
近日,阿里云推出全新视频生成大模型 I2VGen-XL,并在魔搭社区开放体验,用户上传一张图片后 2 分钟左右即可生成一段 1280*720 的高分辨率视频。据介绍,该模型的训练还使用了多种风格的视频数据,可生成科技感、电影色、卡通风格和素描等类型丰富的视频。目前,I2VGen-XL 的模型和代码均已开源。
在此之前,阿里云曾推出 AI 绘画创作大模型通义万相(基座模型 Composer)和可控视频生成模型 VideoComposer,团队在该领域发表 60 多篇 CCF-A 类论文,并在国际顶级视觉竞赛中获得 10 余项冠军。
和 AI 绘画创作大模型相比,视频生成大模型的技术门槛更高,其需要克服文本和视频内容匹配度、视频画面质量、画面连续性等诸多技术挑战。在此之前,阿里云和微软等科技公司相继推出一系列可控视频生成研究成果,例如用户可通过定义空间布局、运动模式等条件来生成视频,但其画面清晰度难以满足真实场景应用的需求。
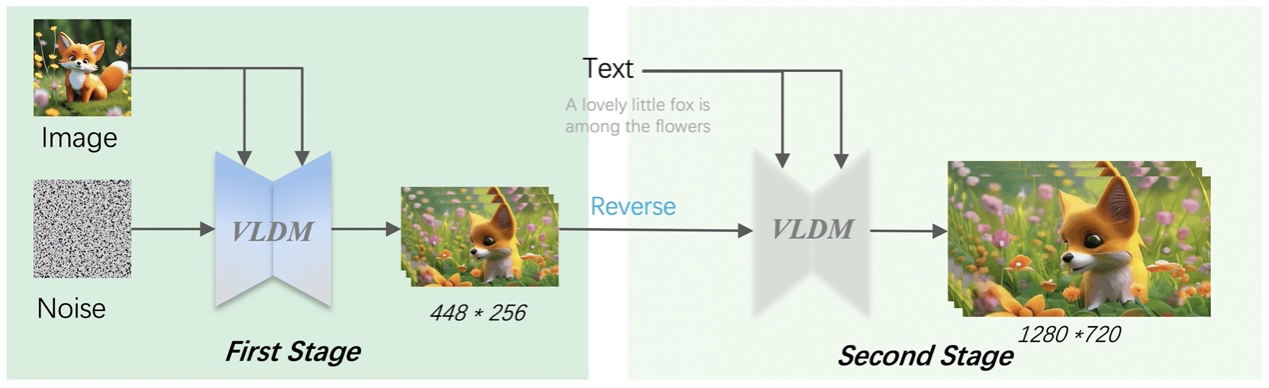
针对该问题,阿里云进一步提出创新思路,I2VGen-XL 模型设计了两个阶段:首先在低分辨率条件下保证生成结果和给定图像语义的匹配度,随后通过视频扩散模型(VLDM)来提高视频分辨率,并同时提升时间和空间上的一致性,保证最终视频内容的清晰度和连贯性,最终实现 1280*720 高分辨率的突破,并且在画面细节的展现上大幅领先现有模型。
I2VGen-XL 模型研发负责人表示,未来将进一步实现 2K 超清效果,可应用于短视频内容生产、电影制作等场景。
目前,I2VGen-XL 模型已吸引国内外用户和开发者的广泛体验和二次开发,涌现了大量创意 AI 视频生成内容,例如在城堡上展翅的恐龙、宇航员在飞船中行走的科幻电影画面等等……知名 AI 社交媒体分析师 Ahsen Khaliq 在推特发布多条由该模型生成的视频效果,并表示模型在清晰度、纹理、语义和时间连续性方面有优势。

模型体验地址:




