

转眼间,AI 编程神器 Copilot 已经发布一年有余,这一年,Copilot 改变了什么?真的给开发者带来帮助了吗?
2021 年 6 月 30 日,微软旗下代码托管平台 GitHub 推出了名为 Copilot 的 AI 结对编程工具,Copilot 的主要定位是提供代码补全与建议功能,可根据当前文件的内容和光标位置自动生成代码。
据了解,Copilot 由 OpenAI 的 Codex 系统提供支持。据 Copilot 网站称,Codex 模型由“互联网上的公共代码和文本”训练,“既能理解编程,也能理解人类语言”。作为 Visual Studio Code 的扩展,Copilot “将你的评论和代码发送到 GitHub Copilot 服务,然后它会使用 OpenAI Codex 来合成并建议个别行和整个函数”。
作为一款 AI 编程神器,Copilot 从诞生之初就争议不断。
拥护者认为它确实可以提高生产力,反对者认为它写的代码错误率高,开发者还需要花费额外的时间做代码审查。有的争议焦点集中在 Copilot 是否涉及侵权上——毕竟 Copilot 宣称的基于公开代码训练,其实是在未遵循开源许可证的情况下,肆意“抄袭”开源代码。
在 Copilot 正式发布一年之际,GitHub 对 2000 多名开发者展开了调查,以期了解 Copilot 到底改变了什么?
Copilot 大调研
结合调查与实验,GitHub 整理出一份 Copilot 在开发者群体中实际影响力的结论性资料。
GitHub 研究员 Eirini Kalliamvakou 在一篇博文中提到:由于 AI 辅助开发还是个相对较新的领域,作为研究人员,我们几乎找不到可供借鉴的早期成果。我们希望衡量 GitHub Copilot 的实际效果如何,而且在早期观察和用户采访之后,我们决定对 2000 多名开发者进行大规模调查,了解他们的使用体验和感受。
在设计研究方法时,我们主要考虑到以下三大重点:
立足整体关注生产力。在 GitHub,我们喜欢广泛且可持续地考量开发者的生产力及相关影响因素。我们使用 SPACE 生产力框架选择需要调查的具体方向。
考量来自开发者的第一手观点。我们开展了多轮研究,包括定性(认知)与定量(观察)数据,希望拼凑出可靠的真相。我们希望验证:(1)用户的实际体验,能否证实我们推断出的结论?(2)我们的定性反馈,是否同样适合更广大的用户群体?
评估 GitHub Copilot 在日常开发场景中的效果。在设计研究方法时,我们特别注意覆盖专业开发人员,并围绕他们在工作日内面对的典型任务进行测试设计。最终的调查结果,既有意料之中的发现,也有意外惊喜。
开发者生产力确有提升
除了加快开发速度之外,Copilot 还能给程序员带来哪些额外帮助?
调查发现:
开发者满意度有所提升。60% 至 75% 的用户表示,他们对现在的工作体验更满意,编码时的精神压力更小,而且 Copilot 能帮助他们更专注地达成令人满意的工作成效。
缓解精神内耗。开发者们报告称,Copilot 能帮助他们稳步推进开发流程(73%),并在处理重复性任务期间降低精力消耗(87%)。

速度也很重要
有近 90% 的开发者们表示,在使用 Copilot 时,他们完成任务,特别是重复性任务的速度更快了。这也符合 GitHub 在产品设计时做出的基本预期。
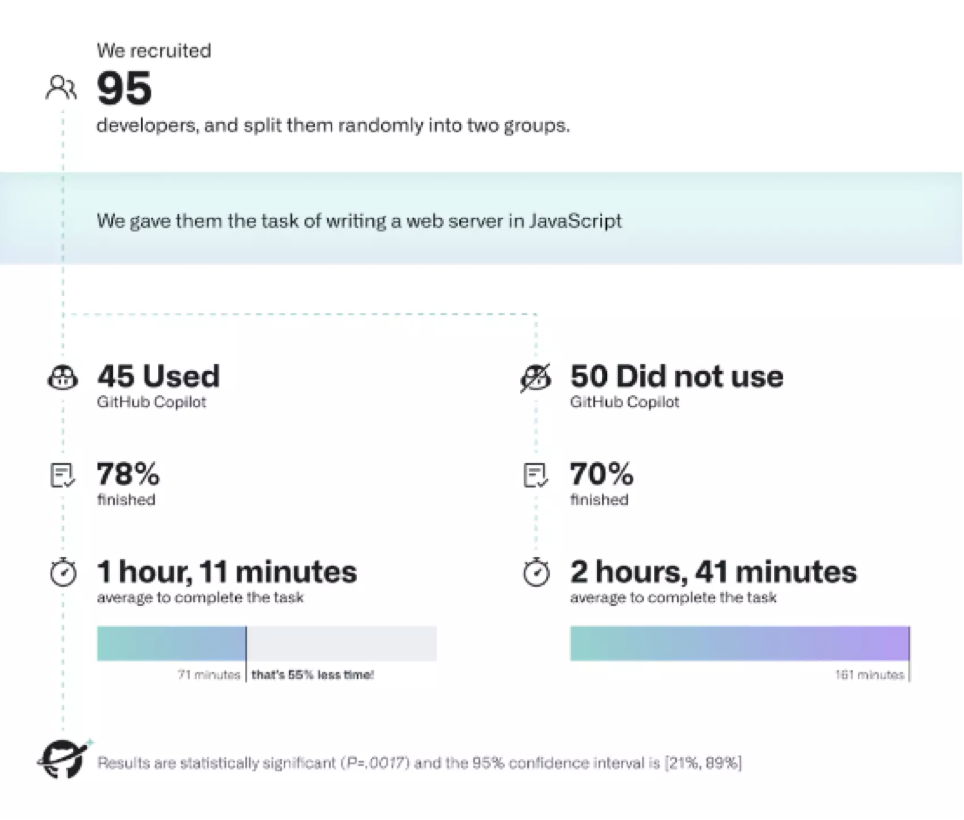
为了在实践中观察并量化这种提升效果,GitHub 组织了一场对照实验。两个受试小组(其中一组使用 Copilot)需要接受计时,核算用 JavaScript 编写 HTTP 服务器的平均用时。
实验发现:
使用 Copilot 的小组完成任务的比例更高,为 78%,未使用 Copilot 的小组完成任务比例为 70%。
更显著的区别在于,使用 Copilot 的开发者完成任务的速度明显更快,要比未使用 Copilot 的开发者快 55%。具体来看,使用 Copilot 的开发者完成此项任务的平均用时为 1 小时 11 分钟,而未使用 Copilot 的开发者平均用时达 2 小时 41 分钟。综上,该项调查和实验最终得出的结论是,“Copilot 有助于加快工作完成速度,帮助开发者减少精神内耗,以更加饱满的精神状态专注于工作内容,最终在自己的编码过程中找到更多乐趣。”
对于这一调查结果,有开发者留言表示支持: “使用 Copilot,我能尽量少把精力浪费在枯燥重复的工作身上。它点燃的灵感火花,让我感到编码过程更有趣、更高效了。”
GitHub 研究员 Eirini Kalliamvakou 表示,“随着 Copilot 的出现,我们在 AI 驱动型代码补全工具的探索道路上不再是孤军奋战。在实际生产领域,我们最近看到一项针对 24 名学生的评估,谷歌也在内部评估利用机器学习增强代码补全的可能性。
着眼于整个行业,研究社区正认真分析 GitHub Copilot 在各类场景下的实际影响,包括教育、安全、劳动力市场,乃至开发者的实践与行为。我们目前正在各类环境下观察 Copilot 的实际效果。这是个不断发展的领域,我们对研究社区和自身调查中的发现感到振奋,也将未来几个月内为大家揭晓更多消息。”
为什么 Copilot 会编写出糟糕的代码?
GitHub 的调研结果展现了 Copilot 在开发者群里中起到积极作用的一面,但任何事物都有其两面性,Copilot 本身带有的争议也不容忽视。开发者在决定是否采用 Copilot 前,需要对其有充分的了解。
其中,Copilot 比较大的一个争议点在于代码错误率高。
Copilot 由名为 Codex 的深度神经网络语言模型提供支持,该模型在 GitHub 上的公共代码存储库上进行了训练。它读取了 GitHub 的整个公共代码档案,其中包含数千万个存储库,汇聚了来自许多世界上最优秀程序员的代码。
那么,为什么 Copilot 还是会编写出糟糕的代码呢?
根据 OpenAI 的论文,Codex 只有 29% 的时间会给出正确答案。而且它编写的代码往往重构得很差,无法充分利用现有的解决方案(即使这些方案就在 Python 的标准库中)。
Copilot 编写出糟糕的代码,原因在于语言模型的工作机制。它们反映的是大多数人的平均写作水平。它们不知道什么是正确的,什么是好的写法。GitHub 上的大多数代码(根据软件标准)相当陈旧,并且(根据定义)是由水平一般的程序员编写的。
Copilot 尽力猜测的是,如果这些程序员正在编写的是你面对的这些文件,他们可能会写什么代码。OpenAI 在他们的 Codex 论文中讨论了这一点:
“与其他训练目标是预测下一个词符的大型语言模型一样,Codex 会生成与其训练分布尽可能相似的代码。这样做的一个后果是,这种模型可能会做一些对用户无益的事情”
Copilot 之所以比那些水平一般的程序员更糟糕,一个关键问题在于,它甚至没有尝试编译代码或检查代码是否有效,也没有考虑过自己是否真的遵循了文档的指示。此外,Codex 没有接受过去一两年内创建代码的训练,因此它完全没学过最新版本、库和语言特性。例如,提示它创建 fastai 代码后,它只会给出使用 v1 API 的建议,而不是大约一年前发布的 v2 版本。
值得一提的是,今年 4 月,微软推出了 AI 代码审查工具 Jigsaw,以期进一步提升 AI 编码的准确率。
在研究论文《Jigsaw:当大型语言模型牵手程序综合》(Jigsaw: Large Language Models meet Program Synthesis,文章已被国际软件工程会议 ICSE 2022 接收)中,微软介绍了一种可以提高这类大型语言模型性能的新工具。Jigsaw 中包含可以理解程序语法及语义的后处理技术,可利用用户的反馈不断提升修正能力。配合多模输入,Jigsaw 即可为 Python Pandas API 合成代码。
随着 Jigsaw 逐步在提高系统准确性方面发挥重要作用,Copilot 这类 AI 编程工具准确率或将获得提升。
活动推荐:
2023年9月3-5日,「QCon全球软件开发大会·北京站」 将在北京•富力万丽酒店举办。此次大会以「启航·AIGC软件工程变革」为主题,策划了大前端融合提效、大模型应用落地、面向 AI 的存储、AIGC 浪潮下的研发效能提升、LLMOps、异构算力、微服务架构治理、业务安全技术、构建未来软件的编程语言、FinOps 等近30个精彩专题。咨询购票可联系票务经理 18514549229(微信同手机号)。

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论