在某些情况下,你可能需要在 Java 中实现你自己的数据或语言解析器,也许是这种数据格式或语言缺乏标准的 Java 或开源解析器可以使用。或者虽然有现成的解析器实现,但它们要么太慢,要么太占内存,要么就是没有符合你所需要的特性。又或者是某个开源的解析器存在缺陷,要么是某个开源解析器的项目中止了,原因不一而足。不过无论原因是什么,总之事实就是你必须要自己去实现这个解析器。
当你必须自己实现一个解析器时,你对它的期望会有很多,包括性能良好、灵活、特性丰富、方便使用,以及便于维护等等。说到底,这也是你自己的代码。在本文中,我将为你介绍在 Java 中实现高性能解析器的一种方式,这种方法并且独一无二,但难度适中,不仅实现了高性能,而且它的模块化设计方式也比较合理。这种设计是受到了 VTD-XML 的设计方式的启发,后者是我所见过的最快的 Java XML 解析器,比起 StAX 和 SAX 这两种标准的 Java XML 解析器都要快上许多。
两种基本的解析器类型
为解析器进行分类的方式有好几种,在这里我将解析器分为两种基础类型:
- 顺序访问解析器
- 随机访问解析器
顺序访问是指解析器对进行数据进行解析,在数据解析完成后将其转交给数据处理器(processor)的过程。数据处理器只能访问当前正在进行解析的数据,它既不能访问已解析过的数据,也不能访问等待解析的数据。这种解析器也被称为基于事件的解析器,例如 SAX 和 StAX 解析器。
而随机访问解析器是指解析器允许数据处理代码可以随意访问正在进行解析的数据之前和之后的任意数据(随机访问)。这种解析器的例子有 XML DOM 解析器。
下图展示了顺序访问解析器与随机访问解析器的不同之处:
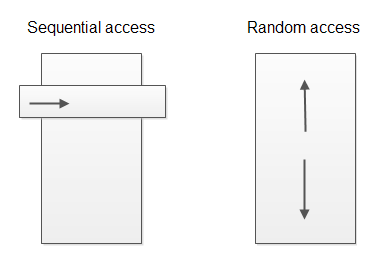
顺序访问解析器只能让你访问当前正在解析的“视窗”或“事件”,而随机访问解析器允许你任意地浏览所有已解析数据。
设计概况
我在这里所介绍的解析器设计属于随机访问解析器。
随机访问解析器的实现通常会慢于顺序访问解析器,因为它们一般都会为已解析数据创建某种对象树,数据处理代码将通过这棵树对数据进行访问。创建这种对象树不仅要花费较长的 CPU 时间,消耗的内存也很大。
相对于从已解析数据中创建一棵对象树的方式,另一种性能更佳的方式是为原来的数据缓冲区建立一个对应的索引缓冲区,这些索引会指向在已解析数据中找到的元素的起点与终点。数据处理代码此时不再通过对象树访问数据,而是直接在包括了原始数据的缓冲区中访问已解析数据。以下是对这两种处理方式的图示:
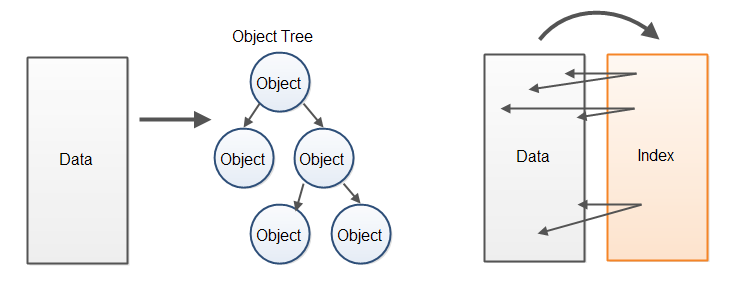
由于我找不到一个更好的名字,因此我将这种方式简单地命名为“索引覆盖解析器”(Index Overlay Parser)。该解析器为原始数据创建了一个覆盖于其上的索引。这种方式让人联想起数据库索引将数据保存在磁盘的方式,它为原始的、未处理的数据创建了一个索引,以实现更快地浏览和搜索数据的目的。
如同我之前所说的,这种设计方式是受到了 VTD-XML(VTD 是指虚拟令牌描述符)的启发,因此你也可以把这种解析器称为虚拟令牌描述符解析器。但我还是倾向于索引覆盖这个名字,因为它表现了虚拟令牌描述符的本质,即对原始数据建立的索引。
解析器设计概要
一种常规的解析器设计方式将解析过程分为两步。第一步是将数据分解为内聚的令牌,一个令牌是已解析数据中的一个或多个字节或字符。第二步是对令牌进行解释,并根据这些令牌构建更大的元素。以下是这两个步骤的图示:
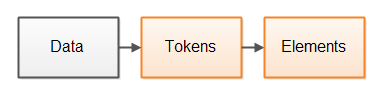
这里的元素并不一定是指 XML 元素(虽然 XML 元素也是解析器元素),而是指构成解析数据的更大的“数据元素”。比如说,在一个 XML 文档中元素代表了 XML 元素,而在一个 JSON 文档中元素则代表了 JSON 对象,等等。
举例来说,**
- <
- myelement
一旦数据被分解为令牌,解析器就能够相对容易地了解它的意义,并且决定这些令牌构成的更大的元素。解析器就能够理解一个 XML 元素是由一个’<’令牌开始,随后是一个字符串(即元素名称),随后有可能是一些属性,最后以一个’>’令牌结尾。
索引覆盖解析器设计
在这种解析器的设计方式中也包含了两个步骤:输入数据首先被一个令牌生成器(tokenizer)组件分解为令牌,解析器随后将对令牌进行解析,以决定输入数据的一个更大的元素边界。
你也可以为解析过程加入一个可选的“元素浏览步骤”。如果解析器从解析数据中构建出一棵对象树,它通常会包含在整棵树中进行浏览的链接。如果我们不选择对象树,而是构建出一个元素索引缓冲区,我们也许需要另一个组件以帮助数据处理代码在元素索引缓冲区中进行浏览。
以下是我们的解析器设计的概要:
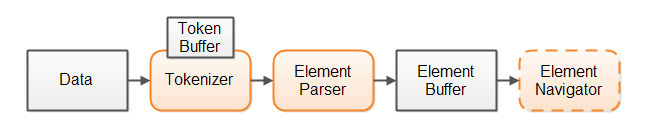
我们首先将所有数据读入一个数据缓冲区中,为了能够通过在解析过程中创建的索引对原始数据进行随机访问,所有的原始数据必须已经存在于内存中。
第二步,令牌生成器会将数据分解为令牌。令牌生成器内部的某个令牌缓冲区会将该令牌的起点索引、终点索引和令牌类型都保留下来。使用令牌缓冲区使你能够查找之前或之后的令牌,在这种设计中解析器会利用到这一项特性。
第三步,解析器获取了令牌生成器所产生的令牌,根据上下文对其进行验证,并决定它所表示的元素。随后解析器会根据从令牌生成器处获取的令牌构建一个元素索引(即索引覆盖)。解析器会从令牌生成器中一个接一个地获取令牌。因此令牌生成器不必立即将所有数据都分解为令牌,它只需要每次找到一个令牌就行了。
数据处理代码将浏览整个元素缓冲区,利用它访问原始数据。你也可以选择用一个元素浏览组件将元素缓冲区包装起来,使浏览元素缓冲区的工作更加简单。
这种设计不会从解析数据中生成一棵对象树,但它确实生成了一个可浏览的结构,即元素缓冲区,索引(即整数数组)将指向包含了原始数据的数据缓冲区。你可以使用这些索引浏览原始数据缓冲区中的所有数据。
本文的以下部分将分析这种设计的各方面细节。
数据缓冲区
数据缓冲区是一个包括了原始数据的字节或字符缓冲区,而令牌缓冲区和元素缓冲区则包含了指向数据缓冲区的索引。
为了实现对解析数据的随机访问,必须以某种形式将它保留在内存中。我们在这里没有选择对象树,而是选择了包含未处理数据本身的数据缓冲区。
将所有数据全部保留在内存中可能会导致对内存的大量消耗。如果你的数据包含了互相独立的元素,例如日志记录,那么将整个日志文件导入内存很可能会造成崩溃。你应该采取的方式是只导入日志文件的一部分,其中至少包含一条完整的日志记录。由于每一条日志记录都可以不依赖于其它日志记录进行解析和处理,你就不需要将整个日志文件在同一时刻加载到内存里了。我在我的文章《使用缓冲区对流进行迭代处理》中描述了如何对一块数据流进行迭代的方式。
令牌生成器与令牌缓冲区
令牌生成器将数据缓冲区分解为令牌,令牌的信息会保存在令牌缓冲区中,包括以下信息:
- 令牌的位置(起始位置的索引)
- 令牌长度
- 令牌类型(可选信息)
以上信息都保存在数组中,这里是一段示例代码:
public class IndexBuffer {
public int[] position = null;
public int[] length = null;
public byte[] type = null;
/* assuming a max of 256 types (1 byte / type) */
}
当令牌生成器在数据缓冲区中找到令牌之后,它会将该位置(起始位置的索引)插入 position 数组、将令牌长度插入 length 数组,并将令牌类型插入 type 数组。
如果你不使用这个可选的令牌类型数组,你也可以在需要的时候通过令牌中的数据得出令牌的类型。这是一种性能与内存占用之间的权衡。
解析器
解析器本质上与令牌生成器非常类似,不同的是它将令牌作为输入,而将元素索引作为输出。和令牌类似,每个元素由它的位置(起始位置的索引)、长度和可选的元素类型几部分组成。用以保存这些数字的结构与保存令牌的结构是完全一样的。
在这里 type 数组仍然是可选的。如果你能够从元素的首个字节或字符中很容易地判断元素的类型,那就无需特意保存元素的类型信息。
在元素缓冲区中所包含的元素的精确粒度取决于被解析的数据,以及之后将对数据进行处理的代码段。举例来说,如果你要实现一个 XML 解析器,你可能会选择将每个开始标签、属性和结束标签作为独立的“解析元素”。
元素缓冲区(索引)
解析器所生成的元素缓冲区包含了引向原始数据的索引。这些索引会记录解析器在数据中所找到的元素的位置(起始位置的索引)、长度和类型信息。你可以利用这些索引实现在原始数据的任意浏览。
从之前的 IndexBuffer 代码段中,你可以看到元素缓冲区为每个元素保留了 9 个字节的缓冲区,4 个字节用于保存位置、另 4 个字节用于保存令牌长度,最后 1 个字节用于保存令牌类型。
你或许能够通过某些手段来减少 IndexBuffer 的内存占用。举例来说,如果你确认其中的元素不超过 65535 个字节,你就可以选择使用 short 短整数,而不是常规的 int 整数来保存令牌长度信息,这样每个元素都可以节省两个字节,将整个内存占用减少至每个元素七个字节。
此外,如果你确认被解析文件的大小不会超过 16,777,216 个字节,那你只需要三个字节来保存位置信息(起始位置的索引)。那么在 position 数组中的每个整数的第四个字节就可以用来保存元素类型,这样就可以完全不用使用单独的 type 数组了。如果你的令牌类型不超过 128 种,你就可以使用七个字节、而不是八个字节来保存令牌类型,这样一来你就可以使用 25 个比特来保存位置,使得最大的位置可以达到 33,554,432。如果你的令牌类型少于 64 种,你还可以空出一个比特以保存位置信息。
VTD-XML 实际上将所有这些信息都保存在一个长整数类型中,以达到节省空间的目的。为了将几个分离的字段加载成为一个单独的整数或者长整数,需要进行一些比特操作,也因此会降低一些速度,但好处是节省了部分内存,这就是一种资源的权衡。
元素 Navigator
元素 navigator 可以帮助处理数据的代码在元素缓冲区中对数据任意浏览。请记住一个语义化的对象或元素(例如一个 XML 元素)或许会包含多个解析器元素。为了简化浏览的实现,你可以创建一个元素 navigator 对象,让它负责在语义化对象级别对解析器元素进行浏览的操作。举例来说,XML 元素 navigator 可以通过在开始标签之间跳转的方式实现对元素缓冲区的浏览。
是否使用元素 navigator 组件由你自行选择,如果你只需要为某个单一的项目的某一个功能实现解析器,你也可以选择不使用这种方式。但如果你希望实现的解析器能够在多个项目中重用,或者是将它发布为开源代码,你或许需要添加一个元素 navigator 组件,这取决于对解析数据的浏览的复杂度有多高。
案例学习:一个 JSON 解析器
为了让索引覆盖解析器的设计更为直观,我自己实现了一个基于 Java 的小型 JSON 解析器,它遵循了索引覆盖解析器设计的方式,你可以在 GitHub 上找到它的完整代码。
JSON 是 JavaScript 对象表示法的简称,它是在 web 服务端和客户端浏览器之间通过 AJAX 进行数据交换的一种常见数据格式,这是因为 web 浏览器内置了将 JSON 转换为 JavaScript 对象的原生支持。以下篇章中我会假设你已经熟悉 JSON 格式了。
这里有一个简单的 JSON 示例:
{"key1":"value1","key2":"value2",["valueA":"valueB":"valueC"]}
JSON 令牌生成器将 JSON 字符串分别为以下令牌:

这里的下划线强调了每个令牌的长度。
令牌生成器还将决定每个令牌的基本类型,以下的 JSON 示例与之前的相同,只是加入了令牌的类型信息:

请注意这里的令牌类型并非语义化,它只是说明了令牌的基本类型是什么,而并没有体现出这些令牌包含了什么内容。
解析器会分析出基本的令牌类型,并将它们替换为语义化的类型。这里是一个相同的 JSON 示例,但使用了语义化的类型(即解析器元素):
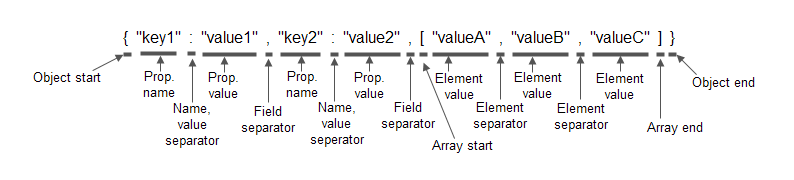
当解析器完成了对该 JSON 对象的解析之后,你将获得一个索引(即元素缓冲区),它由图中所标注的元素的位置、长度和元素类型信息所组成。接下来你就可以对该索引进行浏览,以找出该 JSON 对象中你所需的数据。
JsonTokenizer.parseToken()
为了让你了解令牌生成器和解析工作是如何实现的,我会为你展示 JsonTokenizer 和 JsonParser 中的核心代码。请记得去 Github 下载完整的代码。
以下是 JsonTokenizer.parseToken() 方法的实现,它将负责解析数据缓冲区中的下一个令牌:
public void parseToken() {
skipWhiteSpace();
this.tokenLength = 0;
this.tokenBuffer.position[this.tokenIndex] = this.dataPosition;
char nextChar = this.dataBuffer.data[this.dataPosition];
switch(nextChar) {
case '{' :
this.tokenLength = 1;
this.tokenBuffer.type[this.tokenIndex] =
TokenTypes.JSON_CURLY_BRACKET_LEFT;
break;
case '}' :
this.tokenLength = 1;
this.tokenBuffer.type[this.tokenIndex] =
TokenTypes.JSON_CURLY_BRACKET_RIGHT;
break;
case '[' :
this.tokenLength = 1;
this.tokenBuffer.type[this.tokenIndex] =
TokenTypes.JSON_SQUARE_BRACKET_LEFT ;
break;
case ']' :
this.tokenLength = 1;
this.tokenBuffer.type[this.tokenIndex] =
TokenTypes.JSON_SQUARE_BRACKET_RIGHT;
break;
case ',' :
this.tokenLength = 1;
this.tokenBuffer.type[this.tokenIndex] = TokenTypes.JSON_COMMA;
break;
case ':' :
this.tokenLength = 1;
this.tokenBuffer.type[this.tokenIndex] = TokenTypes.JSON_COLON;
break;
case '"' :
parseStringToken();
this.tokenBuffer.type[this.tokenIndex] = TokenTypes.JSON_STRING_TOKEN;
break;
default :
parseStringToken();
this.tokenBuffer.type[this.tokenIndex] = TokenTypes.JSON_STRING_TOKEN;
}
this.tokenBuffer.length[this.tokenIndex] = this.tokenLength;
}
如你所见,这部分代码非常简单。我们第一步首先调用 skipWhiteSpace() 方法,它将忽略当前位置的数据中的空格字符。第二步是将令牌长度设为 0。第三步,将当前令牌的位置(数据缓冲区中的相对位置)保存在 TokenBuffer 中。第四步,对下一个字符进行分析,根据字符种类(即令牌种类)的不同,将执行 switch—case 结构中的某条语句。最后,将当前令牌的长度保存起来。
以上就是为数据缓冲区生成令牌的全部工作了,请注意,当找到了某个字符串令牌的开头部分之后,令牌生成器就会调用 parseStringToken() 方法,它会对数据进行完整的扫描,直到找到了该字符串令牌的结束为止。这种方式比起在 parseToken() 方法中进行各种条件判断并处理各种不同情况执行得会更快,而且实现也更加容易。
JsonTokenizer 中其余的方法都是 parseToken() 的辅助方法,或者是将数据的位置移至下一个令牌(即当前令牌之后的第一个位置),等等。
JsonParser.parseObject()
JsonParser 类的主要方法是 parseObject(),它会检查 JsonTokenizer 中令牌的类型,并尝试在输入数据中查找该类型的 JSON 对象。
以下是 parseObject() 方法的实现:
private void parseObject(JsonTokenizer tokenizer) {
assertHasMoreTokens(tokenizer);
tokenizer.parseToken();
assertThisTokenType(tokenizer, TokenTypes.JSON_CURLY_BRACKET_LEFT);
setElementData (tokenizer, ElementTypes.JSON_OBJECT_START);
tokenizer.nextToken();
tokenizer.parseToken();
while( tokenizer.tokenType() != TokenTypes.JSON_CURLY_BRACKET_RIGHT) {
assertThisTokenType(tokenizer, TokenTypes.JSON_STRING_TOKEN);
setElementData(tokenizer, ElementTypes.JSON_PROPERTY_NAME);
tokenizer.nextToken();
tokenizer.parseToken();
assertThisTokenType(tokenizer, TokenTypes.JSON_COLON);
tokenizer.nextToken();
tokenizer.parseToken();
if(tokenizer.tokenType() == TokenTypes.JSON_STRING_TOKEN) {
setElementData(tokenizer, ElementTypes.JSON_PROPERTY_VALUE);
} else if(tokenizer.tokenType() == TokenTypes.JSON_SQUARE_BRACKET_LEFT) {
parseArray(tokenizer);
}
tokenizer.nextToken();
tokenizer.parseToken();
if(tokenizer.tokenType() == TokenTypes.JSON_COMMA) {
tokenizer.nextToken(); //skip , tokens if found here.
tokenizer.parseToken();
}
}
setElementData(tokenizer, ElementTypes.JSON_OBJECT_END);
}
private void setElementData(JsonTokenizer tokenizer, byte elementType) {
this.elementBuffer.position[this.elementIndex] = tokenizer.tokenPosition();
this.elementBuffer.length [this.elementIndex] = tokenizer.tokenLength();
this.elementBuffer.type [this.elementIndex] = elementType;
this.elementIndex++;
}
parseObject() 方法能够接受的信息包括:一个左大括({)后接着一个字符串令牌;或是一个逗号后跟着一个字符串令牌;或是某个数组的开始符号([);或是另一个 JSON 对象。当 JsonParser 从 JsonTokenizer 中获得了这些令牌之后,就将它们的开始位置、长度和语义信息保存在它自己的 elementBuffer 字段中。数据处理代码就可以随后浏览 elementBuffer 中的信息,从输入数据中获取所需的数据了。
看过了 JsonTokenizer 和 JsonParser 的核心代码部分之后,你应该对令牌生成器和解析器的工作方式有所了解了。如果要完整地了解代码的工作方式,你可能需要查看 JsonTokenizer 和 JsonParser 的完整实现。它们的代码都不超过 115 行,理解它们应该不是难事。
性能基准测试
VTD-XML 已经为它的 XML 解析器与 StAX、SAX 和 DOM 解析器进行过大量的性能基准比较测试了,从性能上来看 VTD-XML 无疑是最大的赢家。
为了让使用者对索引覆盖解析器的性能建立起信心,我也对我的 JSON 解析器实现与 Google 的 JSON 解析器——GSON,进行了性能对比。GSON 的方式是从某个 JSON 输入(字符串或流)中创建一棵对象树。
请记住,GSON 是一个非常成熟的产品,品质优秀,经过了大量的测试,并且接受用户的错误报告。而我的 JSON 解析器还只是处于概念产品的级别。这次测试仅仅是对性能的表现,这个结果也不代表最终的结论。也请注意阅读该测试的相关讨论。
这里有一些关于构建该测试的具体细节:
- 为了使 JIT 预热以减少启动时的负载,对该 JSON 的输入解析一共运行了 1 千万次。
- 该测试一共对三个不同的文件重复运行了相同的次数,以测试解析器解析小文件、中等文件和大文件的效果。文件的大小分别为 64 字节、406 字节和 1012 字节。因此测试的过程就是首先对小文件进行 1 千万次解析,并分析其结果,然后解析中等文件并分析结果,最后是解析大文件并分析结果。
- 在解析和分析工作开始前,文件已经全部加载到内存中,因此避免了将文件加载的时间算到整个解析时间里。
- 对 1 千万次解析的分析过程会在自己的进程中进行,这意味着每个文件都在独立的进程中进行解析,在每个时间点只有一个文件在进行解析。
- 每个文件会进行 3 次分析,因此对文件的 1 千万次解析工作一共会进行 3 次,每 1 次的分析工作是顺序进行的,而没有采用并行方式。
测试结果表格包括以下三列:
- 原始数据缓冲区的迭代数目
- JSON 解析器
- GSON
第一列中的内容是原始数据缓冲区中的所有数据的迭代数目,这个数字仅仅是用以表示极限的最小时间,即理论上处理所有这些数据的最小时间。当然不可能有任何解析器能够达到这一速度,不过这个数字能够起到参照作用,以显示出解析器和原始迭代速度的差距。第二列中显示了我的 JSON 解析器的运行时间,第三列则是 Google 的 GSON 解析器的运行时间。
以下数据是对三个文件(64 字节、406 字节、1012 字节)各运行 1 千万次解析所需的毫秒数:
File
Run
Iteration
JSON Parser
GSON
Small
1
2341
69708
91190
Small
2
2342
70705
91308
Small
3
2331
68278
92752
Medium
1
13954
122769
314266
Medium
2
13963
131708
316395
Medium
3
13954
132277
323585
Big
1
33494
239614
606194
Big
2
33541
231866
612193
Big
3
32462
232951
618212
如你所见,索引覆盖的实现比起 GSON(一种对象 JSON 解析器)要快得多。虽然结果在预计之中,不过你现在能够了解到它们的性能差距到底有多大了。
值得注意的一点是,在测试进程的执行过程中,内存占用的指标一直非常稳定。尽管 GSON 创建了大量的对象树,但它的内存占用并没有疯狂地增长。而索引覆盖方式的内存占用也非常稳定,比起 GSON 还要小了 1 兆左右,这有可能是因为加载到 JVM 中的 GSON 代码库较大的缘故。
关于测试结果
如果我们只是简单地说对一个为数据创建对象树的解析器(GSON)和一个标记出数据中所找到的元素位置的解析器进行比较,这种说法有欠公平。我们还需要分析一下具体比较了哪些内容。
在一个运行中的应用程序对文件进行解析通常包含以下步骤:
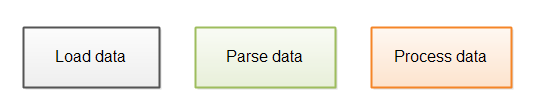
首先从磁盘或者网络上加载数据,然后对数据进行解析,最后进行数据处理。
为了准确测量数据解析部分的速度,我将被解析的文件预先加载入内存中,并且测试代码对数据完全不做任何处理。这种方式虽然测量了纯粹的解析速度,但这一性能差别并不能代表在实际运行中的应用程序一定会获得更好的性能,原因如下:
一个流解析器通常能够在所有数据加载到内存之前就开始解析正在加载中的数据,而我的 JSON 解析器目前还没有实现这一功能,这意味着虽然它在单纯的解析速度上要快上一筹,但运用在实际运行中的应用程序上时,由于它必须等待所有数据加载完成,因此真实的完成速度不一定会更快。下图就表现了这一过程:
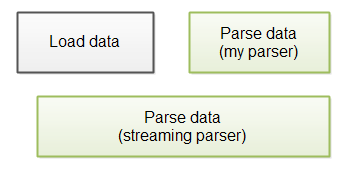
为了加快整体的解析速度,你也可以对我的解析器进行一些修改,让它能够边加载数据边进行解析,不过这样做也许会稍稍降低单纯的解析性能。当然,最终的运行速度或者还是得到一些提升。
与上面的情况类似的是,我的 JSON 解析器对已解析的数据也没有进行任何处理。如果你需要从大量的已解析数据中抽取字符串,那么 GSON 已经为你的需求做好了准备工作,因为它已经为已解析数据创建了一棵对象树。下图就表现了这一过程:

如果你打算使用 GSON,那么它或许已经为你实现了在数据处理中所需的数据抽取过程,如果整个数据处理过程可以省略数据抽取(例如抽取为字符串)这一步骤,那么它的整体速度还要再快一点。
因此,为了准确地测量解析器对你的应用程序的影响,你必须将不同的解析器在你的应用程序中的表现进行测量。我仍然确信使用索引覆盖解析器的速度要更快,但具体有多少差距还不好说。
对索引覆盖解析器的总体讨论
我经常听到一种关于索引覆盖解析器的争论,这种说法认为由于索引覆盖解析器为了实现对原始数据的索引,而不是将原始数据抽取为对象树,它在解析时必须将所有数据读入内存中,这种方式在解析大文件时会对内存产生很大的负担。
这种说法其实就是表明了流解析器(例如 SAX 或 StAX)能够解析巨大的文件,而不需要将整个文件读入内存中。但这种说法成立的前提是,该文件中的数据可以分为多个小块进行解析与处理,而且每个小块可以独立地被解析与处理。举例来说,一个大 XML 文件包含了一系列的元素,每个元素都可以进行独立的解析和处理(类似于一个日志记录集合)。但如果你的数据可以以独立的小块进行分别解析的话,那么你也完全可以实现一个能够做到这一点的索引覆盖解析器。
而如果该文件不能够分解为多个独立的小块进行解析的话,那无论如何你必须将信息加载到某种结构中,以便代码在处理之后的小块时访问这一部分信息。而如果你能够在流解析器中做到这一点的话,那么也同样可以在一个索引覆盖解析器做到这一点。
那些为输入数据创建对象树的解析器往往会占用更大的内存,因为对象树的内存占用会超过原始数据的尺寸。其原因在于不仅每个对象实例会占用内在,而且对象之间的引用也占用了一部分内存数据。
此外,由于所有数据必须一次性全部加载到内存中,因此你需要预先为数据缓冲区预留足以保存全部数据的空间。但如果在开始解析某个文件的数据时,你还不知道整个文件的大小,又该怎么做呢?
假设你有一个允许用户上传文件的 web 应用程序(或者是 web service,或其它类型的服务端应用程序),你很难判断这些文件会有多大,那又如何能够在开始解析之前为它们分配足够大小的缓冲区呢?当然,出于安全性的考虑,你应该设定一个允许上传文件的最大尺寸,否则用户可以通过上传超大文件使你的系统完全崩溃,或者编写一段程序以模拟浏览器上传文件的操作,让这段程序不停地向你的服务器发送数据。你可以考虑为缓冲区分配与允许上传文件的最大尺寸相同的值,这样可以保证你的缓冲区对于有效的上传不会占用所有的内存。如果缓冲的尺寸真的过大,那一定是因为你的用户上传了超大的文件。
关于作者
 Jakob Jenkov是一位创业者、作者和软件开发者,他目前居住在西班牙巴塞罗那。Jakob 从 1997 年开始学习 Java,在 1999 年作为一名专业的 Java 开发者开始工作。他目前关注的概念是如何能够跨多个不同的领域(软件、流程、业务等等)保持高效。他持有哥本哈根信息技术大学的 IT 学科的硕士学位。你可以在他的个人网站中更多地了解他的工作内容。
Jakob Jenkov是一位创业者、作者和软件开发者,他目前居住在西班牙巴塞罗那。Jakob 从 1997 年开始学习 Java,在 1999 年作为一名专业的 Java 开发者开始工作。他目前关注的概念是如何能够跨多个不同的领域(软件、流程、业务等等)保持高效。他持有哥本哈根信息技术大学的 IT 学科的硕士学位。你可以在他的个人网站中更多地了解他的工作内容。




