
编者按:本文系 InfoQ 中文站向华先胜先生的约稿。
为区分人和计算机,互联网上的很多服务都使用了验证码技术,例如电子邮箱申请,银行系统登录,电子商务系统的交易确认,等等。虽然字符识别仍然是最常用的验证码方法,但是基于图像语义识别的验证码逐渐出现在一些重要的互联网应用上,并引起了热议。一方面大家对其中的一些难题大力吐槽,一方面又有人号称能够破解,能够自动识别这些图像。那么,目前的图片自动识别技术到底有没有可能破解这种验证码呢?有没有更好的图像验证码方法,既安全又不影响真人的使用体验?今天我们一起来探讨一下这个问题(本文纯属笔者个人思考,因见识、能力有限,错漏之处难免,还望阅者见谅)。
验证码的由来
验证码的学名叫做 CAPTCHA ,是 Completely Automated Public Turing test to tell Computers and Humans Apart 缩写,意为“全自动区分计算机和人类的公开图灵测试”,也就是一种用来区分人类和计算机的方法。通常是由计算机生成一个对人类而言很容易而对电脑而言非常困难的问题,能回答者被判定为人。
验证码测试其实不是标准的图灵测试,因为标准图灵测试是人类来考计算机的。通常的人工智能研究者的目标是让他们设计的系统通过图灵测试,让人类无法区分对方是人还是机器,从而说明人工智能能够接近人类的智慧。常用的图灵测试是对话,当然不是面对面对话,而是“键盘对话”,不然当然知道对方是人是机器了。通过这个测试当然并非易事。直到 2014 年 6 月份,英国雷丁大学宣布来自俄国的 Eugene Goostman 聊天机器人在伦敦皇家学会举办的 2014 年图灵测试大赛中,首次通过图灵测试,骗过人类,让人类认为“他”是一个 13 岁的男孩。其判断标准是:5 分钟内的一连串键盘对话,让 30% 的人认为它是真人。当然,图灵测试还有其他的任务和方式,例如最近在《科学》上一篇论文讨论如何让计算机象人一样从一个手写的字,“只看一眼”,就能学会象人一样写这个字,而让其他人无法区分是人写的还是计算机写的 [1]。
与之相对,验证码是计算机出题来考人类(当然,这个题目怎么出,也是由人来设计,然后计算机自动产生的)。验证码的目的是不让计算机通过验证,从而阻止人们用计算机做其不应该做的事情。通常这些事情如果用计算机程序来做,可以做到数量很大,或者速度很快,或者兼而有之,从而破坏正常用户的使用秩序。例如注册大量免费电子邮箱来发广告邮件,在微博等社会化媒体中注册大量虚假用户作为某人的“僵尸粉”,以及自动抢票软件,等等。
早期的验证码大多用扭曲的文字来实现,用以避开 OCR(自动光学字符识别技术)的自动识别,例如 Yahoo 早期的验证码版本 EZ-Gimpy。后来,又有在扭曲字符上加曲线,以及将字符拥挤在一起,有时让真人也难以识别。

图 1:不同的字符验码(Credit: Wikipedia)
验证码的基本要求
一个好的验证码方案的特点很简单:人容易识别,而机器无法识别。严格来说,如同密码方案一样,验证码产生的算法应该公开,从而能够公开验证算法的安全性,但在实际使用中一般鲜有这样做的。在电子邮箱申请等这种典型的需要验证码的场景,还要求验证码的答案可能性(解空间)足够大,从而让猜测的成功率也极低。例如,如果有哪怕 1% 甚至更小的几率能猜对,也不能有效防止机器自动注册大量邮箱来发送垃圾广告邮件。例如,一个四个数字的验证码,10000 种可能的结果,在没有任何智能的情况下,计算机能猜中的概率是 0.01%,如果再加上一些智能,把猜中的几率提升到 1%,则不能有效防止机器自动注册电子邮箱。如果是 16 个英文字母,则解空间的大小是 52 的 16 次方,这时能猜中的概率就极低极低了。
当然,有些场景的验证码并不需要太大的解空间,特别是对实时性要求比较高和服务比较复杂的系统(例如在线交易),因为破解程序比较难以在短时间内产生高 QPS 的攻击。不过,解空间太小,可能会被事先离线穷举,而在线则通过匹配就可以找到答案。对此,我们后续再进一步讨论如何设计更好的验证码,我们先看看为何用图像识别做验证码。
关于图像识别验证码
图像识别验证码在十几年前就有人尝试了。图像验证码的一个好处是不需要人键入识别出来的文字,只需要点击对应的图片就可以了。其关键还是要解空间足够大,并且机器算法基本无法完成。例如,在 2003 年,微软研究院提出一种利用人类对人脸区域的敏感性,将人脸进行变化,包括头部的旋转、变化的光线、复杂的背景等等,使得计算机人脸检测算法会失败,而人类可以轻松的指出人脸的位置 [2]。

图 2:人脸验证码(Credit: Yong Rui, etc.)
2009 年,有一个叫做 VidoopCAPTCHA 的图片验证码,与现在大家看到的图像验证码类似,其区别是每个图片中有个字母,要求用户按提示输入与提示词对应的图片的字母。不过,当年就被哥伦比亚大学的一个学生破解了,现在已经没有人使用了,这个叫做 Vidoop 的公司也不存在了。2010 年前后一个叫 Confident Technologies 的公司研发出了和现在流行的图像验证码更为相似的验证码。不同的是,它要求用户进行三次识别,每次只有一个答案是对的。目前互联网上有 139 家网站使用的是这个技术。

图 3:Confident Technologies 的图片识别验证码
通常图像验证码系统给的提示文字不想图 3 中“flower”那么简单好认,而是变形了的文字,也就是说,也是一个嵌入的文字识别验证码。换句话说,图像识别验证码中的提示文字是个文字识别“验证码”,尽管只需要人认出来而不需要人键入。文字识别验证码技术和可能的攻击超出了本文范围,因篇幅有限就不做讨论了。
那么计算机自动图像识别技术到底能否破解这种验证码呢?如果可以,是如何实现的呢?在讨论这个问题之前,我们看一下图像识别技术到底发展到了什么境地。
什么是自动图像识别技术
图像识别在学术界已经被研究了几十年,从大约 50 年前就有人提出让计算机外接相机来识别相机看到的东西(图灵奖得主 Marvin Minsky)。这个见地在今天似乎没有什么,但是在 50 年前提出则相当不易 - 试想,如果让我们预测 50 年后的技术,甚至 5 年后的技术都不太容易的。
图像识别方法可以分为两大类,模型的方法和搜索的方法。模型的方法是在业界研究和使用最多的方法。模型的方法是试图通过一些已知“标签”(也就是这个图像是什么,例如图 3 中的第一幅图的标签是“小汽车”)的图像,通过机器学习的各种方法来学习一个描述这些标签的“模型”,从而,对于一个新的未知图像,经过这个模型判断出其应该具有的标签。
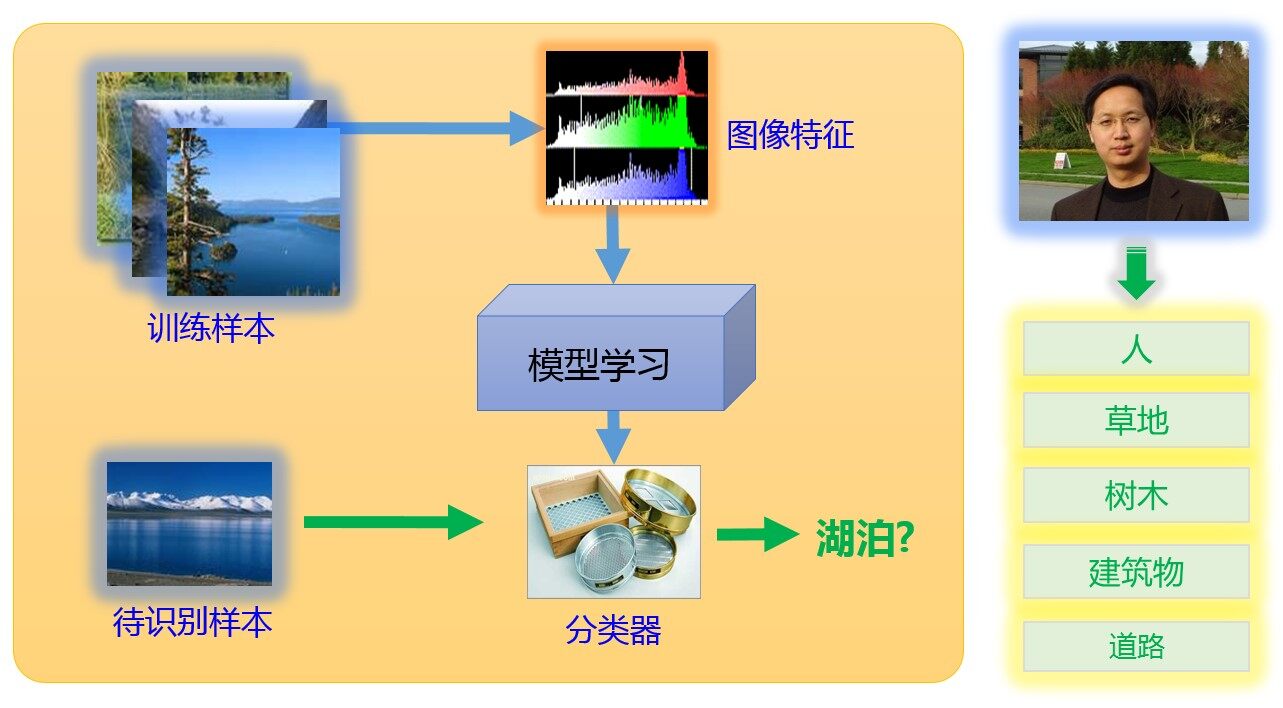
图 4:基于模型的图像识别示意图
基于搜索的方法是在大数据时代才出现的方法,其基础是将已知标签的图像数据建成一个可以进行高效率检索的数据库,称为图像索引。通常需要大量的图像来建索引,但图像的标签可以有少量的噪声。那么,对一副待测图像,我们到这个数据库中去找与其相同或者相似的若干图像,然后综合这些图像的标签来预测待测图像的标签。
当然,这两类方法究其本质并无差别,只是搜索的方法利用了大规模图像索引的技术,不去建立模型,而是直接用这些数据来进行匹配,所以我们可以认为这个大的索引就是一个特殊的模型。在大数据的时代,识别和搜索已经密不可分,精准的搜索离不开识别,广泛的识别也离不开搜索。笔者在很多报告中也经常把识别和搜索放在一起来讲。
自动图像识别有多牛
比较靠谱的图像识别方法是从上个世纪末 SIFT 图像特征的提出开始。在之后的十几年里,研究者们大多是从特征和模型来进攻这个难题。例如,特征上,SIFT 和 HOG 等,模型上 SVM,Boosting, DPM 等。2012 年前后,深度卷积神经网络在图像识别领域开始应用,则是同时去解决模型和特征的问题。也就是,既可以通过深度学习直接从图像像素开始训练图像识别模型,也可以通过同样的训练得到图像的更有效的特征描述,然后采用传统的机器学习模型来训练识别模型。基本上,深度学习的方法击败了所有传统的方法,使得图像识别的准确率向前迈了很大一步。
ImageNet 图像识别(分类)是最有影响力的一个公开 PK 图像识别算法的比赛,其最基本的任务是训练一个 1000 类的图像识别器。在深度学习方式使用之前,最好的识别“前 5 准确率”(也就是给待测图像预测出的前 5 个标签中有一个是对的)只有 74% 左右,而深度学习第一次就将这个结果提升了将近 10 个百分点,到达 83.6%。而最新的 2015 年的最好结果达到了96.3%。
但是对于一个希望能实际应用中使用的图像识别系统,还有三个方面:数据、系统和用户反馈。真实世界不只是1000 类图像,如果每一类都需要大量的标注图像,这个工作量还是相当大的。例如,世界上大概有900 多种不算很难见的花卉,有500 种左右纯种的狗,大约50000 个城市,淘宝上有超过10000 种实物商品。因此,也有研究者开始着手如何高效甚至自动或半自动创建数据集。而系统方面的要求,是保证模型的训练在可控的时间内完成,并且图像识别则可以在非常快的时间(例如数十毫秒)内完成。用户反馈的使用,则是一个识别系统在使用的过程中,不断吸收用户的使用行为数据来逐步改进识别系统的准确率和覆盖率。
总结起来,衡量一个图像识别系统的性能可以从如下四个方面来看:
(1)准确率:衡量是否能正确识别图像中的内容,这也是多数人关注的目标,包括ImageNet 比赛;
(2)覆盖率:衡量能识别多少种语义,这个在学术界比较少有人关注,却对一个识别系统能否在真实场景中应用起着很关键的作用。工业界,例如各大搜索引擎公司(微软、谷歌和百度)提供的识别API 则能识别更多的内容(大概在万这个量级上);
(3)效率:主要是衡量多快能够识别出结果,也包括多快能够训练或更新一个识别器;
(4)用户体验:在产品和用户界面上的考虑,如何弥补识别的准确率、覆盖率或效率的不足。
举个例子:笔者一年前曾经研发了一个称为Prajna 的系统[3],用自动训练数据获取和清洗的方法,自动快速训练过很多的图像识别器,包括狗的品种,花卉,植物,地标,食物等等。其自动数据获取的方法比较有利于解决覆盖率的问题,而不需人来标注数据,使得产生一个新的识别器的周期变得很短,只要数小时到两三天的时间。有一次,笔者去参加朋友家里的一个聚会,主人家里有一株很漂亮的花,参与聚会的朋友们这都想知道花的名字,可惜主人也忘了。于是,我启动我研发的花卉识别器,成功地识别出了这株花(见下图)。当时很多图像识别程序只能识别出其为一种花,而不能知道其具体名称。这个也说明了实际应用系统中,“覆盖率”是相当重要的。

图 5:笔者的图像识别系统 Prajna 识别出这是“Amaryllis(孤挺花)”
那么,有了这些图像识别领域的最新进展,是不是就能破解现今一些网站的图像识别验证码呢?在讨论这个问题之前,我们看看图像识别除了可能可以破解验证码,以及在某些场合能够识别人不能识别的物种,还能干什么更有意义的事情呢?
图像识别还能做什么
笔者在图像识别和搜索领域摸爬滚打近二十年,以此经验,笔者认为目前最有实际用户需求的图像识别应用之一应该是商品的识别和搜索(如前所述,如今识别和搜索常常是密不可分)。其中典型的应用场景就是通过拍照的方式寻找需要的商品,例如亚马逊的FireFly 和阿里巴巴的拍立淘。笔者是拍立淘算法的研发主管,在此简要介绍一下图像识别在拍照商品搜索中的应用。限于篇幅,只能非常简略地介绍一下,希望有机会另文介绍图像搜索技术的前世今生,以及拍立淘中的前沿技术和有趣应用。
在拍立淘中,对于用户拍的商品照片,我们首先要识别其大概的类别,例如,是上装,还是裤子,还是箱包,还是零食,等等。然后我们需要知道用户关注的商品在图像中的位置,通常称为“主体检测”。再然后,就是产生一个该主体的描述,也就是特征,通常是一个高位向量。这个向量的产生方法则是通过训练一个多类商品的识别器来实现的。最后,我们用这个特征到一个建好索引的大商品库中去找与此相同或相似的产品,返回给用户。这些关键步骤,包括商品识别,主题检测,和特征提取,都是基于深度学习的方法来完成的。
为什么说这个应用场景是个“刚需”场景呢?一方面,确实有很多情况下,用户用文字无法描述心中所需,只能通过样例的方式来查找;另一方面,这个仍在不断改进中的产品每天已经有数百万的活跃用户,每天在之上产生的交易量近千万。
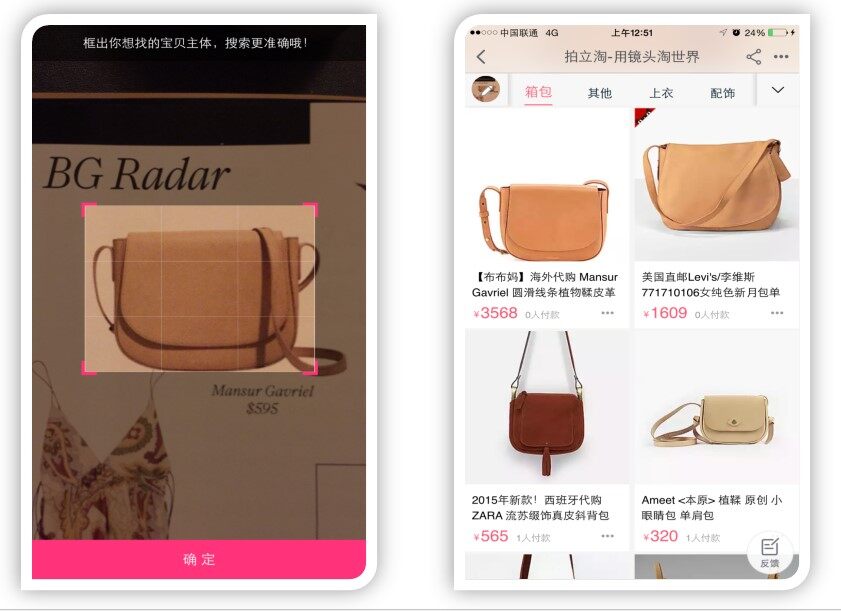
图 6:拍立淘商品搜索一例。左:用户拍的商品和自动框出的商品区域;右:识别结果(箱包)和搜索结果。
图像验证码真能被破解吗?
什么叫破解呢?是不是完全能识别所有的图片才能叫破解呢?其实不需要,如果能使识别准确率达到一定的数值就可以了,例如对于邮箱注册,一个很低的准确率就足以构成威胁,例如10%,甚至更低。对于在线购票系统来说,大概10% 左右也能构成很大威胁了(有网站统计表明,对于目前流行的图像识别验证码,真人的一次识别成功率只有8%)。
目前流行的图像识别验证码的解空间有多大呢?通常见到的是识别8 个图片,通常是1 个到3 个答案是对的(不知道有没有4 个的),那么可能的答案组合一共只有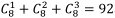 种可能,如果任意回答,由1/92(1.1%)的概率能答对(如果增加到1 到4 个答案可能对,则此概率降为0.06%)。也就是说,如果破解程序没有任何智能,92 次中才能有一次机会通过认证。当然这种概率如果用来防止邮箱注册大概不太有效,但对于在线交易等一些秒杀场景,还是有效的。
种可能,如果任意回答,由1/92(1.1%)的概率能答对(如果增加到1 到4 个答案可能对,则此概率降为0.06%)。也就是说,如果破解程序没有任何智能,92 次中才能有一次机会通过认证。当然这种概率如果用来防止邮箱注册大概不太有效,但对于在线交易等一些秒杀场景,还是有效的。
如果有自动识别程序帮助呢?如果类目数不是太多(例如只有几百个),我们找到这些可能的物体类别后,训练一个对于图像的自动识别器并不是不可能(在此就不详述方法了)。当然,前提是能自动识别提示文字,不过这个问题通常比图像识别相对容易些,虽然提示文字也有些变形(如前述,字符验证码的技术不在本文讨论之列)。假定我们的“前1 识别率”(就是第一个识别出来的物体名称就是对的)是30%,那么3 到4 次就有一次能识别对,这个成功率足以对验证码系统造成威胁。用谷歌、百度或微软的识别API,也是一种方法,但这些API 并没有优化到这些类别上,应该不会有专门为这些类别训练的识别器准确率高。
有人提到过用图像比较的方法破解,也就是通过多次试用,将验证码后台的所有或大多数物体图像爬下来,人工标注,然后在线验证时直接比对即可。这种方法也是不错的思路,但也是需要由图像检索的专业人士才能真正实现,因为这里涉及到两件事情,一是合适图像的特征描述(如果直接用图像像素,图像加噪声后,比对方法就失效了),二是索引技术,以保证快速的查找(如果后台图像不太多,则此步可免)。
那么,图像验证码就没有出路了吗?当然,上面提到的方法只是对理想情况下的破解思路,一个验证码系统可以增加很多变数和限制,使得破解更为困难。不过,增加题目难度的方法是违背验证码初衷的,试想如果普通人也难以识别的东西如何用来区分计算机和人呢?
笔者凭经验给图像识别验证码支些招,基本的思路仍然是:(1)题目对人容易,对机器难;(2)解空间足够大;(3)当前的图像识别方法不能很好解决。可能的方法有:
(1)将待识别小图加复杂背景,并融合成一张无缝的图;
(2)多用识别算法容易混淆的相似物品;
(3)不断改变背景的模式和拼图的方法;
(4)物品前景加一些干扰;
(5)增加一些细分物体类别;
(6)除物品识别外,引入属性识别要素;
相信如果验证码采用上述几个大招,破解的难度会增加很多倍,即使是图像自动识别专家也要费一番周折才能解决,或者一段时间内根本无法解决,也就没有去攻关解决的价值。等技术进步了,就再更新换代,让破解者跟不上出题人的步伐。举个例子,只使用其中部分方法,大家可以看看,如果验证码长成下图这样,人应该还能识别(我找我8 岁的儿子测试,大概2 秒钟都能正确识别),反正机器大概是不容易搞定了(当然不是只是这一个情形,而是类似的大量情形) :)

图 7:验证码问题:点击坐着的人的红色上衣。什么,不够难?那就点击图中看起来最小的那个水杯。
其实还有一个简单的大招,就是充分利用这个验证码系统,快速地增加和迭代系统的数据,使得破解者望尘莫及(笔者就卖个关子不详述方法了,内行者读到这里自能知晓)。
图像识别的未来
我们再回到图像识别的正向使用上来。虽然图像识别有了很大的进展,但是真实世界的图像识别仍然有很多困难。如前所述,在相对不大的集合上(例如ImageNet 一千类识别),经过几年的努力,其识别准确率提升很快。但是,真实世界是很复杂的,在更多的场合下需要识别的覆盖率、准确率都要高,而且速度要快。笔者以为,只靠模型和特征的方法是不能完全解决的,未来的解决方法应该是模型、特征、数据、系统以及用户反馈这五个要素的综合作用,才能逐步达到理想的识别效果。
[1] BM Lake, et al. Human-level concept learning through probabilistic program induction. Science. Vol 350, no 6266, pp 1332-1338.Dec 11 2015.
[2] Yong Rui, Zicheng Liu. Excuse me, but are you human? ACM Mulitmedia 2003
[3] Xian-Sheng Hua, Jin Li. Prajna: Towards Recognizing Whatever You Want from Images without Image Labeling. AAAI 2015.
作者简介:华先胜,IEEE Fellow,ACM 杰出科学家,TR35 获得者,阿里巴巴研究员 / 资深总监。2015 年加入阿里巴巴搜索事业部,负责大数据多媒体内容分析及图像搜索算法团队。在此之前先后在微软中国研究院、微软总部 Bing 搜索引擎以及微软美国研究院任主管研究员、首席研发主管以及资深研究员。2001 年北京大学博士毕业,一直从事图像、视频内容分析和搜索方面的研究和开发工作。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论