
数据分布通常应用在高性能计算(HPC)中。数据分布拓扑主要有两种:复制和分区。
使用数据分区可以实现大批量数据的并行处理。通过数据复制则可以做到负载均衡(LB)和高可用性(HA)。本文着重介绍数据复制的需求。
在数据复制环境中,一个数据项往往有好几个副本,但应该保证一定程度的数据一致性,好让最终用户看起来全局只有一份数据。使用数据复制最大的挑战就是根据业务需求在数据一致性和性能之间做出正确的权衡。
要实现数据一致性,通常会运用一些并发控制方案。本文将解释 Oracle10g 高级复制、 Oracle10g 真正应用集群(RAC)、内存数据库(IMDB) Oracle10g TimesTen 、 Gigaspaces 内存数据网格(IMDG)7.1 里复制所涉及的并发控制。
讨论过程中我们使用一个分布式航空订票系统为例,后面简称为 DATS。为了具备高可用性和负载均衡,DATS 有两个数据库:一个在纽约、一个在洛杉矶。根据复制方案,数据只能在一个地方更新,然后复制到另一个地方;或者两个地方都更新,然后互相复制。
此外,假设以下动作会按时间顺序发生:
- 两个本地数据库副本此刻已经同步,只剩下一张机票。仅剩的这张票在纽约或洛杉矶都可以预定;
- 一位纽约客户购买了这张票。这个动作会更新纽约本地的数据库,并且会按照复制方案以某种方式复制到洛杉矶的数据库里去;
- 根据复制方案,洛杉矶数据库也许显示那张票仍然可以购买,也许显示已经被纽约用户预定了。要是洛杉矶数据库仍然显示这张票在售,那这张票就会被卖给一位洛杉矶顾客。这就会出现超卖的情况。
由于 DATS 在广域网环境只适合异步复制,在同步复制环境里,DATS 应该作如下变化(下称“DATS 改”):我们假设纽约有第二个数据库,和第一个数据库在同一个数据中心里,这个数据库将取代洛杉矶的数据库。
我们还假设 DATS 使用了乐观并发控制机制。下面是乐观并发控制在 DATS 里的工作原理:
为了具备良好的性能,大部分多层应用都使用乐观并发控制,这会带来更新丢失的问题。比如说,如果我们在 DATS 的两个数据库中使用乐观并发控制,步骤三的应用层有可能先于步骤二读取洛杉矶的数据库,却在步骤二之后才把那张票卖给一位洛杉矶顾客。
应用必须使用“带有版本检查的乐观并发控制”来解决这个问题。版本检查方案可以只是一个版本号,只要有相应的数据变化,版本号就加一。
假设步骤一的版本是 0。步骤二将版本更新为 1。步骤三的应用层读到的版本也是 0。但在应用层试图出售同一张票的时候,步骤三会失败,因为它会发现版本已经从缓存里的 0 变成 1 了。
1. 使用分布式锁和本地事务的同步复制
Oracle RAC 在 8i 及以前的版本中被称为 Oracle 并行服务器(OPS),它允许多个实例站点访问同一个物理数据库。为了让用户在任何时候、任何实例站点都能读取、写入任何数据,Oracle RAC 使用“缓存融合(Cache Fusion)”来保证数据的一致性。
“缓存融合”主要使用带有分布式锁管理器(DLM)的同步复制。DLM 的功能之一是扮演分布式锁(DL)的协调员,使同一个资源(比如表的一行)一次只能被一个实例站点修改,其它站点必须等待。
DLM 还是全局资源目录。举例来说,当实例站点 1 更新了一行内容,它并不需要主动把新版本的数据推送给其他实例站点。相反,它只需要把其他副本置为无效就可以了。当实例站点 2 稍后请求同一行内容时,DLM 会让它从实例站点 1 获取最新的版本。
此外,由于有 DLM,而且仍然只有一个物理数据库,实例站点 1 并不需要使用分布式事务。
这样做的优点是有了高度的数据一致性,读取和写入也都有高度的负载均衡(通常来说,同步复制不会对写入操作进行均衡,因为相同的写入会在所有站点之间进行复制。但有了 RAC 轻量级的失效机制,写入操作也会进行相对的均衡)。
缺点则是写入性能不能伸缩(即使失效机制很轻量,但太多的失效仍然会阻塞共享互连;所以 RAC 的写操作仍然无法伸缩),由于复制同步和分布式锁,这种做法也满足不了高可用和快速互连的需求(分布式锁的实现通常在每个站点都有很多守护进程和数据结构,在低速的局域网和广域网上,分布式锁的协调能力会很差甚至不可能完成协调。至于 Oracle 的缓存融合,分布式锁是在集群环境中用全局缓存服务(GCS)、全局队列服务(GES)和全局资源目录(GRD)实现的)。
你应该会注意到,这种方案是 RAC 独有的。如果你有不止一个个带事务的数据源,使用本地事务有时候会导致数据的不一致。不管怎么说,同时使用分布式锁和分布式事务实现同步复制,即便分布式事务能保证数据的原子性,用起来也会非常昂贵。我至今都没见过使用这种方案的产品。
由于同步复制不太现实,在广域网甚至不太可能,这种方案只能应用于“DATS 改”。步骤三必须等待步骤二释放分布式锁。当步骤三获得分布式锁之后,会看到那张票在步骤二已经售出。
2. 使用本地锁和分布式事务的同步复制
Oracle 的多主复制也称为 peer-to-peer 复制或 n-way 复制,它有两种数据一致性协议,一是同步复制,另一种在第四节进行阐述。
同步复制在一次分布式事务中,将待执行的DML 修改或复制过程应用到参与复制环境的所有站点(每个站点都有自己的物理数据库,这是与Oracle RAC 的不同之处,RAC 只有一个物理数据库)。如果DML 语句或过程在任意一个站点失败了,那整个事务都会回滚。
分布式事务能实时确保所有站点上的数据一致性。但它并不使用任何分布式锁。相反,它只在本地事务的参与者中使用本地锁。
应用对一个被复制的表执行同步更新,就是这种情况。Oracle 首先会锁定本地的那一行,然后用After 行触发器锁定对应的远程行。所有站点都提交事务后,Oracle 会释放锁。可以想象,如果多个站点要同时修改同一个资源,就会出现死锁。除此之外,同一个资源每次只能由一个实例站点进行修改,其它站点则必须等待。
这种方案的优点是避开了分布式锁,具备高度的数据一致性,实现简单且易于管理。
这么做的缺点则是,本地和远程短暂的锁定可能会带来死锁问题,还有比较差的写入性能,而且需要高可用性和高速的网络,因为分布式事务需要复制同步性和两阶段提交(2PC)。
高并发情况下死锁会是很严重的问题。发生死锁的时候,Oracle 会回滚非法的那个事务,保持另一个。回滚的事务会给前端应用返回一个错误码。
由于第一节提到的原因,这个方案只适用于“DATS 改”。步骤三必须等待步骤二释放本地和远程的锁。步骤三拿到锁之后,会看到那张票已在步骤二售出。
3. 使用本地锁和本地事务的同步复制
TimesTen 的单向 Active Standby Pair 配置只使用了所谓的“return twosafe 复制”。它支持主站点(活动站点)和订阅站点(备用站点)之间完全同步的复制。
TimesTen 不涉及分布式事务或分布式锁。只使用本地事务和本地锁。具体来说,主站点的事务提交之前,会先提交订阅站点的本地事务。如果订阅站点不能提交,主站点也不会提交。
任何时候都只能更新活动站点,这大大简化了数据更新的复杂度(否则的话,使用本地锁和本地事务都还不够),也确保了在活动站点失效的情况下,能快速失效转移到备用站点上。
这个方案的优缺点和第二节那个方案的优缺点类似。
不过它的性能要更好一些,因为它规避了分布式事务所需的两阶段提交。由于只允许活动站点进行更新,这个方案也消除了死锁问题。
虽然备用站点看起来是一种功能浪费,但你可以把备用站点和另一个活动站点放在一起,如图 1 所示(尤其是活动站点和相搭配的备用站点有着不同的数据)。
这个方案的数据一致性并不是很高,因为主站点若是提交失败,即便订阅站点提交成功了,也会导致不一致性(根本原因是这个方案没有使用分布式事务。但你也应该知道,两阶段提交的第二次提交或回滚阶段要是失败了,也会导致暂时的数据不一致)。
TimesTen 在这个地方的做法,延续了他们在异步日志记录、使用后写策略的数据缓存等方面偏重高性能的配置思路。Gigaspaces IMDB 采用了一种非常类似的拓扑结构,叫做主 - 备份复制。唯一的区别在于,Gigaspaces IMDB 使用了分布式事务,而不仅仅是本地事务。所以和 TimesTen 比起来,Gigaspaces IMDB 有更高的数据一致性。
使用 Gigaspaces IMDB 的另一个好处是,Gigaspaces IMDB 的失效转移对最终用户来说是透明的,而 TimesTen 的用户仍然需要求助于第三方或定制的集群管理软件。
由于第一节提到的原因,这个方案只能应用于“DATS 改”。位于纽约的两个站点,其一是活动站点,另一个则是备用站点要连接到活动站点上更新数据。活动站点上的本地锁会防止超卖的情况发生。
和前面两个同步方案相比,强烈建议使用这个方案和图 1 所示的数据分区,原因有:
- 这个方案大大简化了数据更新的复杂性,同时还提供了高可用性;
- 尽管前两个同步方案允许在任何地方更新数据,但更新同一个资源意味着需要网络上的锁协调和分布式事务。可伸缩的更新通常通过数据分区来实现;
- 虽然前两个同步方案允许分布式和可伸缩的读取操作,但你仍然可以对分区进行微调,允许更多的并发读取。
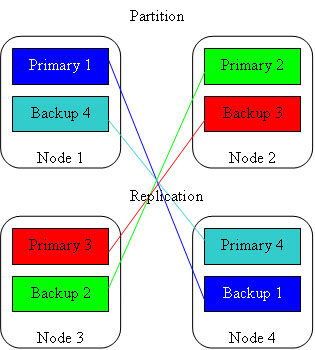
图 1:Gigaspaces IMDB 中的主 - 备份分区
4. 随处更新的异步复制
Oracle 多主复制的另一种数据一致性协议是异步复制,异步复制允许用户在任何参与站点更新数据。这个方案也用在 Oracle 的可更新物化视图复制和 TimesTen 双向的主 - 订阅者复制中,处理一般的分布式工作负载。
使用这个方案,一个站点上的数据变化会在本地提交,并存储在队列中,以便传递到其他站点。队列中的变化会在一个独立事务里分批传递,所以它不需要使用分布式锁或分布式事务。相反,它只在相应的本地事务中使用所需的本地锁。
这个方案具备良好的读写性能、易于实现、适用于低速的局域网和广域网,适用于网络断开的更新。特别是广域网部署能让地理分散的数据中心的做到真正灾难恢复。
缺点则是数据一致性取决于数据刷新的频率,比较有限,而且可能会有数据变更冲突。
由于不涉及分布式锁或分布式事务,如果不同站点发起的两个事务差不多同时去更新同一行内容,就会出现复制冲突。(当队列里的更改传播到另一个站点的时候,另一个站点上的数据变更会有两个版本。在这种情况下,应用需要决定应该用哪一个。)
必须提供解决冲突的方法来处理数据的不一致性。Oracle 和 TimesTen 都预置了一个“最新时间戳”的解决方法,以时间戳最新的修改为准。Oracle 还允许你根据业务需求定制解决方法。
要是 DATS 不允许出现超卖情况,这个方案就不适用于 DATS,因为纽约站点和洛杉矶站点的变更可以在两个不同的事务中单独提交,这会导致两名顾客购买同一张票。
如果允许偶尔出现超卖情况,纽约站点和洛杉矶站点可以利用三小时的时差在不同时间出售机票。要真的出现复制冲突,应该根据前端应用采取的措施把相关信息记录到数据库中(现实里的预订系统并不会采用这种方案)。
5. 只更新主站点的异步复制
Oracle 的只读物化视图复制、TimesTen 的单向主 - 订阅者复制、Gigaspaces IMDB 的主 - 本地复制都使用了这种方案。
笼统地说,当你使用乐观锁创建多个数据库会话的时候,就等于用了这个方案。首先在一个会话里进行查询,返回的实际上是数据库主数据的副本。接着当你要保存所作的更改,就把它们持久化到后端的数据库中。
由于只在主站点进行变更,所以分布式锁和分布式事务根本用不上。这个方案的利弊和第四节介绍的方案类似。不过鉴于只允许在主站点进行更新,这就消除了臭名昭著的复制冲突,在异步复制环境中,这个设计在大部分情况下都是非常完善的。
我们要是在原始 DATS 设计里采用这个方案,并假设纽约站点或有第三个站点充当主站点的话,如果洛杉矶首先获得了主站点的本地锁,纽约站点就必须等待。主站点的本地锁会防止超卖的情况发生。
和第三节结尾处讨论的内容类似,推荐采用本方案时同时采用数据分区。DATS 可以通过分区得到增强,例如让纽约负责东海岸的航班、洛杉矶负责西海岸的航班。
使用图 2 所示的 Gigaspaces IMDB 主 - 本地拓扑结构能让事情变得更加简单,因为这种拓扑能自动把本地缓存更新到主站点,主站点则会把同样的更新再传播到其他本地缓存里。Gigaspaces IMDB 也支持版本化的乐观锁。
不论你使用 Oracle 的只读物化视图复制,还是 TimesTen 的单向主 - 订阅者复制,你都要自己处理这些问题。
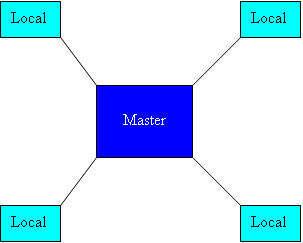
图 2:Gigaspaces 的主 - 本地拓扑,图 1 的内容可以充当主站点
6. 结论
数据复制大致可分为同步和异步。同步复制能确保高度的数据一致性,但需要昂贵的高可用性和高速网络。同步复制通常用来保护关键任务的数据,比如金融业的数据。
异步复制提供了更好的写入伸缩性,但会降低数据一致性的程度。通常用异步复制均衡写入操作、提供灾难恢复。
每种复制类别都有好几种方案,提供不同的并发控制。即便合适的方案取决于特定的业务需求,我们还是建议使用第三节和第五节讨论的方案。
最后,读者朋友应该注意两点内容:一是还有一些有趣的复制方案这里并没有提及。比如用 TimesTen 的“return receipt 复制”和 MySQL 5.5 实现的“半同步复制”,还有 Gigaspaces 数据后写功能对同异步复制的结合采用。
另一个需要注意的是 NoSQL 目前的发展趋势。由于大部分 NoSQL 产品都自夸有可伸缩的能力,而且都假设失败必然发生,所以他们依靠数据复制来保证读写操作的负载均衡和高可用性。本文只会提到三个比较典型的NoSQL 实现。
CouchDB 构建在 Erlang OTP 平台上,借助双向的异步增量复制,CouchDB 允许进行分布式、甚至是连接断开的文档更新。
Cassandra 允许跨数据中心的复制,也提供了不同程度的数据一致性。
最后,Gigaspaces 作为 IMDB 运行,依靠复制实现高可用性和后写功能,降低了传统关系数据库的重要性。除了原有的键值映射接口,最新的 8.0 版本还支持一种新的文档接口。
资源
[1] Wikipedia 上的复制
[2] Oracle10g 高级复制
[3] Oracle10g RAC
[4] Oracle10g TimesTen
[5] Gigaspaces IMDB 7.1
[6] Oracle 10g Cache Fusion
[7] Wikipedia 上的分布式锁管理器
[8] Wikipedia 上的分布式事务
[9] WebLogic 对 Heuristic 决策的处理
[10] MySQL 的半同步复制
[11] Gigaspaces 用 Mirror 实现的同步持久化
[12] NoSQL 数据库列表
[13] CouchDB
[14] Cassandra
[15] NoSQL 模式
作者简介
** Yongjun Jiao ** 是 SunGard 全球服务业务部的一名技术主管,有十年的专业软件开发经验,专长于 Java SE、Java EE、Oracle、应用调优、高性能和低延迟计算。

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论