC 队列。可惜,在吞吐量上的性能测试并没有像我预期的那样出现大幅提升。不过很快我就意识到,瓶颈并不在SPSC 队列上,而是在多个生产者/ 单一消费者(MPSC) 那里。
用SPSC 队列做MPSC 队列的任务并不那么简单;在做put 操作时,多个生产者可能会覆盖掉彼此的值。SPSC 队列就没有控制多个生产者put 操作的代码。所以即便换成最快的SPSC 队列,也解决不了我的问题。
为了处理多个生产者/ 单一消费者的情况,我决定启用 LMAX Disruptor ——一个基于环形缓冲区的高性能进程间消息库。
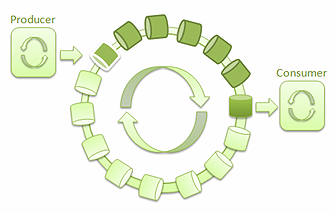
图 ****3: 单一生产者和单一消费者的 ****LMAX Disruptor
借助 Disruptor,很容易实现低延迟、高吞吐量的线程间消息通讯。它还为生产者和消费者的不同组合提供了不同的用例。几个线程可以互不阻塞地读取环形缓冲中的消息:
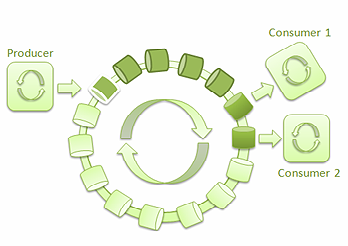
图 4: 单一生产者和两个消费者的 ****LMAX Disruptor
下面是有多个生产者写入环形缓冲区,多个消费者从中读取消息的场景。
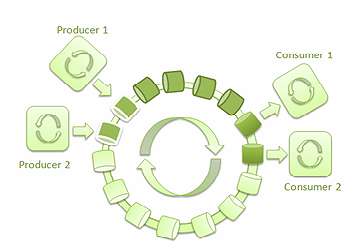
图 5: 两个生产者和两个消费者的 ****LMAX Disruptor
经过对性能测试的快速搜索,我找到了 三个发布者和一个消费者的吞吐量测试。 这个真是正合我意,它给出了下面这个结果:
LinkedBlockingQueue
Disruptor
Run 0
4,550,625 ops/sec
11,487,650 ops/sec
Run 1
4,651,162 ops/sec
11,049,723 ops/sec
Run 2
4,404,316 ops/sec
11,142,061 ops/sec
在 3 个生产者 /1 个 消费者场景下, Disruptor 要比 LinkedBlockingQueue 快两倍多。然而这跟我所期望的性能上提升 10 倍仍有很大差距。
这让我觉得很沮丧,并且我的大脑一直在搜寻解决方案。就像命中注定一样,我最近不在跟人拼车上下班,而是改乘地铁了。突然灵光一闪,我的大脑开始将车站跟生产者消费者对应起来。在一个车站里,既有生产者(车和下车的人),也有消费者(同一辆车和上车的人)。
我创建了 Railway 类,并用 AtomicLong 追踪从一站到下一站的列车。我先从简单的场景开始,只有一辆车的铁轨。
public class RailWay { private final Train train = new Train(); // stationNo 追踪列车并定义哪个车站接收到了列车 private final AtomicInteger stationIndex = new AtomicInteger(); // 会有多个线程访问这个方法,并等待特定车站上的列车 public Train waitTrainOnStation(final int stationNo) { while (stationIndex.get() % stationCount != stationNo) { Thread.yield(); // 为保证高吞吐量的消息传递,这个是必须的。 // 但在等待列车时它会消耗 CPU 周期 } // 只有站号等于 stationIndex.get() % stationCount 时,这个忙循环才会返回 return train; } // 这个方法通过增加列车的站点索引将这辆列车移到下一站 public void sendTrain() { stationIndex.getAndIncrement(); } }
为了测试,我用的条件跟在 Disruptor 性能测试中用的一样,并且也是测的 SPSC 队列——测试在线程间传递 long 值。我创建了下面这个 Train 类,其中包含了一个 long 数组:
public class Train { // public static int CAPACITY = 2*1024; private final long[] goodsArray; // 传输运输货物的数组 private int index; public Train() { goodsArray = new long[CAPACITY]; } public int goodsCount() { // 返回货物数量 return index; } public void addGoods(long i) { // 向列车中添加条目 goodsArray[index++] = i; } public long getGoods(int i) { // 从列车中移走条目 index--; return goodsArray[i]; } }
然后我写了一个简单的测试 :两个线程通过列车互相传递long 值。

图 6: 使用单辆列车的单一生产者和单一消费者 ****Railway
public void testRailWay() { final Railway railway = new Railway(); final long n = 20000000000l; // 启动一个消费者进程 new Thread() { long lastValue = 0; @Override public void run() { while (lastValue < n) { Train train = railway.waitTrainOnStation(1); // 在#1 站等列车 int count = train.goodsCount(); for (int i = 0; i < count; i++) { lastValue = train.getGoods(i); // 卸货 } railway.sendTrain(); // 将当前列车送到第一站 } } }.start(); final long start = System.nanoTime(); long i = 0; while (i < n) { Train train = railway.waitTrainOnStation(0); // 在#0 站等列车 int capacity = train.getCapacity(); for (int j = 0; j < capacity; j++) { train.addGoods((int)i++); // 将货物装到列车上 } railway.sendTrain(); if (i % 100000000 == 0) { // 每隔 100M 个条目测量一次性能 final long duration = System.nanoTime() - start; final long ops = (i * 1000L * 1000L * 1000L) / duration; System.out.format("ops/sec = %,d\n", ops); System.out.format("trains/sec = %,d\n", ops / Train.CAPACITY); System.out.format("latency nanos = %.3f%n\n", duration / (float)(i) * (float)Train.CAPACITY); } } }
在不同的列车容量下运行这个测试,结果惊着我了:
容量
吞吐量: ops/sec
延迟: ns
1
5,190,883
192.6
2
10,282,820
194.5
32
104,878,614
305.1
256
344,614,640
742. 9
2048
608,112,493
3,367.8
32768
767,028,751
42,720.7
在列车容量达到 32,768 时,两个线程传送消息的吞吐量达到了 767,028,751 ops/sec。比 Nitsan 博客中的 SPSC 队列快了几倍。
继续按铁路列车这个思路思考,我想知道如果有两辆列车会怎么样?我觉得应该能提高吞吐量,同时还能降低延迟。每个车站都会有它自己的列车。当一辆列车在第一个车站装货时,第二辆列车会在第二个车站卸货,反之亦然。
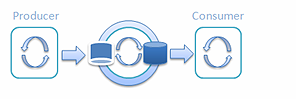
图 7: 使用两辆列车的单一生产者和单一消费者 ****Railway
下面是吞吐量的结果:
容量
吞吐量: ops/sec
延时: ns
1
7,492,684
133.5
2
14,754,786
135.5
32
174,227,656
183.7
256
613,555,475
417.2
2048
940,144,900
2,178.4
32768
797,806,764
41,072.6
结果是惊人的;比单辆列车的结果快了 1.4 倍多。列车容量为一时,延迟从 192.6 纳秒降低到 133.5 纳秒;这显然是一个令人鼓舞的迹象。
因此我的实验还没结束。列车容量为 2048 的两个线程传递消息的延迟为 2,178.4 纳秒,这太高了。我在想如何降低它,创建一个有很多辆列车 的例子:
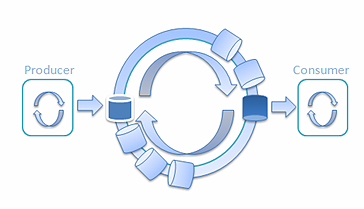
图 8: 使用多辆列车的单一生产者和单一消费者 ****Railway
我还把列车容量降到了 1 个 long 值,开始玩起了列车数量。下面是测试结果:
列车数量
吞吐量: ops/sec
延迟: ns
2
10,917,951
91.6
32
31,233,310
32.0
256
42,791,962
23.4
1024
53,220,057
18.8
32768
71,812,166
13.9
用 32,768 列车在线程间发送一个 long 值的延迟降低到了 13.9 纳秒。通过调整列车数量和列车容量,当延时不那么高,吞吐量不那么低时,吞吐量和延时就达到了最佳平衡。
对于单一生产者和单一消费者 (SPSC) 而言,这些数值很棒;但我们怎么让它在有多个生产者和消费者时也能生效呢?答案很简单,添加更多的车站!
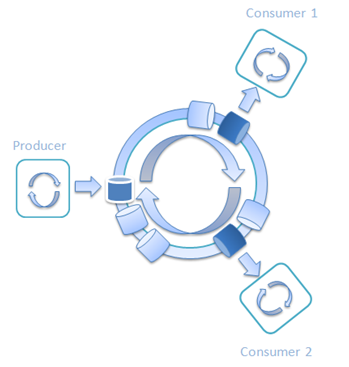
图 9:一个生产者和两个消费者的Railway
每个线程都等着下一趟列车,装货 / 卸货,然后把列车送到下一站。在生产者往列车上装货时,消费者在从列车上卸货。列车周而复始地从一个车站转到另一个车站。
为了测试单一生产者 / 多消费者 (SPMC) 的情况,我创建了一个有 8 个车站的 Railway 测试。 一个车站属于一个生产者,而另外 7 个车站属于消费者。结果是:
列车数量 = 256 ,列车容量 = 32:
ops/sec = <b>116,604,397</b> 延迟(纳秒) = 274.4
列车数量 = 32,列车容量 = 256:
ops/sec = <b>432,055,469</b> 延迟(纳秒) = 592.5
如你所见,即便有 8 个工作线程,测试给出的结果也相当好 -- 32 辆容量为 256 个 long 的列车吞吐量为 432,055,469 ops/sec。在测试期间,所有 CPU 内核的负载都是 100%。
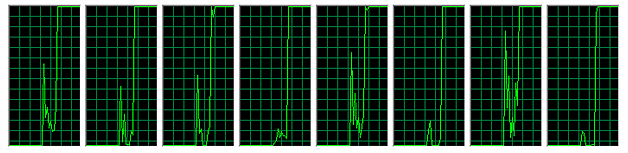
图 10**:在测试有8个车站的Railway 期间的CPU** 使用情况
在玩这个 Railway 算法时,我几乎忘了我最初的目标:提升多生产者 / 单消费者情况下的性能。
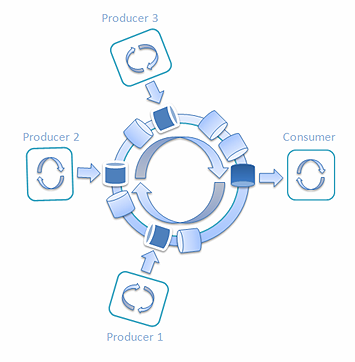
图 11:三个生产者和一个消费者的 Railway
我创建了 3 个生产者和 1 个消费者的新测试。每辆列车一站一站地转圈,而每个生产者只给每辆车装 1/3 容量的货。消费者取出每辆车上三个生产者给出的全部三项货物。性能测试给出的平均结果如下所示:
ops/sec = 162,597,109 列车 / 秒 = 54,199,036 延迟(纳秒) = 18.5
结果相当棒。生产者和消费者工作的速度超过了 160M ops/sec。
为了填补差异,下面给出相同情况下的 Disruptor 结果 - 3 个生产者和 1 个消费者:
Run 0, Disruptor=11,467,889 ops/sec Run 1, Disruptor=11,280,315 ops/sec Run 2, Disruptor=11,286,681 ops/sec Run 3, Disruptor=11,254,924 ops/sec
下面是另一个批量消息的 Disruptor 3P:1C 测试 (10 条消息每批):
Run 0, Disruptor=116,009,280 ops/sec Run 1, Disruptor=128,205,128 ops/sec Run 2, Disruptor=101,317,122 ops/sec Run 3, Disruptor=98,716,683 ops/sec;
最后是用带 LinkedBlockingQueue 实现的 Disruptor 在 3P:1C 场景下的测试结果:
Run 0, BlockingQueue=4,546,281 ops/sec Run 1, BlockingQueue=4,508,769 ops/sec Run 2, BlockingQueue=4,101,386 ops/sec Run 3, BlockingQueue=4,124,561 ops/sec
如你所见,Railway 方式的平均吞吐量是 162,597,109 ops/sec,而 Disruptor 在同样的情况下的最好结果只有 128,205,128 ops/sec。至于 LinkedBlockingQueue,最好的结果只有 4,546,281 ops/sec。
Railway 算法为事件批处理提供了一种可以显著增加吞吐量的简易办法。通过调整列车容量或列车数量,很容易达成想要的吞吐量 / 延迟。
另外, 当同一个线程可以用来消费消息,处理它们并向环中返回结果时,通过混合生产者和消费者,Railway 也能用来处理复杂的情况:
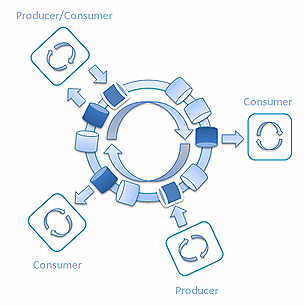
图 12: 混合生产者和消费者的 ****Railway
最后,我会提供一个经过优化的超高吞吐量 单生产者/ 单消费者测试:
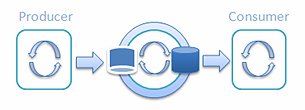
图 13:单个生产者和单个消费者的Railway
它的平均结果为:吞吐量超过每秒 15 亿 (1,569,884,271) 次操作,延迟为 1.3 微秒。如你所见,本文开头描述的那个规模相同的单线程测试的结果是每秒 2,681,850,373。
你自己想想结论是什么吧。
我希望将来再写一篇文章,阐明如何用 Queue 和 BlockingQueue 接口支持 Railway 算法,用来处理不同的生产者和消费者组合。敬请关注。
关于作者
 Aliaksei Papou 是 Specific 集团的首席软件工程师和架构师,那是一家位于奥地利维也纳的软件开发公司。Aliaksei 有超过 10 年的小型和大型企业应用软件开发经验。他有一个坚定的信念:编写并发代码不应该这么难。
Aliaksei Papou 是 Specific 集团的首席软件工程师和架构师,那是一家位于奥地利维也纳的软件开发公司。Aliaksei 有超过 10 年的小型和大型企业应用软件开发经验。他有一个坚定的信念:编写并发代码不应该这么难。
原文英文链接: Inter-thread communications in Java at the speed of light
感谢侯伯薇对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...









评论