

改名 Meta 之后,Facebook 的元宇宙愿景正在一点点实现。这一次,Facebook 把目光投在了元宇宙社交上。
Meta 发布语音处理模型 XLS-R
近日,Meta 正式发布 XLS-R——一套用于各类语音任务的新型自监督模型。据悉,XLS-R 由海量公共数据训练而成(数据量是过去的十倍),能够将传统多语言模型的语言支持量增加两倍以上。目前,XLS-R 共支持 128 种语言。
Meta 认为,语音交流是人们最自然的一种交互形式。“随着语音技术的发展,我们已经能够通过对话同自己的设备及未来的虚拟世界直接互动,由此将虚拟体验与现实世界融为一体。”
这与扎克伯格此前宣称的“公司业务将以元宇宙优先”不谋而合。此前,扎克伯格曾概述了他建立“元世界”的计划:一个建立在我们自己的数字世界之上的数字世界,包括虚拟现实和增强现实。“我们相信元宇宙将会接替移动互联网”。
而 XLS-R 作为元宇宙社交中必不可少的一环,可以帮助母语不同的人在元宇宙无障碍对话。
值得一提的是,为了通过单一模型实现对多种语言的广泛语音理解能力,Meta 对 XLS-R 进行了微调,使其获得语音识别、语音翻译及语言识别等功能。据介绍,XLS-R 在 BABEL、CommonVoice 以及 VoxPopuli 语音识别基准测试,CoVoST-2 的外语到英文翻译基准测试,以及 VoxLingua107 语言识别基准测试中都取得了不错的成绩。
为了尽可能降低功能访问门槛,目前,Meta 与 Hugging Face 联手发布了模型本体,并通过 fairseq GitHub repo 全面开放。
XLS-R 工作原理
据介绍,XLS-R 在 wav2vec 2.0 训练集上接受了超过 43 万 6 千小时的公开语音录音训练,从而实现了对语音表达的自监督学习方法。这样的训练量已经达到去年发布的当时最强的模型 XLSR-53 的 10 倍。利用从会议记录到有声读物的多种语音数据来源,XLS-R 的语言支持范围扩展到 128 种,涵盖的语种量达到前代模型的近 2.5 倍。
作为 Meta 打造的有史以来最大模型,XLS-R 中包含超过 20 亿个参数,性能远高于其他同类模型。Meta 表示,事实证明,更多参数能够更充分地体现、数据集中的各类语种。此外,Meta 还发现,规模更大的模型在单一语言预训练方面的性能也同样优于其他较小模型。
Meta 在四种主要多语言语音识别测试中对 XLS-R 做出评估,发现它在 37 种语言上获得了超越以往模型的效能。具体测试场景为:BABEL 中选取 5 种语言,CommonVoice 中选取 10 种语言,MLS 中选取 8 种语言,以及 VoxPopuli 上选取 14 种语言。
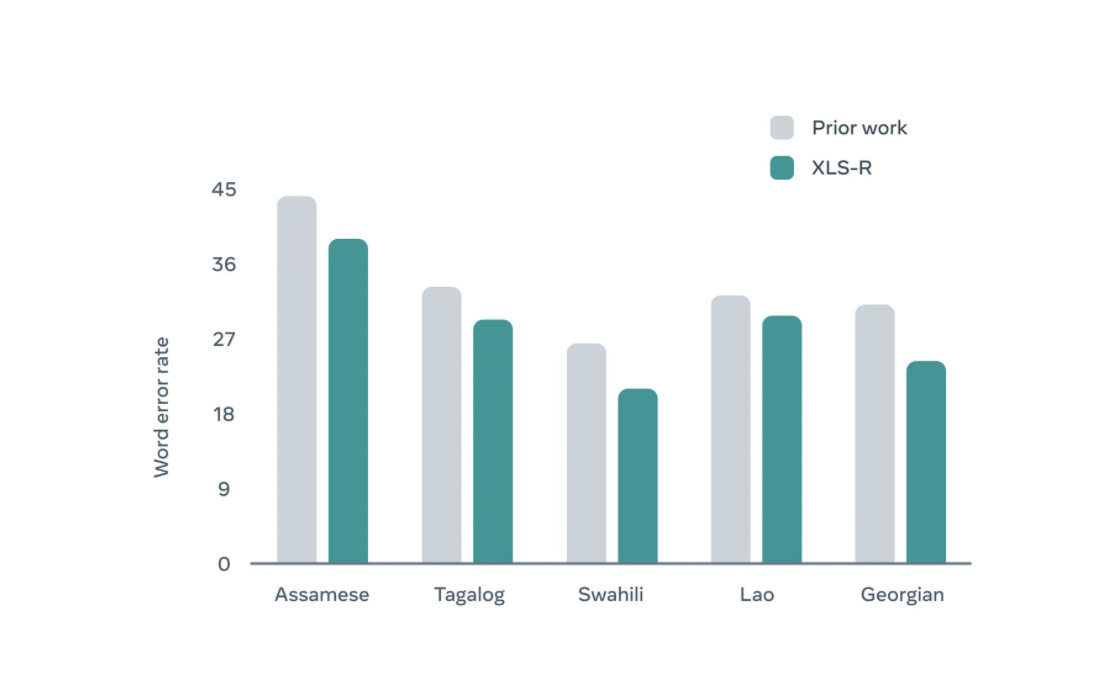
此外,Meta 还评估了语音翻译模型,即将录音资料直接翻译成另一种语言。为了打造一套能够执行多种任务的模型, Meta 同时在 CoVoST-2 基准测试的数个不同翻译方向上对 XLS-R 进行了微调,使其能够在英语与多达 21 种语言之间实现内容互译。
在使用 XLS-R 对英语以外的其他语言进行编码时,获得了显著的效能提升,这也是多语言语音表达领域的一次重大突破。据 Meta 介绍,XLS-R 在低资源语言学习中实现了显著改进,例如印尼语到英语的翻译,其中 BLEU 准确率平均翻了一番。BLEU 指标的提升是指模型给出的自动翻译结果与处理同一内容的人工翻译结果间重合度更高,代表着模型在改进口语翻译能力方面迈出了一大步。
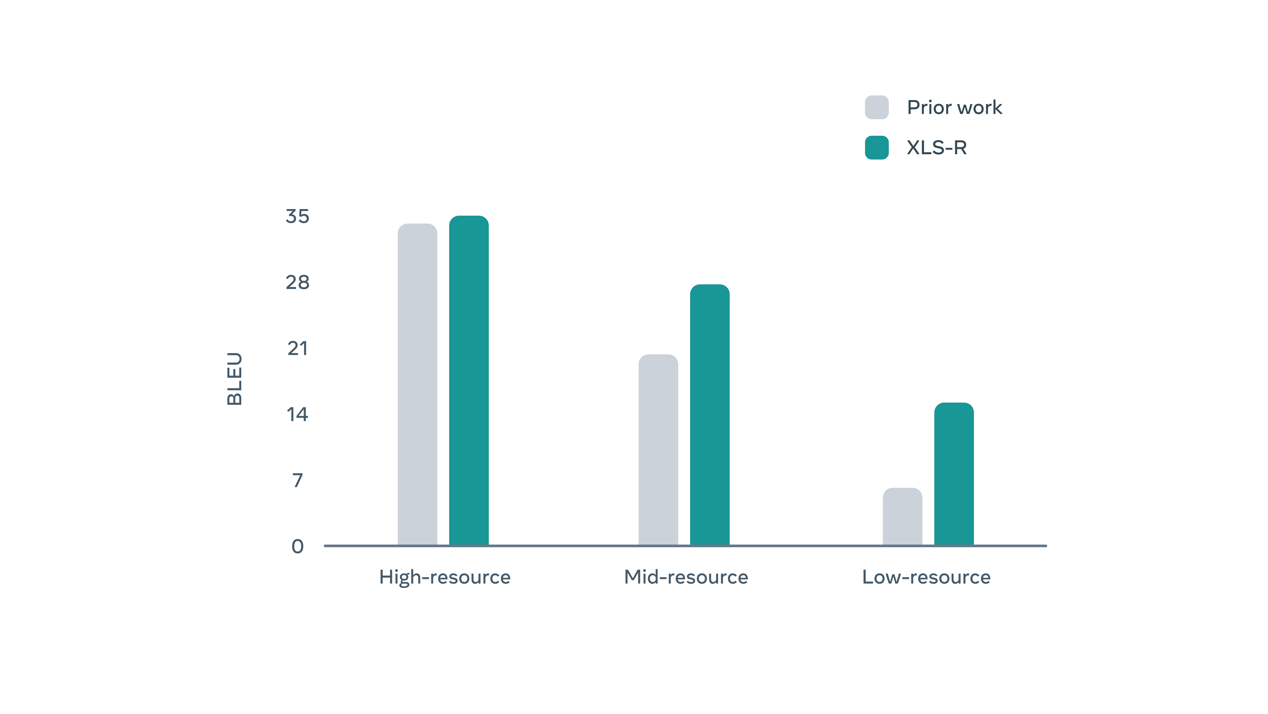
Meta 认为,XLS-R 证明扩大跨语言预训练规模可以进一步提高低资源语言的理解性能。它不仅提高了语音识别率,同时也将由外语到英语的语音翻译准确率提高了一倍以上。
“XLS-R 是我们朝着以单一模型理解多种不同语言(语音)目标迈出的重要一步,也代表着我们在利用公共数据推进多语言预训练方面做出的最大努力。我们坚信这是一条正确的探索方向,将让机器学习应用更好地理解所有人类语音、并促进后续研究,大大降低语音技术在全球范围内、特别是服务匮乏社群中的使用门槛。我们将不断开发新方法,通过低监督学习拓展模型的语言理解能力、逐步使其覆盖全球 7000 多种语言,实现算法的持续更新。”Meta 提到。

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论 1 条评论