
近日,多个开源社区纷纷抱怨,由于 AI 公司大规模抓取其代码托管、文档等公共资源,项目基础设施一度面临“近似 DDoS 级”访问压力,导致服务器频繁宕机或性能严重下降。SourceHut 创始人 Drew DeVault、GNOME、KDE、Inkscape、Fedora 等多个社区都先后发出声音,呼吁外界关注和正视这个问题。
LLM 爬虫“泛滥成灾”
三天前,开源代码托管平台 SourceHut 的创始人兼 CEO Drew DeVault 在其最新博文《Please stop externalizing your costs directly into my face》中,愤怒地描述了他近月来与 AI 模型爬虫的“交锋”经历:
每周我们都会经历数十次短暂的宕机,为了阻止这个数字继续上升,我每天要审查我们的防护措施好几次。即使我偶尔想抽空做点别的工作,也常常不得不在所有报警响起时立马放下手头事务,因为现有的防护措施又失效了。SourceHut 有好几个高优先级的任务已经因此被耽搁了数周甚至数月。
他指出,这些抓取工具并不遵守“robots.txt”协议,也不会尊重流量限制,甚至会访问极耗费系统资源的链接,比如 git blame、所有 Git 日志页面等。更棘手的是,这些流量来自数以万计的 IP 地址、随机化的 User-Agent 来“伪装”成普通用户流量,给识别与拦截带来了极大难度。
DeVault 在博文中坦言,近期他自己有 20%~100% 的工作时间都被迫花在与这些 LLM 爬虫的对抗上:“我们有好几个高优先级任务被耽搁了数周甚至数月,因为每次想回到正常的开发或管理上,都被服务器警报打断——我们的防御措施又失效了。”
同时,他指出,其社区的真实用户也会因此受到影响——“我们的防护策略无法可靠地区分真实用户与爬虫。”
开源界的集体困境
DeVault 特别提到,他的“系统管理员朋友们”其实都遭遇了相同的困扰,LLM 爬虫令所有开源项目措手不及。每次他跟朋友出去喝酒或吃饭,只要有几个系统管理员在场,大家很快就会开始抱怨这些爬虫,然后互相打听对方有没有找到什么“一劳永逸”的解决方案。
的确,其他开源社区也面临相似情况。最近 KDE 大量“伪装成 Microsoft Edge”浏览器的恶意流量或爬虫;GNOME 自去年 11 月以来就一直遇到问题,被迫实施临时流量限制,限制未登录用户查看合并请求和提交记录,大幅影响了真实的匿名访客。
GNOME 最终部署了一种名为“Anubis”的防御工具。该系统会向访问者提出一次 Proof-of-Work 挑战,要求浏览器先完成一定量的计算再呈交结果。只有闯关成功,才能访问网站。然而,这却难免波及普通用户。如果某个链接在聊天室或新闻社区里被频繁点击,系统可能瞬间提高难度,导致普通用户的等待时间可能长达数十秒乃至数分钟。
在 Mastodon 上,据 GNOME 管理员所分享的数据,在某个时段的 2.5 小时里,他们总共收到约 8.1 万次请求,仅有 3% 成功通过 Anubis 验证,其余 97% 被判定为爬虫。“虽然 Anubis 阻止了爬虫洪流,但也给正常用户带来不少困扰。”
不止 GNOME 与 KDE。Fedora 社区为保持其 Pagure 代码托管平台的稳定,不得已屏蔽了大量可疑 IP 段。由于某些 AI 爬虫来自同一国家的海量 IP,Fedora 一度只好封禁整个国家(如巴西)的访问请求,这种“一刀切”也引发社区用户对误伤的担忧。
Inkscape 项目上周也表示,大量 AI 爬虫使用“假冒浏览器 UA”或完全无视网站防爬协议。为了维持网站可用性,相关维护者被迫持续扩充“Prodigius”级别的黑名单;甚至 Frama 软件公司的 BigGrizzly 也曾被一个恶意的 LLM 爬虫淹没,并建立了一个包含 46 万个可疑 IP 的列表。
对此进行更全面的尝试是“ai.robots.txt”项目,这是一个与 AI 公司相关的网络爬虫的开放列表。他们提供了一个实施 Robots Exclusion Protocol 的 robots.txt 和一个 .htaccess 文件,该文件在收到列表中任何 AI 爬虫的请求时都会返回错误页面。
开源去中心化社群 Diaspora 的维护者 Dennis Schubert 几个月前吐槽了相似的经历,他说“查看流量日志让他非常生气”。
他当时提到,过去 60 天内 Diaspora 的网站与文档服务共收到 1130 万次请求,其中近 70% 来自 OpenAI 的 GPTBot、Amazonbot、ClaudeBot 等 AI 爬虫。
“它们不仅反复抓取同样的页面,还爬到维基的每条历史编辑记录、每次 diff 修改上——甚至每 6 小时就要来一遍!它们对 robots.txt 完全视而不见,频繁换 IP、伪造普通浏览器 UA,搞得服务器性能飙升、宕机频发。”
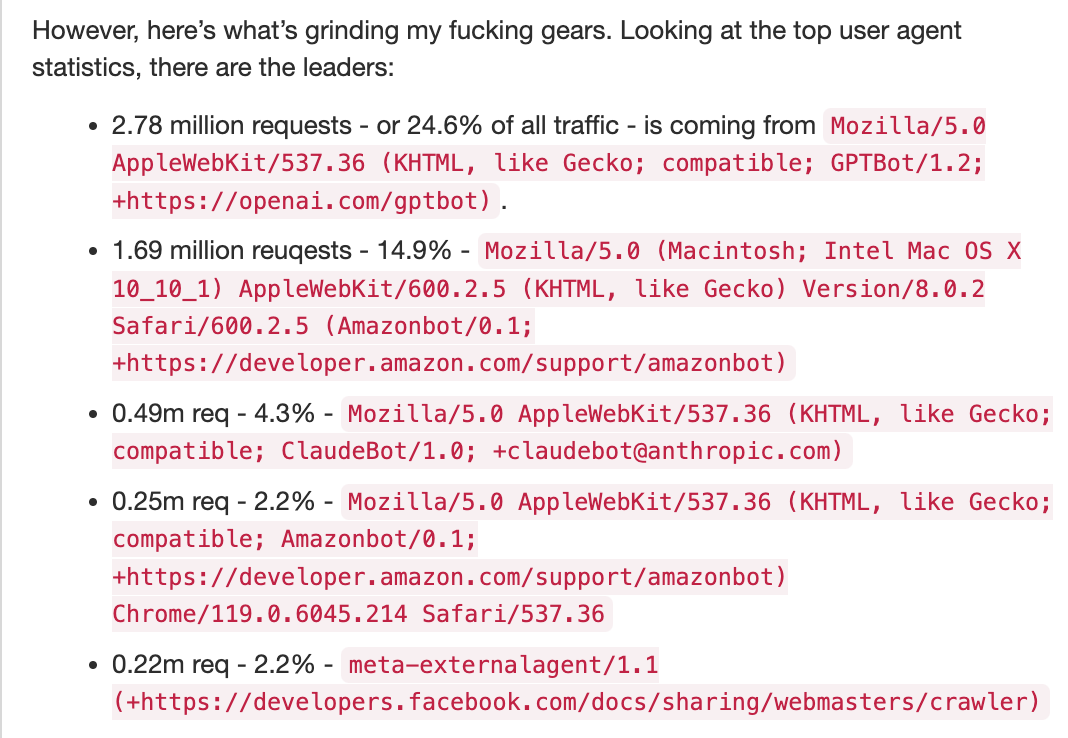
Schubert 指出,对比之下,Googlebot、Bingbot 等传统搜索引擎抓取非常克制,占比仅 0.14%,不会一遍又一遍地获取相同“毫无价值的内容”。他表示,这些 “不守规矩的 LLM 爬虫简直对整个互联网发动了 DDoS 攻击”,让运维人员疲惫不堪。
开源平台 Read the Docs 去年曾公开过这样一个数字,屏蔽所有 AI 爬虫后,其网站流量从每天 800GB 直接降至 200GB,节省了约 1500 美元 / 月的运营成本,“可见这类流量之巨”。
呼吁更多关注与自律
对 DeVault 来说,这已经不是第一次被迫替大机构或投机分子“背锅”。他在博文最后抨击了包括加密货币、谷歌团队、硅谷 AI 公司在内的多方,认为他们统统在把自己的成本“推给别人”,而这一切都在消耗社会公共资源,尤其是像 SourceHut 这样的中小型平台。
“我已经受够了,这些人一个劲儿地把成本转嫁到我脸上,让我疲于应对。要么去干点对社会有益的事,要么就滚远点,别来动我的服务器。在系统管理员们集体革命之前,拿你们那些数以百亿计的资金为公众做点好事吧。”DeVault 写道。
总的来看,开源社区似乎进退两难。一方面,开源文化强调开放协作,不可能对普通用户关闭文档、仓库访问;另一方面,社区往往没有雄厚的商业赞助来维持昂贵的带宽和服务器,现阶段也只能依赖 PoW、黑名单、甚至大范围封禁等手段来暂时缓解问题。
面对来势汹汹的 AI 爬虫浪潮,各大开源项目都在积极探索更高效、对普通用户更友好的解决方案。但无论如何,这都会是一个长期博弈的过程,涉及到行业规范、AI 爬虫自律以及社区共同行动。
参考链接:
https://thelibre.news/foss-infrastructure-is-under-attack-by-ai-companies/
https://drewdevault.com/2025/03/17/2025-03-17-Stop-externalizing-your-costs-on-me.html




