快速变化的世界,敏捷、DevOps 和自动化
业务需求是变革最显著的驱动力,事倍功半、快速交付是成功的行业先锋与其它公司的区别。
如果竞争对手交付的特性比你更快、质量更高,你最终将失去市场份额。“敏捷开发”的诞生源于快速变化的需求,以有限的资源,应对不断变化的需求,产出有保证的最佳质量。
你再无法等待6 个月后的版本;瀑布方法的大版本概念已经过时了。
技术公司和IT 部门期待的是敏捷。
接下来就是开发与运维的自然连接,因此诞生了“ DevOps ”。
要高效地掌握敏捷 Spring 开发和实践 DevOps,你必须实施部署和过程的自动化。否则部署和发布就需要手动的步骤和过程,无法保证可重复的准确性,容易出现人为错误,也无法以较高的频率处理。
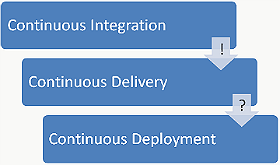
持续集成、持续交付和持续部署是常用的原则和实践,用来结构化处理自动化过程,为软件开发、构建、测试和发布过程中的参与者建立基本规则。
这些并不是新原则,但它们正在获得关注和采纳,证明其价值,就像若干年前的敏捷开发一样。
作为一套原则和实践,持续集成、持续交付和持续部署并不能“一码通吃”。明白每个公司都有自己独特的挑战,这非常重要,这些实践应该进行相应调整,以适应组织结构和文化过程。
持续集成
持续集成的目的是简化开发,避免集成问题。
 这个目标通常需要构建服务器的帮助。这些服务器从版本控制库获取变更代码,自动构建并运行单元测试验证变更,确保为开发者提供及时反馈。单元测试可能会重复运行,甚至在每次提交变更(签入)后运行,从而防止或者及时提醒开发者,变更的代码可能影响了其它代码或者无法通过测试。
这个目标通常需要构建服务器的帮助。这些服务器从版本控制库获取变更代码,自动构建并运行单元测试验证变更,确保为开发者提供及时反馈。单元测试可能会重复运行,甚至在每次提交变更(签入)后运行,从而防止或者及时提醒开发者,变更的代码可能影响了其它代码或者无法通过测试。
除了执行代码为中心的单元测试,集成测试或应用程序级别的回归测试有助于确保代码的完整性和质量水平。
集成问题的快速反馈,自动化测试的质量保障,有助于高度可视化整体开发过程、节省问题定位时间、节省整体开发和集成时间,以及确保更高的质量。
持续交付
持续交付是持续集成的下一个自动化步骤。为了努力变得更高效、精益和更敏捷,我们开始计划和确保每一个变更都是“可发布的”,从而确保我们始终有一个可测试的版本用于部署。
应该实现变更自动在不同的生命周期阶段中移动,整个过程看起来就像下面这张图:
(点击查看大图)

开发时提交变更–> 构建部署包–> 运行单元测试–> 变更移到测试和后续阶段环境–> 运行验收测试。
如果有失败,我们将得到自动的问题提醒,重新返回到开发,开始新的循环。
一旦过程完成,一个经过完整测试的应用程序就可以轻点一下按钮发布到生产环境中了。产品的实际部署一般是人工进行,然后重新运行回归测试。
由于所有变更都已经过测试和验证,部署也已经在前面的生命周期阶段测试过,因此部署到实际生产环境中就变得容易很多,并且显著降低了风险。
遵循持续交付实践,我们将始终有可发布的版本,因此我们可以基于商务决策和上市时间等要求按时发布。
持续部署
下一步是持续部署,持续部署将变更自动推到产品环境(区别于持续交付),然后在那运行最后的测试集。
 在 SaaS 类型的应用或产品(如 Facebook,Amazon 等)中运用持续部署非常有意义,因为公司可以将部分流量转到新特性上,做 A/B 测试,新老版本并列运行,评估新变更,更有信心地进行总体度量和管理变更。
在 SaaS 类型的应用或产品(如 Facebook,Amazon 等)中运用持续部署非常有意义,因为公司可以将部分流量转到新特性上,做 A/B 测试,新老版本并列运行,评估新变更,更有信心地进行总体度量和管理变更。
持续部署也许有风险,因为我们使用同意按钮消除了人的因素,并且我们要记住,即使上述情况下是有道理的,但从业务的视角它并不总是有意义的。(也许我错了,我很难想像银行的一名开发人员,没有经过同意,就部署变更到生产环境。)
衡量持续过程的成功
持续过程带来的成功通常非常明确,主要关注这些领域:
- 更快的变更——能够更快反应
- 更少的变更回退——更高的代码质量,更短的上市周期
- 更多稳定版本——对最终用户来说缺陷更少
- 开发和运维间更好地合作(DevOps…)
通过将“一切”自动化,并将测试、重点更新和过程移到“上游”,我们看到更好的服务、更高的客户满意度和更好的盈亏底线。
安全的数据库持续交付
数据库部署是非常棘手的;与其它软件组件,如代码和编译过的代码不同,数据库不是文件集合。数据库是我们最有价值资产的容器,包含了我们必须保留的业务数据。它包括了应用的数据,客户交易等。为了促进数据库变更,需要开发临时代码,处理数据库 Schema 结构(表结构)、数据库代码(过程、函数等)以及应用程序使用的数据(元数据、查找内容或者参数表)的脚本。
通过将数据库对象变更脚本提交到传统版本控制库中实现自动化,这种方法的用处是非常有限的,也缺少灵活性并与数据库本身失去了关联。同时它也可能是不真实的,由于变更冲突容易导致丢失目标环境的更新。对于自动化来说,使用“比较并同步”的工具是有风险的。这两个概念并不兼容,因为它们彼此并不知道对方。
一个简单的自动化过程基于构建一次,多次部署(Build Once Deploy Many system),它看起来是这样的:
提交变更到版本控制库–> 构建–> 部署测试–> 运行单元测试–> 部署到下一级别–> 运行更多测试–>…–> 部署到 UAT–> 测试–> 部署到生产环境
一个构建步骤,对应多个部署和测试步骤,这就是构建一次,多次部署。
尽管它对原生代码的二进制文件有效,但部署数据库却并非如此,因为你不能简单地复制和粘贴,而是要将老版本转换到新版本,同时保持业务数据还存在数据库中。
有很多这样的场景,脚本创建之后,在它被运行之前,目标环境发生了变化。举个例子,在这个过程之外,数据库打了一个关键补丁,或者另一个团队在并行工作。每种情况都打破了预期结果,导致构建一次,部署多次的方法中产生了问题。
(点击查看大图)

[数据库部署,构建一次,部署多次失败]
使用构建和按需部署方法升级数据库,将会按需生成从当前版本升级到下一版本的数据库变更脚本,确保目标状态是最新的,并且是经过验证和考虑的。
成功升级到预产品(Pre-production)后,脚本被保存起来重用,因此生产环境升级是基于在预产品上测试过的脚本。
(点击查看大图)

[构建和按需部署]
自动化的信心
如果对自动化没有信心,就没人会使用它。由于缺少不同的环境间数据库代码冲突的提醒,DBA 和开发者很难依赖简单的比较并同步方法生成的脚本。
通过签入代码时进行提醒,以文件为基础的版本控制多年前就已经解决了沙盒、分支并行开发中遇到的同样问题。如果发生冲突,开发者将收到警告,他/ 她提交的代码自从签出后已经被别人修改。开发者在本地电脑合并变更,然后再签入合并的代码。
而数据库则不同,它并没有保存在开发者的电脑上;代码存在于各种环境中,任何有权限的人都能修改它。当生成变更脚本时,应该使用基线方法(与现代的,以文件为基础的版本工具使用的是相同的方法)解决合并问题。

基线影响分析
检查盒子
当我们实施持续交付时,认识到数据库持续过程需要健壮的数据库版本控制、安全的自动化部署和清晰的工作过程,并且过程的自动化将帮助我们定义解决方案的类型。
以下是这些挑战的一些例子, DBmaestro 有助于解决这些问题。
- 强化数据库版本控制。这能保证所有数据库变更遵循一个强制的文档过程,这样我们就始终知道谁在什么时间,因为什么原因做了什么改变。这是后续过程的基础。
- 使用基于任务的开发过程,有助于将每一个引入的变更与变更请求、故障单或工作项关联起来。后期的部署可以依靠这些信息来帮助决定哪些变更需要发布、哪些即将发布以及哪些要推迟。
- 基线明确的部署,连接到版本控制工具,分析引入的变更有哪些影响,帮助我们安全地确定应该部署哪些变更。更重要的是,它让我们明确应该取消哪些变更,才不会推翻其他团队部署的重要变更,或者覆盖补丁程序到生产环境中。
- 自动化接口(Web-service,命令行 API 等等)是创建一个和谐过程所必须的,将数据变更的处理作为完整过程的一部分,与 Java 或.Net 代码变更的交付紧密结合。能够自动升起红色标记和“停止这一行”是持续过程必不可少的步骤。我们想要的最后一件事是可以随意将变更部署到生产环境,因此当有什么东西不满足我们的安全假定时,应该能够得到警告,这将直接决定我们能够沉睡还是做噩梦。
总结
在各种持续过程中,数据库是一个真正的挑战。对自动化来说,数据库对象变更脚本放入传统版本控制工具或使用“比较并同步”工具,这是效率低下或者风险很高的事情,因为两个概念彼此互不相识。在持续交付和 DevOps 中,需要更好的解决方案。
数据库持续交付需要遵循变更管理的成熟的最佳实践,强制在数据库上执行单一的变更过程,当融入其他发布过程时,能够处理部署冲突,消除代码覆盖、交叉更新和代码合并的风险,
关于作者
Yaniv Yehuda是 DBmaestro 公司的共同创始人和 CTO,该公司是一家企业软件开发公司,专注于数据库开发和部署技术。Yaniv 同时还是 Extreme Technology 公司的共同创始人和开发经理,该公司是服务于以色列市场的 IT 服务提供商。Yaniv 曾是以色列国防军计算机中心 Mamram 的上尉,在那里他担任软件工程经理。
原文链接: Database Continuous Delivery
数据库自动化——构建并按需部署 >




