
Amazon 的云业务规模已经今非昔比,而它发展新功能、新服务和新选项的速度比其他竞争对手都要快。近日,InfoWorld 撰稿编辑 Peter Wayner 撰写了一篇评论文章,他认为通过为复杂、高扩展性、数据丰富的应用提供最简单的创建方式,AWS 正在蚕食互联网。
Amazon 提供了许多分析大数据集的复杂工具的云版本,如 Hadoop、Spark 和 Elasticsearch,藉此不断上移堆栈。而这些工具正在改变程序设计员和数据分析师的游戏规则——与其不停编写新代码,不如将 Amazon 的各种高端服务连接在一起。当原始计算能力仍然还是传统的关注焦点时,Amazon 的这些新工具、新服务已经在强制推行自身的价值主张。这无疑将程序设计员和数据分析师们带到了一个难以抉择的十字路口——编写代码赋予他们畅行无阻的自由和能力,但将越来越多的堆栈托付于 Amazon 明显更便宜,而且更快。
Peter Wayner 从以下几个方来阐述以支持他的判断。
机器的海洋
Amazon 云的核心仍然是被称为亚马逊弹性计算云(EC2)的虚拟服务器的集合。如果你想有一台机器,你可以去 AWS 的网站获取权限。然而,越来越多的人,甚至机器人(云变得越来越自动化)都在使用 API。如果你不只是要启动单个试验实例,你最好停下写代码,启动你的机器。这里有针对各种语言的 SDK,Java、 .Net、PHP、Python,甚至 Google 的 Go 语言。
Amazon 出租的机器范围越来越广,也越来越复杂。至少有 9 个通用类别的可用实例——这还只是考虑了列在“当前阶段”的机器。如果你的软件出于某种理由似乎有需要,你仍然可以租用早期硬件系列的实例。机器的每个通用类别在配置不同内存和本地磁盘存储的不同模式下都是可用的。
(点击放大图像)

当配置一个Amazon EC2 实例,你会得到一个迅速增长的可选项名单。
Amazon 实例类型名单的可选项实在太多了,我们凡人无法一一检查和探讨。比如 i2.8xlarge,自带 224GB 内存和 32 核虚拟 CPU,可以提供 104 个弹性计算单元(ECU)——Amazon 用来测量机器功率的度量标准。d2.8xlarge 则自带 224GB 内存和 36 核虚拟 CPU,可以提供 116 个 ECU。
这些实例使用不同的英特尔 Xeon 版本,而且它们还仅仅是几十个选项中的两个。那到底该如何做选择呢?如果你有一个重大的项目,你会想用一系列实例类型来基准测试你的代码,并计算出你的应用程序到底运行得有多快。如果你只是为偶尔的工作租用几台机器,就没有必要考虑太多。但是如果你是为了多个大型项目同时运转上百台机器,基准测试则是最佳方案。毕竟,ECU 的度量只是一个使用了某些标准基准测试的平均值,实际的情况可能会有所不同。
决策,还是决策
对硬件的选择才刚刚开始。随着 Amazon 越来越多地了解到哪个点会出错,它逐渐增加了可选项的数量,而 API 反映了这个经验。现在可以藉由一个点击按钮“启动终止保护”,当你在正在运行的机器上删减实例名单时,这个安全开关可以防止你误删。这多少让 Amazon 云生活变得稍微轻松点儿——不是简单点儿。
在你决定要怎样支付的时候更加棘手的问题就来了。你可以立刻租用,全款支付,或者开始钓鱼,等待更低的费率。Amazon 提供了一个现货市场,你可以在这里出价竞买多余的容量,而市场会随着需求的涨落而波动。通常一些大的视频流业务会在周五和周六的晚上取代云业务,这会让波动相当具有戏剧性。
节省的钱可能多得惊人,等待过程中的价格也可能远低于标价,但你没办法知道最终的成交价会是多少。但如果中标价高于你的最高报价,你的机器就停工了。
(点击放大图像)

Amazon 为软件开发者提供自动化创建、测试和部署周期的工具。它也通过为正在着手部署的代码提供存储与 GitHub 竞争。
你可以为了质保多付一点钱,但价格仍然可能远低于正常价格。
拍卖并非唯一的定价模式。如果你看重稳定性胜于弹性,还有其它更多选择。如果租用一年,或者甚至三年,只要锁定价格,并全款预付,便可以轻松节省 30%、40% 或多达 60% 以上的费用。
这一切意味着你的会计师和你的程序员一样重要。你会希望他们都坐下来设计架构,以最低的成本达成对资源最有效的利用。
云创新
很多云服务都源自 Amazon,如 MapReduce、数据库存、流处理。直到现在,竞争者们才开始模仿 Lambda——Amazon 的无服务器事件驱动计算服务。没有哪个云竞争者拥有可以匹敌 Aurora——Amazon 改装后的 MySQL 服务,或者 Amazon 数据库范围服务的对手。
即便是模仿竞争者,Amazon 也在持续创新,Elastic Beanstalk——Google App Engine 的 Amazon 版本,是一个软件包集合,可以自动化创建根据需求增加或减少的机器集群。这是一个更加通用的系统,用以支持一些常见的用 Java、.Net、Python、PHP、Node、Ruby 与 Go 写成的应用程序的服务器平台。脚本会自动设置负载平衡器和机器,根据需要开始或停止基础的 EC2 实例。
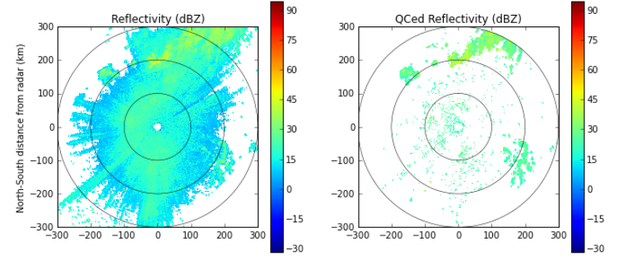
Amazon 主持了几十个公共数据集,包括气候数据、地理数据、人口普查数据、维基百科流量统计,乃至 Enron 邮件。上面的 Nexrad 雷达图像来自 Amazon 公共数据集,捕获于美国政府天气雷达系统。
Beanstalk 与其说是一个像 Google App Engine 一样的单独的全方位架构,倒不如说它更像是一个看门人。它在通用 EC2 实例上运行你的代码,而通用 EC2 实例会出现在你的机器列表上——如果你注意到有新的实例启动,一定要留心,这很重要。如果你不小心误删了实例,可以信任 Beanstalk,它一定会忠实地帮你找回来。所以,当你真的决定删除什么的时候,一定要记得关掉它。
Elastic Beanstalk 名义上是免费的。你不用为它的服务支付任何额外费用,但需要为你启动的 EC2 实例付费。
Amazon EC2 容器服务采取了和 Docker 容器同样的方法。Amazon 有自己的小代理,可以为你的容器启动 EC2 实例,然后安装 Docker 容器。除了底层资源,你无需为容器服务付费。
越飞越高
不是所有的工具都会为了租出更多的机器而免费提供。Elastic MapReduce 的集群实例是 Amazon 基于 Hadoop 的工具包,花费就要比基本 EC2 的标价贵上大概 25%。Amazon 已经创建了一个相当标准的主流工具包(Spark、Hadoop、Presto、Pig、Hive),并将它们与 Amazon 的 S3 存数系统整合。如果你正在 Amazon 云计算平台的其它部分生成日志或处理数据,使用一个 Elastic MapReduce 群集进行分析就十分合乎情理。毕竟,将原始数据导出 AWS 既需要时间,又耗费宽带。
Amazon 也在通过提供答案而不是计算资源在堆栈中走高。当微软 Azure 在为数据科学家提供一套更完整的机器学习工具时,Amazon 已经让开发者或业务分析师的机器学习变得更为简单。最终, Amazon 也会将分析数据卖给你。
云最有意思的新增元素之一是Amazon 正在为我们收集的公共数据。举个例子,你可以从一个由160 个高分辨率多普勒雷达站组成的网络中反复咀嚼雷达图像——这些雷达站每5 分钟提供一次降水和大气运动数据。Amazon 正在建立一些大型公共数据集,希望它们可以吸引租用EC2 实例提问的项目。
类似这样的服务显示了Amazon 计划如何构建未来的云。这家公司已经掌握了提供产品的过程,而且在为解决广泛用户群的需要持续改进服务。现在有如此之多的选择,以至于它可以在你准备按下按钮租用机器——或者非机器产品之前,花费数个小时进行研究。
Lambda 和 Amazon Machine Learning 这样的新服务是洁净层,旨在将租赁的复杂性和配置 EC2 实例提取出来。毕竟,没有人真的想运行服务器。我们想要部署代码、收集数据和找出答案。可以预计,Amazon 将继续提高堆栈自动化,以提供可以屏蔽实际服务器的更高级别的服务。同时,Amazon 将继续提供最庞大的实例类型系列,以及最丰富的服务与选择,以使它们发挥最大效用。
感谢陈兴璐对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论