
几乎在同一天,Kimi 和 DeepSeek 同时交了“年度作业”。Kimi 分享了自称“满血版多模态 o1”的思考模型 k1.5,DeepSeek 推出了自己的第一代推理模型 DeepSeek-R1-Zero 和 DeepSeek-R1。
截至发稿,Kimi 1.5 在 Github 上只发布了技术报告,因此只有不到 300 stars,而 DeepSeek 选择 MIT 许可开源,目前已有 3K stars。
Github 地址:
https://github.com/MoonshotAI/kimi-k1.5
https://github.com/deepseek-ai/DeepSeek-R1
Kimi、DeepSeek,中门对狙?
DeepSeek-R1-Zero 路线的重点是呈现了新涌现:“aha moment”(顿悟时刻)。该模型在预训练之后完全没有经过任何监督学习,即没有使用任何其他思维链模型以及人类的输出。也就是说,从 DeepSeek-V3 基座直接进行强化学习,即可解锁 o1 级别的思维链能力。不过,R1 比 o1 的价格要便宜 30 倍。
这一点也“打脸”了 Meta。之前 Meta 在论文《Physics of Language Models》中认为,反思是必须“训练”的,而 o1 类模型面临的问题是得不到 pretrain 量级的反思推理。但 DeepSeek 证明了,纯 RL(Reinforcement Learning,强化学习)无SFT(Supervised Fine-Tuning,监督微调)的模型,在训练期间可以学会自发思考和反思。
DeepSeek-R1 引入了冷启动数据和多阶段训练流程,解决模型在可读性和语言混合方面的问题,同时进一步提升推理性能。具体包括:通过少量高质量的长 CoT 数据对基础模型进行微调,作为 RL 训练的起点;在冷启动基础上,应用大规模 RL 训练,专注于提升模型在推理密集型任务上的表现;通过拒绝采样生成新的训练数据,并结合其他领域的数据进行微调,进一步提升模型的泛化能力;在最终阶段,结合多种奖励信号和多样化的提示分布,对模型进行全面优化,使其在推理能力、有用性和安全性方面达到平衡。
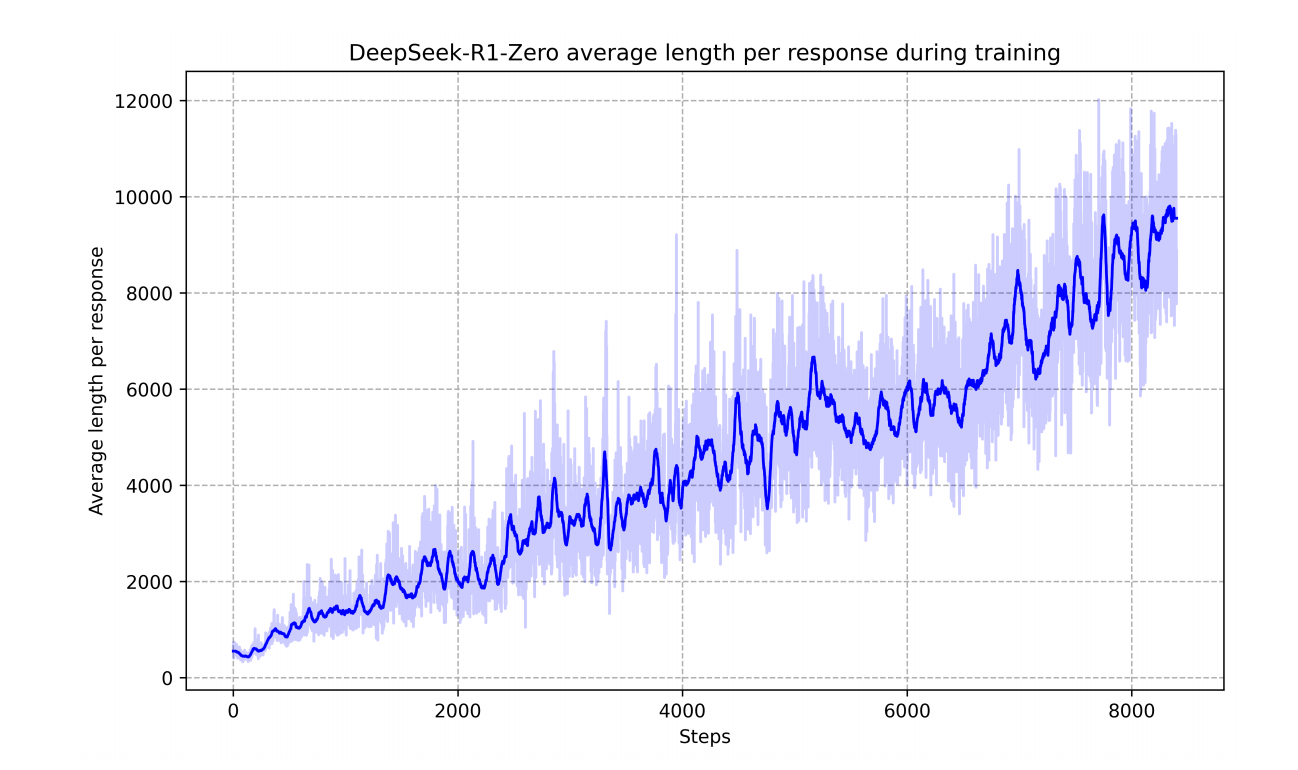
DeepSeek-R1-Zero 在训练集上的平均响应长度在强化学习(RL)过程中逐渐增加,自然地学会了通过增加思考时间来解决推理任务。
DeepSeek 还在 DeepSeek-R1 中引入了开发管线。此管线共包含两个强化学习阶段,旨在发现更佳推理模式并与人类偏好保持一致;以及两个监督微调阶段,以作为模型推理及非推理能力的种子。
此外,DeepSeek 还证明了,可以将较大模型的推理模式蒸馏成较小模型,而且与通过强化学习在小模型上发现的推理模式相比其性能更好。开源 DeepSeek-R1 及其 API 将使得研究界受益,以便未来蒸馏出质量更好的小体量模型。
使用 DeepSeek-R1 生成的推理数据,DeepSeek 对研究社区中广泛使用的几种密集模型进行了微调。评估结果表明,经过蒸馏的较小密集模型在基准测试中表现非常出色。现在,DeepSeek 已经向社区开源了基于 Qwen 2.5 和 Llama 3 模型家族的 1.5B、7B、8B、14B、32B 和 70B 等微调版本。由此获得的 DeepSeek-R1-Distill-Qwen-32B 模型在各类基准测试中的表现均优于 OpenAI-o1-mini,标志着密集模型的技术水平由此登上新的台阶。
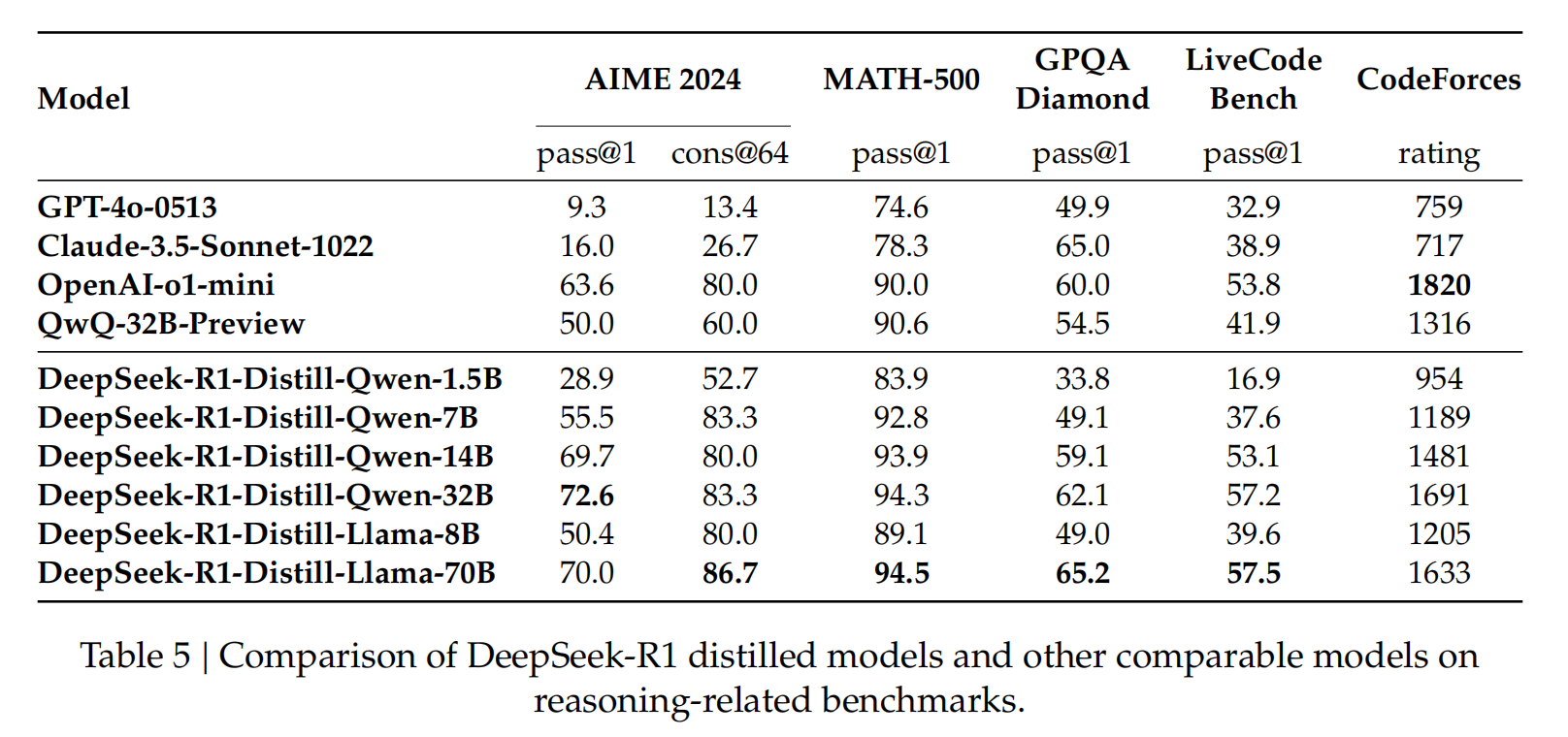
DeepSeek-R1 蒸馏模型与其他同类模型在推理相关基准测试中的比较
而对于 Kimi 的 k1.5,其技术重点与 R1-Zero 并不相似。Kimi K1.5 的技术重点在于通过长上下文扩展和改进的策略优化方法,结合多模态数据训练和长到短推理路径压缩技术,实现高效且强大的强化学习框架,以此提升大模型在复杂推理和多模态任务中的性能和效率。
将 RL 的上下文窗口扩展到 128k,模型能够处理更长的推理路径,从而提升性能。该方法背后的一个关键思想是,使用部分展开(partial rollouts)来提高训练效率——即通过重用大量先前的轨迹来采样新的轨迹,避免了从头开始重新生成新轨迹的成本。“上下文长度是通过 LLMs 持续扩展 RL 的一个关键维度。 ”
提出了基于长推理路径(Long-CoT)的强化学习公式,并采用在线镜像下降的变体进行稳健的策略优化。k1.5 提出了一种专门的长到短强化学习(Long2Short RL)方法,通过长度惩罚(Length Penalty)和最大轨迹长度限制,进一步优化短推理路径模型,此外通过采样策略(如课程学习和优先采样)优化训练过程,使模型更专注于困难问题。
简洁的框架。长上下文扩展与改进的策略优化方法相结合,为通过 LLMs 学习建立了一个简洁的 RL 框架。上下文长度的拓展让学习到的 CoTs 表现出规划、反思和修正的特性,增加上下文长度的效果增加了搜索步骤的数量。因此,k1.5 可以在不依赖更复杂技术(如蒙特卡洛树搜索、价值函数和过程奖励模型)的情况下实现强大的性能。
多模态能力。k1.5 在文本和视觉数据上联合训练,具有联合推理两种模态的能力。该模型数学能力出众,但由于主要支持 LaTeX 等格式的文本输入,依赖图形理解能力的部分几何图形题则难以应对。
此外,Kimi k1.5 还提出了一种混合部署框架,将训练和推理任务部署在同一硬件上,通过共享 GPU 资源提高资源利用率。利用 Kubernetes Sidecar 容器,实现训练和推理任务的动态切换。
对于 Kimi、DeepSeek 这次有意或无意的较量,知乎答主“ZHUI”如此总结:
DeepSeek 应该是最早走对 o1 路子的一家厂商,从 2024.11.20 发布 R1-lite 算起,到今天两个月。这两个月(可能更早)开始在 DeepSeek-V3 的路子上走进行。个人猜测,R1-lite-preview 应该是在 v2 的小模型基础上探索策略得到的模型,大概 11 月开始,v3 的模型训练好了,开始迭代 R1。
Qwen/QwQ 我倾向于路径是对的,如 DeepSeek Report 中,对比蒸馏与 RL 结果展示的,RL 结果与 QwQ 模型效果类似。
看起来,各家应该都在 11 月上旬、中旬的时候,o1 的训练诀窍成为了小圈子里面较为公开的秘密了。
RL 训练的 pipeline 基建,DeepSeek 应该是比较完善的,虽然报告中没有讲。kimi 1.5 中讲了一些他们的 infra,感觉还是这一块可能拖了他们一些后腿。
Kimi 1.5 的 report 有点赶工的嫌疑,内容组织的一般般。猜测可能提前得知 R1 的发布时间,赶在一起发 PR,目前看说明,还没上线。
虽然 kimi 讲了更多训练细节,如怎么限制生成长度的策略等,在原来的模型上修修补补,落了下乘。DeepSeek R1 从数据的角度解决绝对是更优雅的方案。
英伟达高级科学家 Jim Fan 也对两者进行了总结并表示,
Kimi 和 DeepSeek 的论文惊人地得出了相似的结论:
不需要复杂的蒙特卡洛树搜索(MCTS),只需将思考过程线性化,并进行传统的自回归预测;
不需要额外昂贵模型副本的价值函数;
不需要密集的奖励建模,尽可能依赖真实结果和最终答案。
而两者的不同之处在于:
DeepSeek 采用 AlphaZero 方法——完全通过 RL 进行引导,无需人类输入,即“冷启动”。而 Kimi 采用 AlphaGo Master 方法:通过提示工程生成的推理链(CoT)进行轻量级的监督微调(SFT)来预热。
DeepSeek 的模型权重采用 MIT 开源许可(展现了技术领导力!),而 Kimi 尚未发布模型。
Kimi 在多模态性能方面表现出色(令人惊叹!),例如在 MathVista 基准测试中,需要对几何图形和智力测试等进行视觉理解。
Kimi 的论文在系统设计方面提供了更多细节:包括 RL 基础设施、混合集群、代码沙盒、并行化策略;以及学习细节:长上下文、推理链压缩、课程学习、采样策略、测试用例生成等。
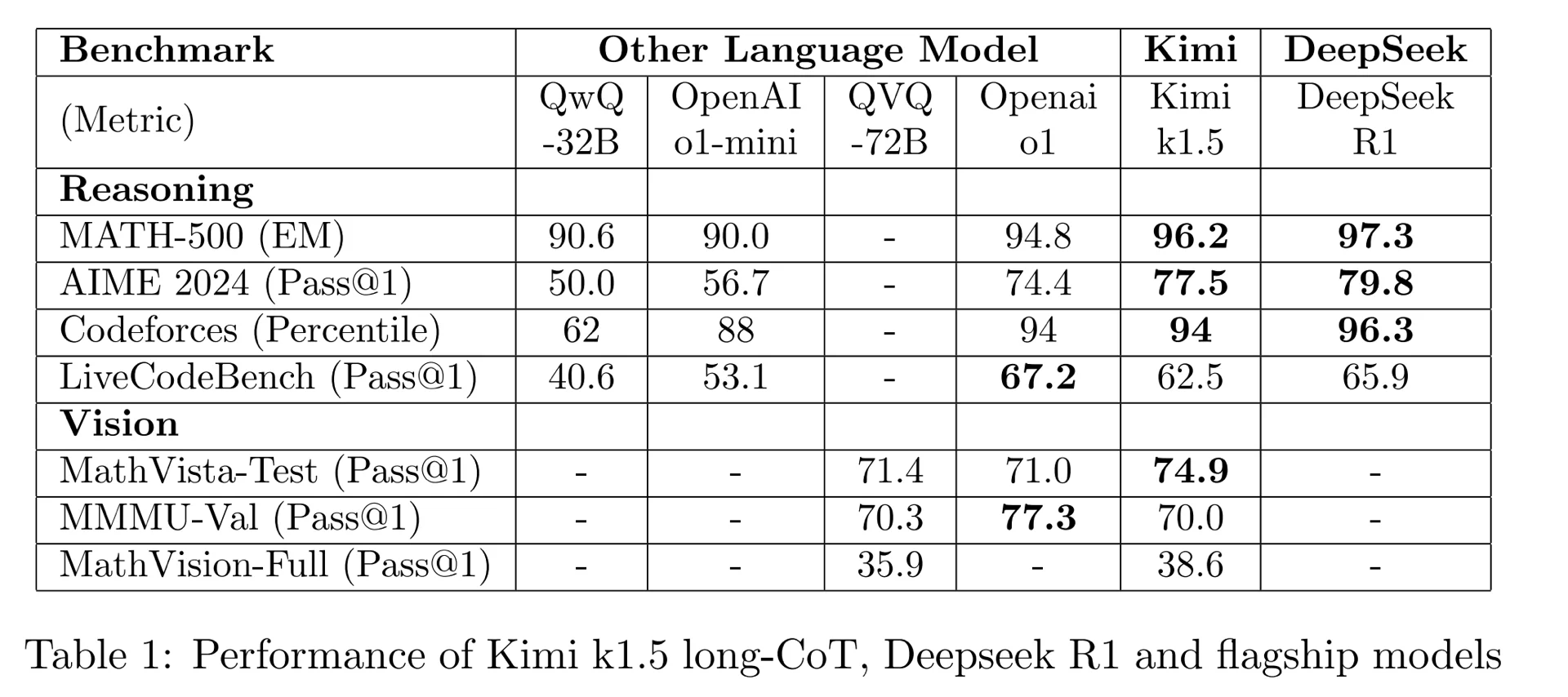
为方便对比,有网友把两篇论文的指标重新合在了一张表格上
不过正如网友所说,“idea 不难想到,因为实在太直观了,我 22 年都想到过,但是做成是另一回事情。”
“我被 R1 震惊到了”
显然,由于 DeepSeek 选择直接开源,其在全球社区里收获了更多的关注。
根据测试,在数学任务中,DeepSeek-R1 的表现与 OpenAI-o1-1217 相当,大幅超越了其他模型。在编程算法任务中,例如 LiveCodeBench 和 Codeforces,以推理为导向的模型在这些基准测试中占据主导地位,DeepSeek-R1 也展现出类似的趋势。在工程导向的编程任务中,OpenAI-o1-1217 在 Aider 上表现优于 DeepSeek-R1,但在 SWE Verified 上两者表现相当。
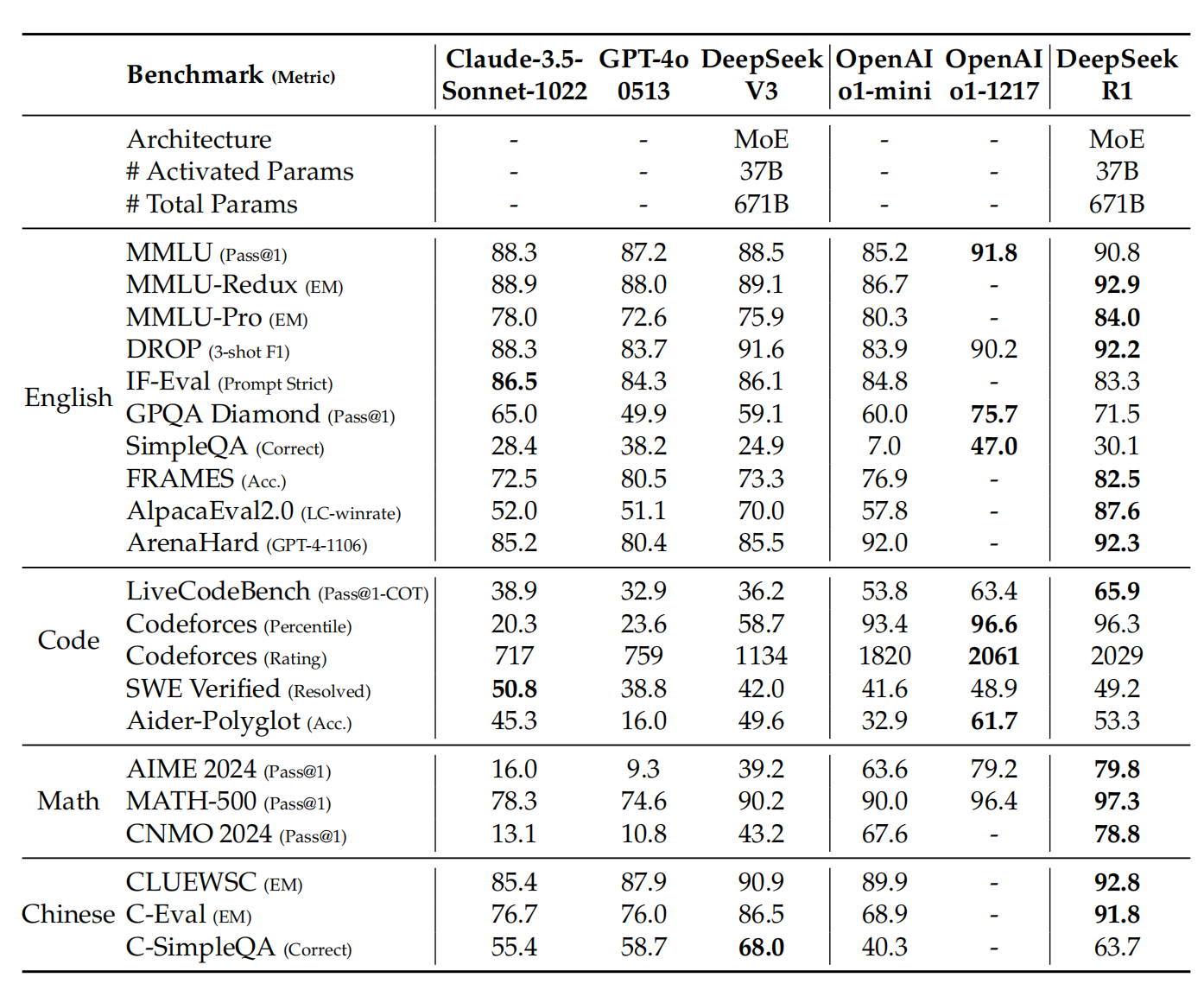
Jim Fan 表示,“它或许是第一个展示强化学习飞轮效应(RL flywheel)重大且持续增长的开源项目。”他还暗讽了一下 OpenAI:影响力可以通过“内部实现的通用人工智能(ASI)”或像“草莓计划”这样的神秘名称来实现;影响力也可以通过简单地公开原始算法和 Matplotlib 学习曲线来实现。
年仅 19 岁便获得博士学位的 StabilityAI 研究总监 Tanishq Mathew Abraham 表示,“这是迄今为止今年人工智能领域最重要的论文。”他还表示,“我很欣赏 DeepSeek 提供的失败案例,尤其是这些想法已经被广泛讨论用于实现 o1 风格模型。这在 AI 论文中非常罕见。”
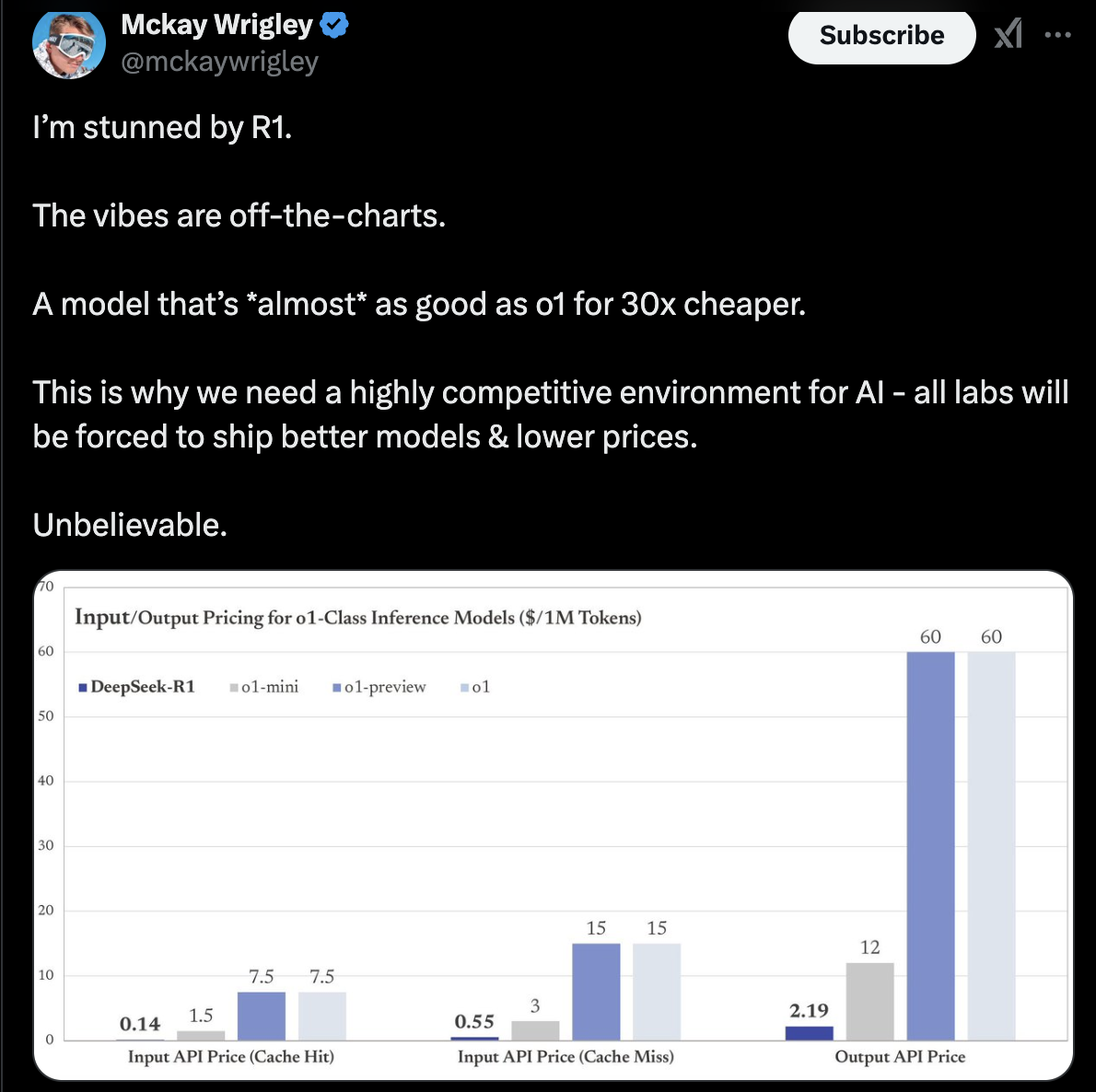
网友 Mckay Wrigley 表示,“我被 R1 震惊到了,它的表现简直爆表!这是一个几乎和 o1 一样好,但价格便宜 30 倍的模型。这就是为什么我们需要一个高度竞争的 AI 环境——所有实验室都会被迫推出更好但降低价格的模型。简直难以置信。”
还有一些开发者已经迫不及待地在本地测试和使用起来了 DeepSeek R1。
苹果机器学习研究员 Awni Hannun 在 2 块 M2 Ultra 芯片上运行 DeepSeek R1 671B 模型,表示“运行速度比阅读速度还快。它正在成为开源的 o1 模型,在家用消费级硬件上就能实现。”
然后,他向 DeepSeek R1 Distill Qwen 7B(4 位)提问了第一个数学难题。在 M4 Max 上使用 mlx-lm 大约 35 秒内计算出大约 3200 个 token。
网友 Matthew Berman 则评价:“DeepSeek R1 拥有我见过的最像人类的内心独白。它实际上非常可爱。”

参考链接:
https://mp.weixin.qq.com/s/BmOKGKjXP2tjmPyNdU0Hqg
https://www.zhihu.com/question/10080578443/answer/83321932961




