大多数面向关系的映射框架都会为你的软件(不,不是指优秀的软件)带来一些冗余。在你数据库中命名和输入的“列”却被重新命名和构造,被当成了程序代码中的实体变量。如果 ORM 框架为引用限制的建模提供了便利的话,这些内容会在你的数据库和应用程序代码上重复定义。许多 ORM 框架也会拥有一个影射层,用来定义类和数据库表格之间的映射,而这便意味着许多数据库的内容需要在 3 个不同的地方定义:一是数据库,二是 model 类,三是映射层或配置文件。
DRY(Don’t Repeat Yourself,不要做重复的工作)原则的支持者建议,当逻辑相关的元素没有被同时统一改变的话,很难保持他们的同步。
“复制规范、过程或我们所开发的程序中的内容,是很容易的。但是当我们这样做的时候,恶梦便开始了”。
——Hunt & Thomas,Pragmatic 开发者
你可能争辩说数据库的 Schema 不会经常改变,但事实却恰恰相反。我以前的一位教授曾经向我灌输“改变创造了机会”,直到有人设法反驳这个理论的时候,我还一直相信排除万难去改变是一件好事。
走进 ActiveRecord
ActiveRecord 是 Rails 的一个面向关系的映射层,目的是力图减少冗余。相比于把“列”映射成程序代码或映射文件中的实体变量,ActiveRecord 是在运行中基于你的数据库 Schema 动态生成映射的。也就是说,类到表格 (class-to-table) 的映射,某一列(比如主键)和计数器都是用命名规则来识别的。 尽管 ActiveRecord 为 ORM 框架提供了很好的性能,但是仍然有很多扩展的空间,从而进一步地减少代码的冗余,并令其更具动态性。多亏了 Ruby 强大的灵活性和人们为 RubyForge 、 RubyGems 等项目做出的巨大努力,为现有的 Ruby 进行功能扩展是异常方便的。
那,需要扩展什么呢?
ActiveRecord 在应用 DRY 原则的时候存在一些不足。如果你的表格或字段没有遵循命名规则的话,就必须在程序代码中重新定义这些数据库内容。同样,ActiveRecord 的关联和校验对于数据库的约束定义来说也是一种冗余。比如我想在不更换应用程序 ORM 层的基础上,改变我的数据库 schema。之所以要(尽量)避免更改数据库的 schema,是因为如果不这样做就可能会影响到我的程序代码。
ActiveRecord 通过使用数据库的定义信息来动态更新字段元数据。那么,这个策略是否可以应用到所有数据库的结构呢?
DrySQL 简介
DrySQL 是 ActiveRecord 的一个扩展,目的是让代码完全从冗余中解放出来,它完全遵循 DRY 原则。简单来说,它是用来为你的全部数据库 schema 动态建模的,并可查询它的信息 schema、消除应用程序中的面向关系映射。
它是如何运作的呢?
在了解 DrySQL 到底能做什么之前,很重要的一点是要知道它是在什么时候起作用的。为了给你的数据库 schema 建模,DrySQL 需要查询你的数据库,这需要连接数据库并导致一段暂时的性能退化。为了使性能最大化和更加便利,目前的策略是从某一个表中提出元数据,先把一个类的实例映射到那个表上,用来初始化。举个例子,DrySQL 从你的员工(Employee)表中提取出元数据,首先初始化一个 Employee 对象。然后把这些信息存在你员工类的缓存中,它对于所有 Employee 的子实例都是可用的。结果是,性能的降低只在(每个模型类)瞬间发生,数据库不需要连接,直到初始化模型对象时才相连,并且元数据只从与你的应用程序相关联的表格中获得。如果你的应用程序永远都不初始化 Employee 对象,就不会有 Employee 表中元数据。这个策略同样意味着开发者无须改变他们使用 ActiveRecord 的方式便可感受到 DrySQL 的好处。只要在适当的位置引入(require)DrySQL,开发者不用做任何事就能够使用它的功能。
把类映射到表格
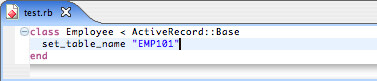
如果你的表格名与 ActiveRecord 命名规则不一致,你需要用 set_table_name 强制把它加到模型类的定义中。这么做的唯一用途是强化命名规则的逻辑,它会令你的应用程序依然要依赖这些假设。
如果表格的名字与命名规则是一致的,那你就不用定义模型类来映射了。
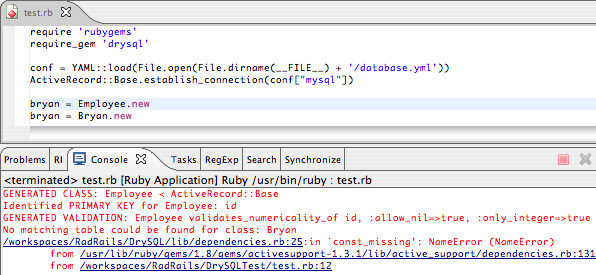
如果对 Employee 的引用生成了一个命名错误(比如,没有定义 Employee 类),DrySQL 会截获这个错误,并用 ActiveRecord 命名规则搜寻符合的表格。如果找到了一个匹配的表格,DrySQL 会自动为它生成一个模型类。如果 ActiveRecord::Base 的基本功能就是你想添加到某个模型类中的,并且你的表格遵循 ActiveRecord 的命名规则,那么你跟本不用为你的表格定义模型类。
识别键
ActiveRecord 会为不同的任务变量使用主键和副键,它们都是作为数据库的约束而定义的。DrySQL 从你的数据库信息 schema 中提取这些信息,所以无论你为数据库中的字段使用什么命名规则,你都不用在程序代码中重新定义它们。下面举一些关于键使用的例子。

Find 方法会查询你的 Employee 表中的记录,看谁的主键值为 18。而不是依赖你主键字段的命名假设上,或在你的 Employee 类中的冗余定义(例如,set_primary_key ‘X’),DrySQL 从你数据库信息 schema 中提取雇员表中的主键。你可以为你的数据库起任何主键的名字,并且不需要在程序代码中定义。对外键来说也是同样的,就像上面那个定义了 belongs_to 关联一样。实际上,DrySQL 会自动生成关联、外键和所有的东西。
生成关联与校验
DrySQL 会提取表格中的约束定义,并用它们自动生成模型类的关联。多数情况下,基于相关的约束生成关联是很容易的,前提是你的数据库 schema 是用公认的方式来定义的。然而间接关联(through association)则是一种例外。如果 A has_many B 与 [X, Y, Z] 间接关联,那么很难去决定应该生成哪一个关联。每一个从 A 到 B 的关联都会覆盖前面一个,这些关联必须依赖处理约束的顺序。尽管还算不上完美,不过 DrySQL 通过拒绝用间接关联重写现有的关联,减轻了问题的复杂性。如果开发者想解决 A has_many B through=> [X, Y, Z] 的问题,他们可以在模型类中定义想要的间接关联,并且 DrySQL 也希望你这么做。DrySQL 也会给直接关联高于间接关联的优先权,所以间接关联是永远不会覆盖掉直接关联的,例如 belongs_to 或 has_many。
许多 ActiveRecord 校验都是与数据库的约束相对应的,并且 DrySQL 会自动生成校验。DrySQL 致力于准确的模仿数据库约束的某些行为,validates_nullabillity_of 就是一个很好的例子。这种校验会通过拒绝空值,强迫加上非空 [NOT NULL] 字段的约束,但是也只有在这种情况下,你的数据库会拒绝空值。举例来说,如果你的字段是自动生成的,或者设有某个默认值,validates_nullability_of 将不会拒绝空值,因为你的数据库本身在这个时候就不拒绝空值。
总结
ActiveRecord 是以一种创新的方式使用数据库的 schema,并自动创建表格和字段的映射。DrySQL 把这种策略应用到了数据库中的其他结构上,它的最终目标是将所有数据库的结构只定义在一个地方:数据库自身。关于 DrySQL 更多的信息,请查看 RubyForge 上的项目主页。
关于作者
Bryan Evans 是一位软件工程师,为多伦多的一个大型财务公司效力,非常擅长软件架构。Bryan 作为 DrySQL 的开发者,是一个长期的 Smalltalk 开发者,并对 Ruby 的 ActiveRecord 非常感兴趣。
查看英文原文: ORM with DrySQL and ActiveRecord - - - - - -
译者简介:刘申(网名 x5),现为哈尔滨工业大学信息管理与信息系统专业在读研究生,对 Web 前端开发、Ruby on Rails 以及极限编程十分感兴趣,曾参与多本 Web 开发相关书籍的翻译。参与 InfoQ 中文站内容建设,请邮件至 china-editorial[at]infoq.com 。




