
2021 年 1 月 11 日,北京智源人工智能研究院(以下简称“智源研究院”)发布面向认知的超大规模新型预训练模型“文汇”,旨在探索解决当前大规模自监督预训练模型不具有认知能力的问题。这一项目由智源研究院发起的“悟道”攻关团队完成,团队由智源研究院、阿里巴巴、清华大学、中国人民大学、中国科学院、搜狗、智谱.AI、循环智能等单位的科研骨干组成。
“文汇”模型不仅使用数据驱动的方法来建构预训练模型,还将用户行为、常识知识以及认知联系起来,主动“学习”与创造。本次发布的“文汇”模型与 1 月初 OpenAI 刚刚发布的 DALL·E 和 CLIP 这两个连接文本与图像的大规模预训练模型类似,“文汇”模型能够学习不同模态(文本和视觉领域为主)之间的概念,可以实现“用图生文”等任务,具有一定的认知能力。“文汇”模型参数规模达 113 亿,仅次于 DALL·E 模型的 120 亿参数量,是目前我国规模最大的预训练模型,并已实现与国际领先预训练技术的并跑。
自从 2020 年 5 月,OpenAI 发布迄今为止全球规模最大的预训练模型 GPT-3 以来,超大规模预训练模型就成为人工智能领域研究的热点。OpenAI、谷歌、Facebook 等国际 IT 公司都在持续推动大规模预训练模型的进一步发展。可以预测到的是,未来的 GPT-4 参数又会增大至少 10 倍,而且处理的数据将会更加多模态(文字、图像、视觉、声音)。
虽然 GPT-3 在多项任务中表现出色,但它最大的问题是没有常识,不具有认知能力。例如,向 GPT-3 提问第一个问题“长颈鹿有几个眼睛?”GPT-3 回答是两个眼睛,再提问第二个问题“我的脚有几个眼睛?”GPT-3 回答的结果也是两个眼睛,这就不符合人类常识。智源研究院学术副院长、清华大学计算机系唐杰教授认为,GPT-3 等超大型预训练模型在处理复杂的认知推理任务上,例如开放对话、基于知识的问答、可控文本生成等,结果仍然与人类智能有较大差距。
为推动研发我国自主的大规模预训练模型,解决目前国际主流模型存在的问题,2020 年 10 月,智源研究院启动了新型超大规模预训练模型研发项目“悟道”。此次发布的是“文汇”(面向认知的超大规模新型预训练模型)的一期研发成果,用于自动生成图片、文字以及视频,可具有初级认知能力。智源研究院院长、北京大学信息技术学院黄铁军教授指出,“文汇”模型针对性地设计了多任务预训练的方法,可以同时学习文→文、图→文以及图文→文等多项任务,实现对多个不同模态的概念理解。经过预训练的“文汇”模型不需要进行微调就可以完成“用图生文”等任务,对模型进行微调则可以灵活地接入如视觉问答、视觉推理等任务。
面向认知的大规模预训练模型“文汇”
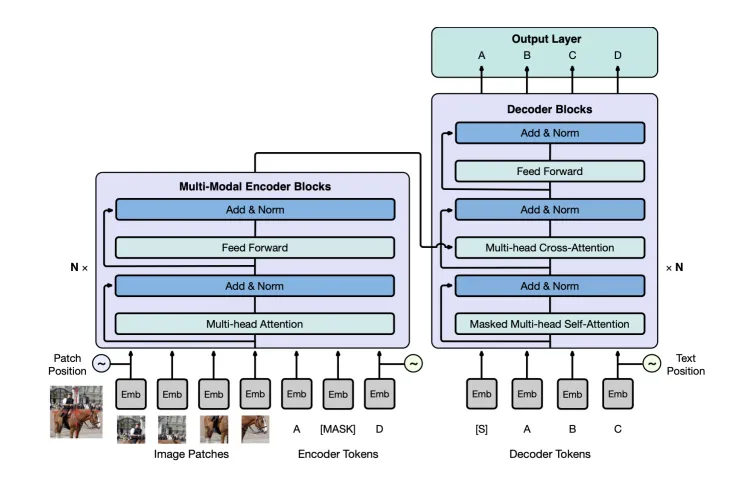
“文汇”是面向认知的大规模预训练模型,项目研究组提出了针对多模态认知生成的大规模预训练的架构 M6:MultiModality-to-MultiModality Multi-task Mega-Transformer。模型整体架构基于 Transformer,其中图像进行切块并对块采用 ResNet-50 提取特征。这些特征以及对应的 position embedding 让图像和文本能组合在一起送入模型。团队针对性地设计了多任务预训练的方法,通过灵活的 mask 技巧实现多任务学习。
“文汇”模型能够完成多种图文生成任务,比如输入下图:

在阿里商品场景下微调的模型将给出描述:
旗袍是一种古典的风格,它不仅能够彰显出女性优雅气质,而且还具有很好的修饰身形。这款旗袍采用了经典的圆领设计,穿着舒适自在,同时又能够展现出女性柔美的颈部线条,让你更加的迷人。精致的绣花工艺,使得整件衣服看起来更加的精致,也更加的凸显出女性的魅力。
模型也可以同时接受文本的提示(Prompt)和图像,例如:

Prompt: 走进平定县宋家庄村,映入眼帘的是
文汇(M6 架构): 一座座古色古香的明清建筑,这里有着浓厚的历史文化底蕴和独特的民俗风情。走进村子,就像走进了一个童话故事里的世外桃源。村子里的房屋依山而建,错落有致地分布着各种各样的古建筑群,古朴典雅的建筑风格让人耳目一新。
与 GPT 不同,研究人员使用 Transformer-XL 来替换了 GPT 中原来的 Transformer 模型,从而能够生成超过 Transformer 的窗口长度(一般为 512)的文本。如下图所示,GPT-XL 架构能够生成基于人设的文本,较好的保持了内容一致性。


系统工程上,采用阿里统一多种并行策略的高性能、灵活、易用的分布式框架 Whale,使用模型并行+流水并行+数据并行训练进行分布式训练,256 卡训练速度是 8GPU 的 29.4 倍,加速比接近线性。基于中文百科、知乎、问答三类数据则由搜狗提供。
“文汇”模型应用即将上线
目前,“文汇”已支持基于认知推理的多种自然语言及跨模态应用任务,部分应用即将与搜狗、阿里巴巴、学堂在线、智谱.AI、循环智能等机构合作上线。目前已有四个样例应用可用于展示模型效果。
(一)基于上传图片的开放域问答
本应用基于图片文本的多模态认知预训练百亿模型,可以支持用户上传图片后,针对图片内容进行提问或生成图片的一句话描述。如上传图片后询问“图片中的电脑在水杯的什么位置?”或“生成对应商品图片的一句话描述”。将于未来大规模应用于阿里的电商场景。

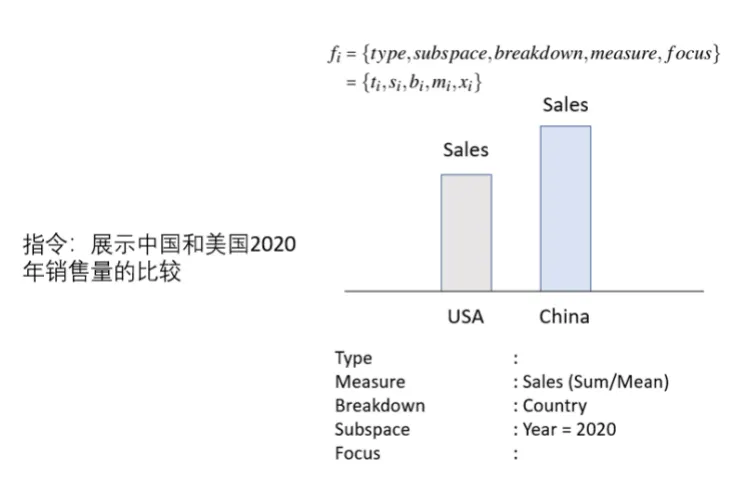
(二)Talk to Data,用语言操作数据可视化
本应用基于数据可视化技术,通过将自然语言转化为可视化查询语句,从而达到“上传图表,输入指令,输出可视化图像”的功能目标。只需要一句自然语言的话,就可以实现数据的可视化自动统计与查询。
(三)基于预训练语言模型的诗词创作应用
本应用可以基于输入的诗歌题目、朝代、作者,生成仿古诗词。与传统基于规则或监督学习的诗歌生成不同,这个应用创作的诗歌来自于自然语言的生成,且无标注数据进行 fine-tune,并且可以模仿任意诗人创作任意新颖题目的诗歌。
下面是基于模型自动作诗的结果:
赠抗疫英雄
君王歌里赠英雄,百万雄师劈毒烟。
况是人民勤努力,更加众志与国捐。
团结团结再团结,万众一心战瘟神。
沔水桥边香雾起,暗送瘟神过汉阳。
咏智利日全食
六出奇光动地来,西方海国见旌旗。
水心惟有终无底,火内曾无彻上灰。
地轴迂回周八极,天球低陷不磨回。
明朝沧海成桑田,吾欲吹嘘弄大灰。
咏科举
输入的创作背景:此诗为作者高中状元,春风得意所做
青云有路状元郎,一步登天入翰林。
黄金榜上词臣贵,笑看人间进士郎。
掖庭宰相垂帘喜,尚书省郎入试忙。
荣登榜首魁星闪,不枉当年万户郎。
咏科举
输入的创作背景:此诗为作者屡试不中,名落孙山所做
金榜无名誓不归,只求大第是何年。
若教九品并孔目,学取天人第一流。
经天纬地才难用,万卷诗书济世游。
未到翰林先一日,十年共话九仙楼。
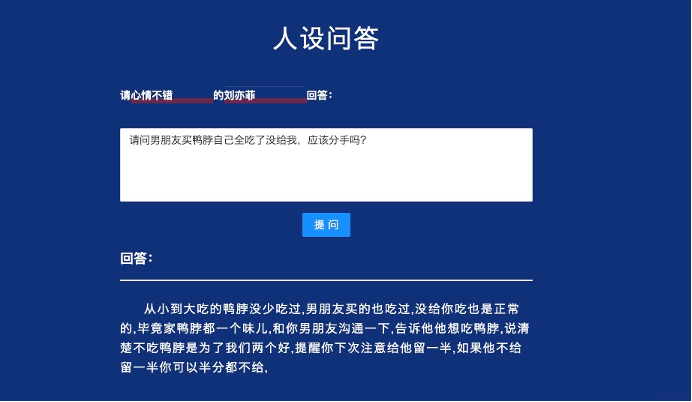
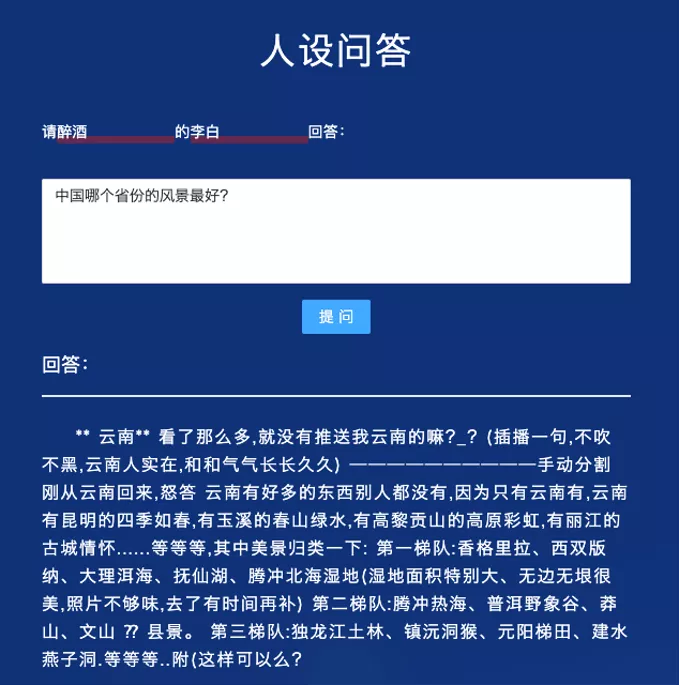
(四)可控人设的开放域问答
本应用支持用户上传问题,并生成具有人物角色风格的定制化文本回答。与传统的开放式问答不同,“文汇”模型生成的答案具有人设的语言特色,问答内容趣味横生。目前该应用将计划在搜狗的问答场景中使用。
“悟道”项目下一步研发计划
目前,“悟道”项目研究团队正在视觉等更广泛的范围内,对大规模自监督预训练方法开展探索研究,已经启动了四类大规模预训练模型研制,包括“文源”(以中文为核心的超大规模预训练语言模型)、“文汇”(面向认知的超大规模新型预训练模型)、“文澜”(超大规模多模态预训练模型)和“文溯”(超大规模蛋白质序列预训练模型)。
2020 年 11 月 14 日,智源研究院已发布了“文源”(以中文为核心的超大规模预训练语言模型)第一阶段 26 亿参数规模的中文语言模型。下一步,智源研究院将联合优势单位加快四类大规模预训练模型的研发进度。特别是“文汇”模型,未来将着力在多语言、多模态条件下,提升完成开放对话、基于知识的问答、可控文本生成等复杂认知推理任务的能力,使其更加接近人类水平。计划在今年 6 月实现“中文自然语言应用系统”“基于图文增强和知识融入的图文应用系统”“基于认知的复杂认知系统”等一批各具特色的超大规模预训练模型,以期达到对国际领先 AI 技术的赶超,尽快实现我国在国际 AI 前沿技术研究的领跑。




